人脸伪造与检测中的对抗攻防综述
黄诗瑀1, 叶锋1,2, 黄添强1,2, 李伟1, 黄丽清1,2, 罗海峰1,2
1福建师范大学计算机与网络空间安全学院,福建 福州 350117
2数字福建大数据安全技术研究所,福建 福州 350117
Survey on adversarial attacks and defense of face forgery and detection
HUANG Shiyu1, YE Feng1,2, HUANG Tianqiang1,2, LI Wei1, HUANG Liqing1,2, LUO Haifeng1,2
1College of Computer and Cyber Security, Fujian Normal University, Fuzhou 350117, China
2Digital Fujian Institute of Big Data Security Technology, Fuzhou 350117, China
摘要:人脸伪造和检测是当前的研究热点。通过人脸伪造方法可以制作虚假人脸图像和视频,一些出于恶意目的而将名人虚假视频在社交网络上广泛传播,不仅侵犯了受害者的声誉,而且造成了不良的社会影响,因此需要开发对应的检测方法用于鉴别虚假视频。近年来,深度学习技术的发展与应用降低了人脸伪造与检测的难度。基于深度学习的人脸伪造方法能生成看起来更加真实的人脸,而基于深度学习的虚假人脸检测方法比传统方法具有更高的准确度。大量研究表明,深度学习模型容易受到对抗样本的影响而导致性能下降。近来在人脸伪造与检测的领域中,出现了一些利用对抗样本进行博弈的工作。原先的博弈模式变得更加复杂,伪造方和检测方在原先方法的基础上,都需要更多考虑对抗安全性。将深度学习方法和对抗样本相结合,是该研究领域未来的趋势。专注于对人脸伪造与检测中的对抗攻防这一领域进行综述。介绍人脸伪造与检测的概念以及目前主流的方法;回顾经典的对抗攻击和防御方法。阐述对抗攻击和防御方法在人脸伪造和检测上的应用,分析目前的研究趋势;总结对抗攻防对人脸伪造和检测带来的挑战,并讨论未来发展方向。
Abstract:Face forgery and detection has become a research hotspot.Face forgery methods can produce fake face images and videos.Some malicious videos, often targeting celebrities, are widely circulated on social networks, damaging the reputation of victims and causing significant social harm.As a result, it is crucial to develop effective detection methods to identify fake videos.In recent years, deep learning technology has made the task of face forgery and detection more accessible.Deep learning-based face forgery methods can generate highly realistic faces, while deep learning-based fake face detection methods demonstrate higher accuracy compared to traditional approaches.However, it has been shown that deep learning models are vulnerable to adversarial examples, which can lead to a degradation in performance.Consequently, games involving adversarial examples have emerged in the field of face forgery and detection, adding complexity to the original task.Both fakers and detectors now need to consider the adversarial security aspect of their methods.The combination of deep learning methods and adversarial examples is thus the future trend in this research field, particularly with a focus on adversarial attack and defense in face forgery and detection.The concept of face forgery and detection and the current mainstream methods were introduced.Classic adversarial attack and defense methods were reviewed.The application of adversarial attack and defense methods in face forgery and detection was described, and the current research trends were analyzed.Moreover, the challenges of adversarial attack and defense for face forgery and detection were summarized, and future development directions were discussed.
关键词: 深度伪造 ; 虚假人脸检测 ; 对抗样本 ; 社交媒体取证
中图分类号:TP393
文献标志码:A
DOI:10.11959/j.issn.2096−109x.2023049
0 引言
人脸伪造是指使用深度学习技术,如自动编码器(auto coder)和生成对抗网络(GAN, generative adversarial network),制作虚假人脸图像和视频。人脸视频伪造本质上属于人脸图像伪造,其做法是在视频中抽帧,逐帧对人脸进行伪造操作,再合并成视频。人脸伪造方法可分为4类:面部重现(face reenactment)、面部交换(face swap)、面部特征编辑(face attribute edit)和面部生成(face generate)。其中,面部重现是让目标人脸做出和源人脸(驱动人脸)一样的表情,常用工具包括Face2Face和NeuralTextures;面部交换是将目标人脸粘贴至源人物的面部区域,现有的工具包括FaceSwap、Deepfakes和Faceshifter;面部特征编辑是对目标人脸上的一个指定特征(如发色、年龄)做修改,常用的工具主要为条件控制的条件生成对抗网络(cGAN, conditional GAN)为基础的系列网络,如StarGAN、AttGAN(attribute GAN)和STGAN(selective transfer GAN);而面部生成包括伪造一张现实中不存在的人脸、对两张人脸进行特征融合以及进行人脸风格转换等,常见工具为StyleGAN系列网络。
上述人脸伪造方法在电影娱乐产业中得到广泛应用。然而它们被不法分子利用并制作出许多恶性的人脸伪造图片和视频。这些伪造信息通过社交媒体快速传播,引起了大众的信任危机。为了维护社会稳定,需要开发相应的虚假人脸检测方法。现有的基于深度学习的虚假人脸检测(简称深伪检测)方法是先使用VGG、ResNet、Xception、MobileNet、EfficientNet、Vision Transformer等网络提取分析伪造特征,再使用分类算法进行真假分类。而虚假人脸视频的检测本质上属于虚假人脸图像检测,其从待检测视频中抽取部分帧,进行帧间和帧内特征提取,再进行真伪二分类。
虚假人脸越来越逼真,检测手段越来越先进,人脸伪造和检测之间形成博弈,二者在博弈中不断改进。虽然深度学习在人脸伪造和检测中都获得了比传统方法更好的结果,但Szegedy等发现深度学习模型存在缺陷,向其测试数据中加入微小对抗噪声,便可形成对抗样本,进而误导模型。许多人工智能应用,如人脸识别和语音识别,容易受到对抗样本的干扰,人脸伪造和检测亦是如此。伪造方通过向虚假人脸中加入不可见的对抗噪声以干扰检测器(如图1所示),或者利用经过对抗性训练的GAN,直接生成不带有伪影的虚假人脸图像,误导检测器将虚假人脸分类为真实的人脸(如图2所示)。而对于反伪造方,与图3中使用检测器进行取证的“人脸伪造后的被动取证”不同,他们事先在干净图像中加入肉眼不可见的对抗噪声,使得图像经过 GAN 等方法伪造后产生严重失真,实现从根源上抵御人脸伪造,这种策略也称为“人脸伪造前的主动干预”,如图4所示。因此,对抗样本的存在,改变了以往人脸伪造和检测的博弈模式。
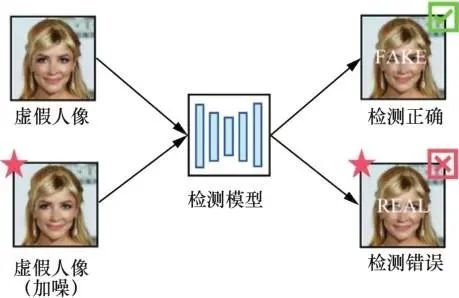
图1 针对假脸检测模型的噪声攻击
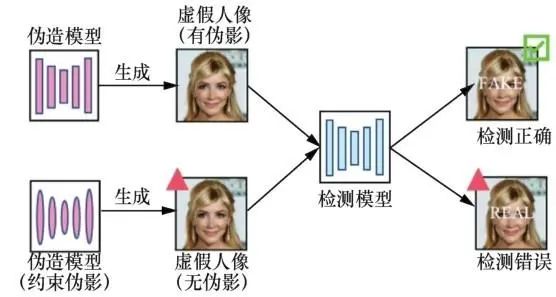
图2 针对假脸检测模型的去伪影攻击
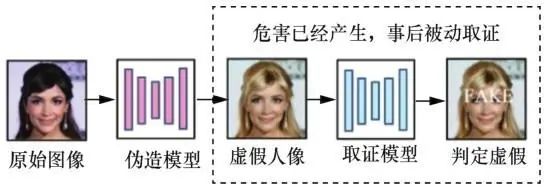
图3 人脸伪造后的被动取证
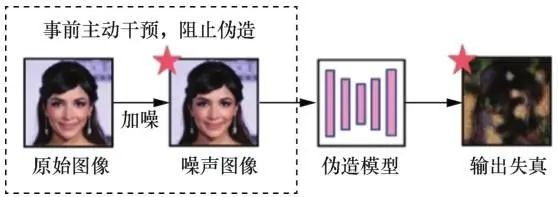
图4 人脸伪造前的主动干预
近年来,国内外关于对抗样本和虚假人脸检测的综述,对这两个领域的内容已经做出较为完备的阐述与总结。本文在前人工作的基础上,进一步补充阐述了对抗攻防方法在人脸伪造和检测中的应用。
1 对抗攻击和防御
1.1 对抗攻击
通常情况下,对抗攻击算法首先在图像中加入肉眼不可见的随机噪声,随后计算目标函数并求解梯度,最后利用梯度更新噪声分布,得到优化完毕的对抗样本。根据不同的攻击意图可将对抗攻击分为无目标攻击(untargeted attack)和有目标攻击(targeted attack)。无目标攻击根据被攻击模型的输出和真实类标签的距离,构建目标函数求得梯度,并在对抗噪声优化阶段进行梯度上升,让模型输出远离正确类别。而有目标攻击根据模型输出和目标类标签的距离,构建目标函数求得梯度,并在对抗噪声优化阶段进行梯度下降,让模型输出指定错误类别。相比有目标攻击,无目标攻击实现简单且成功率更高。
根据对抗样本训练阶段是否允许攻击者访问受害模型的信息,可将对抗攻击分为白盒攻击(white box attack)和黑盒攻击(black box attack)。由于攻击者能够获取模型的参数和结构信息,求得模型梯度并用于优化对抗噪声,因此白盒攻击能够达到较高的成功率。而在黑盒攻击中,模型对攻击者屏蔽了结构和参数信息,攻击者无法直接计算梯度用于优化对抗噪声,相比白盒攻击,黑盒攻击难度更大,且成功率更低。
白盒攻击最早可追溯至 Goodfellow 等提出的快速梯度符号法(FGSM,fast gradient sign method)。为了制造更强的对抗样本,Kurakin等对输入数据进行多次迭代优化,提出FGSM的迭代版本—— I-FGSM(iterative-FGSM)。基于迭代思想,后续出现了其他经典的白盒攻击算法,如基于决策边界的Deepfool算法、基于显著图的攻击方法(JSMA,jacobian-based saliency map attacks)、投影梯度下降(PGD,projected gradient descent)、可跨图像迁移的通用扰动(UAP,universal adversarial perturbation)攻击以及基于模型输出分数的(C&W,carlini&wagner)攻击。
在黑盒攻击中,攻击者无法直接求得梯度优化对抗噪声,需要使用两种梯度近似策略进行攻击:替代模型法和查询法。关于替代模型法,首先寻找和目标模型结构相似的替代模型,随后在替代模型上根据白盒攻击的做法,优化对抗噪声,最后将该对抗样本用于攻击黑盒模型。Goodfellow等发现对抗样本能在不同模型之间迁移,随后PaperNot等在现实场景下实施替代模型黑盒攻击。Liu等发现迁移攻击效果很大程度上取决于目标模型和替代模型决策边界的相似性。实际场景下二者难免存在差异,现有的方法从 3 个角度解决上述问题:① 优化I-FGSM;② 增强数据分布;③ 改进替代模型结构。而在查询法中,根据不同算法估计梯度方向,将估计得到的梯度用于优化对抗噪声。其中经典工作包括随机无梯度(RGF,random gradient-free)优化算法、自然进化策略(NES, natural evolution strategies)、Bandit查询算法和简易黑盒攻击(SimBA,simple black-box attack),后来有关查询法的工作主要围绕减少查询次数和提高估计准确性。
1.2 对抗防御
对抗防御旨在消除对抗样本的干扰,使深度神经网络(DNN,deep neural network)模型恢复正常输出。现有的对抗方法分为4 种:模型集成、梯度蒸馏、对抗训练和图像去噪。其中,模型集成会被各种可黑盒迁移的对抗样本攻破,梯度蒸馏已经被C&W攻击证明无效。目前用于深伪领域的主流方法是对抗训练和图像去噪。
对抗训练最初由 Goodfellow 等提出,以Mardy等为代表,其做法是在模型训练阶段,引入干净的数据和带有对抗样本的数据,使得模型训练过程中学习对抗样本的分布模式,以至于在分类对抗样本时具有鲁棒性。对抗训练近年来的优化工作包括对抗训练加速和提升模型泛化性。而图像去噪防御是在对抗样本输入目标模型前用图像处理方法去除对抗噪声。事实表明,降低或者提高图像分辨率均可破坏对抗噪声,如Dziugaite等使用图像压缩进行对抗防御,以及Mustafa等提出图像超分辨率防御方法。此外,还有一些工作使用图像重建方法破坏对抗噪声实现对抗防御。
2 人脸伪造中的对抗攻击和防御
本节从攻击伪造模型和防御伪造模型两个角度,对现有工作展开叙述。攻击伪造模型是指在干净人脸图像中添加对抗噪声,导致伪造模型输出的虚假人脸图像失真,或者和原图相似(也称图像锁定);防御伪造模型是指利用对抗防御方法,减轻对抗样本对伪造模型的影响,使得伪造模型重新输出视觉逼真的虚假人脸图像。
2.1 攻击伪造模型
本节根据4种常见的人脸伪造方法,利用对抗样本攻击伪造模型的工作。在介绍具体技术的同时,重点阐述这些工作的攻击特点,包括黑盒迁移性、对抗鲁棒性、数据迁移性和条件迁移性。关于攻击面部特征编辑的工作,本文还讨论其条件迁移性。接下来解释上述攻击特点。① 黑盒迁移性:对抗样本能够迁移至未知的黑盒伪造模型。② 对抗鲁棒性:对抗噪声不会被图像处理算法破坏,经过图像处理后依然保持攻击性。③ 数据迁移性:一次生成的对抗样本可以使多张图像上的人脸伪造产生失真。④ 条件迁移性:一张图像中的对抗样本可以攻击针对五官(眼睛、鼻子、嘴)的特征编辑。
2.1.1 攻击面部重现
面部重现是一种基于数据的伪造方法,经常用于伪造政治人物的演讲视频。这类方法需要根据驱动人脸和目标人脸来训练模型,因此在训练过程中,伪造模型会学习噪声分布模式,从而使得模型具备一定对抗鲁棒性,导致攻击产生的输出失真不明显,经常需要借助检测器才能辨别真伪。现有关于攻击面部重现的工作较少。Yang等利用PGD算法生成对抗样本,攻击基于GAN的面部重现方法 Mantra-Net。该工作考虑了对抗鲁棒性,但是没有考虑黑盒迁移性。Huang 等对此提出改进,利用替代模型进行黑盒迁移,并使用噪声生成器代替梯度优化算法,此外引入了一些辅助损失项,使得噪声攻击时更具有针对性,但是这项工作没有考虑对抗鲁棒性。不同于前者在 RGB域攻击,Wang等在Lab颜色空间的a、b通道中添加并优化噪声,这些噪声更加隐蔽且鲁棒,实验结果证明其能绕过较先进的防御方法 MagDR (mask-guided detection and reconstruction),实现对面部重现的攻击,但是这项工作没有考虑黑盒迁移性。
2.1.2 攻击面部交换
面部交换也是一种基于数据的伪造方法。面部交换模型也需要使用源人脸和目标人脸数据进行训练,训练过程间接地学习了对抗样本的分布模式,因此针对这类伪造的攻击也较为困难,大部分攻击产生的失真不明显。Aneja等提出针对人脸图像的有目标攻击(TAFIM, targeted attacks facial image manipulations)方法。TAFIM在通用噪声的基础上优化特定图像噪声,提高了攻击效率,同时在损失项中考虑了噪声的鲁棒性。实验表明,TAFIM能攻击SimSwap换脸,并在伪造图像上产生大面积蓝色失真。Dong等使用 FGSM 和 I-FGSM 攻击 deepfake。FGSM 数据迁移性较好,但是特定图像上攻击性能较差,I-FGSM与之相反。该方法只能产生小幅失真,需要检测器鉴别真假,同时这项工作没有考虑黑盒攻击。后来他们改进了之前的工作,提出可转移循环的对抗性 GAN (TCA-GAN,transferable cycle adversary GAN),用以生成对抗样本,并在伪造的人脸图像上产生肉眼可见的模糊失真。TCA-GAN中使用了两对生成器-鉴别器,分别用于生成噪声和去除噪声,以此模拟实际场景中可能存在的防御,提高噪声鲁棒性。此外还使用对抗正则化,提高黑盒泛化能力。
2.1.3 攻击面部特征编辑
面部特征编辑是一种基于模型的伪造方法。不同于面部重现与面部交换,该方法对社会舆论的危害较小,主要应用于美颜娱乐软件。同时模型在产生伪造人脸时无须重新训练,因此更容易受到对抗样本的攻击而导致输出失真。现有关于攻击人脸伪造的工作,多数为攻击面部特征编辑,本文根据其对抗攻击特点,大致将这些工作划分为4个阶段。
第一阶段多为白盒攻击,没有考虑攻击的黑盒迁移能力。该阶段以Ruiz 等和Yeh 等的工作为代表,他们最初尝试攻击以 cGAN为主干的面部特征编辑模型。前者使用 I-FGSM攻击StarGAN模型,同时利用扩谱干扰提高对抗噪声的鲁棒性,使得对抗噪声不会被图像压缩算法破坏。后者使用PGD算法攻击Pix2Pix和CycleGAN等模型,不仅考虑了图像失真攻击,还通过修改损失函数,使用图像锁定保护人脸图像免遭篡改。而裘昊轩等基于 APGD(auto PGD)算法提出DAPGD(dynamic auto PGD)算法,其核心在于动态设置学习率衰减的检查点,从而提高对抗样本的攻击性能。
现实场景下,大多数伪造模型是黑盒的,因此第一阶段的白盒攻击不具备应用意义。鉴于此,第二阶段主要围绕黑盒迁移性,改进第一阶段的工作,主要做法是先利用查询算法估计黑盒模型的大致梯度方向,再利用白盒优化算法得到对抗样本。Ruiz 等提出 LUP(leaking universal pertubations)黑盒查询攻击,该算法首先使用主成分分析法(PCA, principal component analysis)估计梯度的主要信息,再以此作为基础继续进行查询,查询结束后使用I-FGSM 得到对抗样本。Yeh 等提出 LaSGSA(limit-aware self-guiding gradient sliding attack)方法。该方法首先使用限制感知的RGF和梯度步长滑动机制估计梯度,再将估计结果用于 PGD 攻击。与上述基于查询的黑盒攻击不同,Lyu 等设计卷积网络,用于生成对抗水印,随后将带有水印的图像输入伪造模型,根据失真幅度设计损失函数,用以更新卷积网络的参数,多次重复以上步骤,从而实现迭代优化水印。此外,他们使用注意力机制确定人脸区域,使得水印优化过程集中在人脸区域。
虽然第二阶段工作成功攻击黑盒场景下的面部特征编辑,但是他们忽略了对抗样本的条件迁移性。为了改进这些不足,第三阶段综合考虑了对抗样本的黑盒迁移性和条件迁移性,该阶段的黑盒攻击主要是通过替代模型法实现的,替代模型法又可进一步分为单替代模型法和多替代模型加权法,前者只将单个白盒模型的梯度用于优化噪声,再将噪声迁移至黑盒模型;相比前者,后者将多个白盒模型梯度加权后再进行优化,能更有效地拟合大多数黑盒模型的梯度。Huang等的工作中,使用单替代模型法进行黑盒攻击,并将各条件域的联合损失作为优化目标,实现了条件迁移攻击。Huang等提出了跨模型的通用攻击水印(CMUA-watermark, cross models universal attack watermark),其通过加权联合损失实现数据迁移性和黑盒迁移性,同时通过多属性训练实现条件域之间迁移。Qiu 等提出了跨条件域和模型对抗攻击(CDMAA, cross-domain and model adversarial attack)。他们认为,各条件域之间具备梯度相似性,因此CDMAA依然通过加权联合损失实现条件域迁移;但是,不同模型之间的梯度是不相似的,不能直接通过加权联合损失进行迁移,因此他们使用多重梯度下降算法(MGDA, multiple gradient descent algorithm)进行梯度加权从而实现黑盒迁移。
随着图像去噪算法在该领域的应用,一些用于攻击伪造模型的对抗噪声失去了原有的攻击性能,因此第四阶段的工作主要考虑对抗噪声的鲁棒性。Dong 等提出的 TCA-GAN 不仅能够攻击面部交换,还能攻击 StarGAN和 AttGAN等面部特征编辑模型。他们通过损失函数加权实现黑盒迁移性和条件迁移性,还通过两个 GAN互相博弈实现噪声的鲁棒性。同时,Wang 等的工作实现了攻击面部特征编辑。不同于其他鲁棒性工作,他们考虑了对抗噪声如何抵御较先进MagDR图像重建算法,通过将图像RGB域上的噪声转换至Lab域以保证其鲁棒性,但是他们没有考虑黑盒攻击以及条件域之间的泛化。
2.1.4 攻击人脸风格转换
面部生成是一种基于模型的伪造方法,与面部特征编辑类似,其主要应用于娱乐,对社会的危害较小。现有关于攻击面部生成的工作较少。Aneja 等提出的 TAFIM 能够攻击人脸融合模型,使得输出的伪造图像带有大面积白色失真。而Qiu等提出的CDMAA能够攻击用于动漫人脸生成的 U-GAT-IT 模型,使得输出的伪造图像上带有大面积黑色失真。
2.2 防御伪造模型
对抗样本能够攻击伪造模型,使其输出大面积失真的伪造人脸,从而失去了舆论欺骗意义。上述方法看似解决了人脸伪造问题,然而对抗防御可以让伪造模型重新输出逼真的伪造人脸,对抵制伪造人脸带来了新挑战。现有的防御伪造模型方法包括对抗训练和图像去噪,其原理如图5和图6所示。
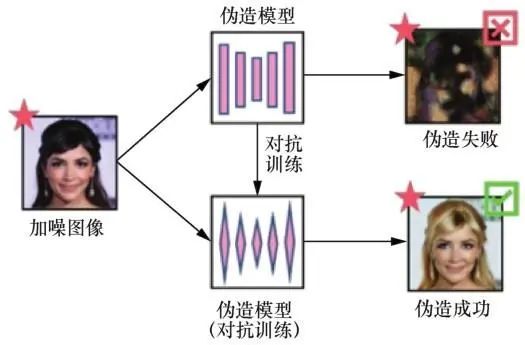
图5 伪造模型的防御(对抗训练)
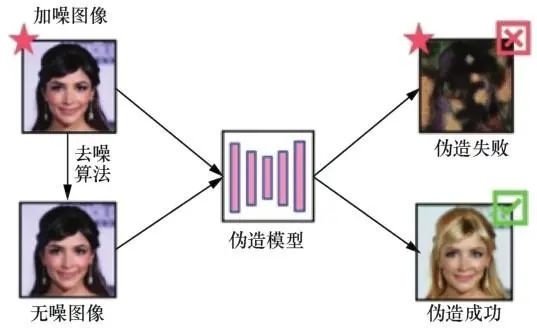
图6 伪造模型的防御(图像去噪)
在一些利用图像处理技术防御对抗样本的工作中,所提的防御方法未应用于人脸伪造模型的防御。对此,Chen等做了系统性的工作,将以上方法用于防御PGD和C&W攻击,使StarGAN输出视觉正常的伪造人脸,他们提出新的图像重建方法MagDR。首先训练掩模引导的一致性检测器和失真检测器,从伪造模型的输出图像判断输入图像是否添加了对抗水印。如果输入图像有水印,则利用所提的RecNet重建算法消除对抗噪声,并恢复所需的输出。在实验部分,将MagDR和之前的防御工作做对比,将图像去噪之后再进行伪造。结果表明,包括 MagDR 在内的一些方法重建的图像,经过 StarGAN伪造之后没有留下大面积明显伪影并输出视觉正常的人脸伪造图像。
而 Ruiz 等结合对抗训练和图像处理防御人脸伪造模型,将带有对抗噪声的图片对 GAN中的生成器和判别器进行对抗性训练,同时将图像进行高斯滤波去除对抗噪声,实验表明,经过防御的StarGAN对FGSM、I-FGSM和PGD这 3 种攻击算法具备鲁棒性,但是因为输入图像经过高斯滤波,输出的伪造图像质量有所降低。
2.3 小结
对抗攻防在人脸伪造中的研究现状概览如图7所示。可以看出,攻击伪造工作主要集中在攻击面部特征编辑,而攻击面部重现和面部交换的工作较少。因为面部特征编辑是基于模型的伪造方式,攻击难度小且成功率高。面部重现和面部交换是基于数据的伪造方式,需要根据目标人脸训练模型,然而训练过程中,模型学习了对抗样本的分布模式,导致模型能够抵御对抗干扰,使得攻击难度变大。现有的防御伪造工作主要是通过图像处理技术实现的,而对抗训练较少。用于人脸伪造的多半为GAN模型,相比一般的DNN模型,GAN模型较为复杂,其中包括生成器和鉴别器,导致基于模型的对抗训练方法难以部署。相比之下,图像处理防御兼容性强,无须考虑模型结构。
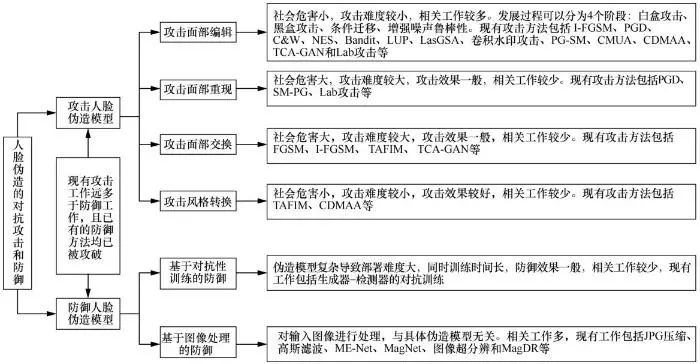
图7 对抗攻防在人脸伪造中的研究现状概览
3 虚假人脸检测中的对抗攻击和防御
本节从攻击检测模型和防御检测模型两个角度阐述现有工作。攻击检测模型是将对抗性虚假人脸图像输入检测模型,使其误判为真;而防御检测模型是利用对抗防御方法,减轻对抗性虚假人脸图像对检测模型的影响,使得检测模型正确辨别对抗性图像的真伪。
3.1 攻击检测模型
本节根据几种对抗攻击的特点,对现有工作展开叙述。这些特点包括黑盒迁移性、对抗隐蔽性、对抗鲁棒性以及数据迁移性。
3.1.1 黑盒迁移性
现实对抗场景中,社交平台上用于鉴别真伪图像的检测模型往往不会公开内部细节,因此无法根据白盒攻击方法,生成对抗样本并攻击检测模型。Hussain等先用基于NES的黑盒查询法对Xception和MesoNet进行黑盒梯度查询,随后使用I-FGSM算法生成对抗样本。然而,攻击对象为检测模型时,基于查询的黑盒攻击会受到查询次数的限制。现有大部分工作使用替代模型法进行黑盒攻击,具体做法是先在白盒模型上,利用白盒攻击算法生成对抗样本,再将对抗样本用于未知黑盒模型的攻击。其中有部分工作改进了迁移性能,如Li等使用多模型logit输出分数加权和作为优化目标,而 Jia 等提出在频率域添加对抗噪声。
3.1.2 对抗隐蔽性
成功攻击虚假人脸检测的前提是检测方没有发现图像中的对抗痕迹,直接将其输入检测模型,得到错误结果。如果对抗痕迹过于明显,那么会引起检测方的警觉,将采取防御手段消除对抗攻击带来的影响,从而导致攻击失败。在图像中加入噪声的对抗攻击,会在一定程度上导致图像失真或模糊。为了减少失真度,前期的工作使用目标函数优化方法,但是经过这些方法优化之后的噪声,依然是分布于全图的对抗噪声,存在冗余。Neekhara 等获取检测模型注意力区域,由于检测模型主要根据这些区域判定人脸图像真伪,所以这些区域中加入对抗噪声即可实现攻击检测模型。类似地,Liao等提出了多层语义特征关键区域选择(MLSKRS, multi-layers semantic key region selection),用于确定对抗关键区域。以上方法是在RGB图像域中添加噪声,而Jia等和Wang等分别将对抗噪声加入频率域和YCbCr颜色域以降低人眼可察觉程度。
除了在图像中减少冗余噪声,还有一些方法没有在图像中加噪,而是直接使用 GAN 生成无伪影的虚假人脸图像欺骗检测器。Li等提出一种攻击虚假人脸检测器的方法,不在图像中添加噪声,而是利用对抗优化算法,对 StyleGAN网络中的潜层向量进行梯度更新,使其生成的图像能够直接欺骗检测模型。而 Zhao 等和Liu等通过GAN生成器和鉴别器的对抗训练,消除虚假人脸图像中的伪造痕迹,以实现攻击检测器。
3.1.3 对抗鲁棒性
图像和视频上传至社交平台前会经过一次压缩,压缩有可能破坏图像中的对抗噪声,对抗噪声失效后,会导致虚假的人脸图像无法逃避检测。为了提高对抗噪声的鲁棒性,需要在用于生成对抗噪声的损失函数中考虑各种可能的图像变换,并构建联合损失以优化对抗噪声。现有工作中, Hussain 等考虑了加性高斯噪声、高斯模糊、图像上采样以及下采样;而Neekhara等则考虑了图像平移、加性高斯噪声以及图像压缩。此外,上述对抗性 GAN 生成图像的攻击方法,由于没有在虚假人脸图像加入对抗噪声,不会受到图像压缩方法的影响。
3.1.4 数据迁移性
在一些涉及虚假人脸视频的对抗攻击中,若对视频的每帧都加噪,则时间成本和计算开销高。为了更有效地制作对抗性虚假人脸视频,需要生成通用的噪声,迁移至视频的每一帧。现有工作多为制作对抗性虚假人脸图像,因此没有考虑数据迁移性。而 Hussain 等的工作中,涉及制作对抗性虚假视频,但是他们没有提出生成通用噪声的方法。作为改进,Neekhara等的工作中,使用联合数据分布的目标函数以生成通用噪声,提高制作对抗性虚假人脸视频的效率。
3.2 防御检测模型
虚假人脸检测模型容易受到各类干扰而导致真假分类错误。本节介绍一些用于增强检测器对抗鲁棒性的防御方法,根据防御方式可以划分为梯度正则、模型集成、图像处理和对抗性训练。
3.2.1 基于梯度正则的防御
在对抗样本生成阶段,对检测模型进行梯度屏蔽,使得攻击算法无法获得其梯度,从而生成噪声失败,现有的工作是:Gandhi 等使用Lipschitz正则化限制了检测器相对输入数据的梯度,但是这种梯度屏蔽方法对于提升检测模型的鲁棒性没有明显效果。此外,该方法不适用于各种模型架构,无法防御黑盒攻击,在实际场景中不适用。
3.2.2 基于模型集成的防御
该方法借鉴了机器学习中集成学习的思想,其原理如图8所示,每一种虚假人脸检测方法,都有其独特的优势。利用这一点,Khan等集成了VGG16、InceptionV3、Xception构建集成分类器,但是他们并没有在对抗样本上测试准确度,只是在DFDC和TIMIT数据集上进行评估,证明集成模型的分类准确性高于各集成部分。而Dutta 等提出 EnsembleDet 算法,集成Xception和MesoNet模型以抵御FGSM和I-FGSM在 Face2Face上的反取证攻击。上述集成模型的防御方法容易被可模型间黑盒迁移的对抗攻击所攻破,因此 Hooda 等集成了多个基于频谱的虚假人脸分类模型,并对各集成模型执行梯度正交化,从而降低对抗样本在这些模型之间的迁移性。
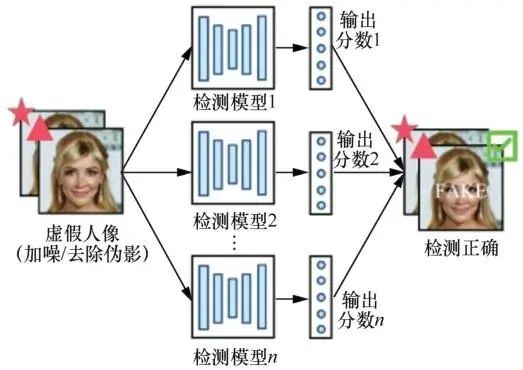
图8 假脸检测模型的防御(模型集成)
3.2.3 基于图像处理的防御
添加至图像中的细微噪声,会因各种图像处理方法而遭到破坏,因此可以利用这些方法防御检测模型,其原理如图9所示。基于此,Gandhi等使用深度图像先验(DIP,deep image prior)进行对抗防御。他们在数据输入分类器之前对其进行预处理来消除噪声。但是其迭代6 000次后才能达到最优精度,处理耗时较长。Luo 等对此提出改进,使用双边滤波图像处理方法,将对抗性虚假人脸图像去噪后再放入检测器进行分类。
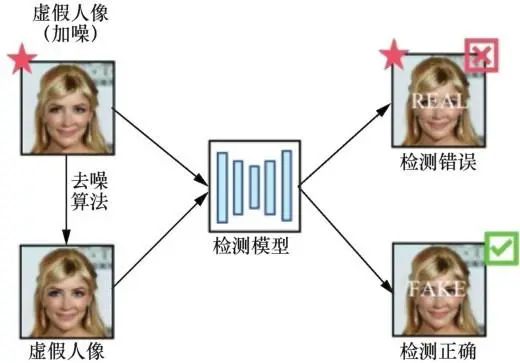
图9 假脸检测模型的防御(图像处理)
3.2.4 基于对抗训练的防御
对抗训练是让检测模型在各种对抗性数据上训练分类,从而提高其鲁棒性和泛化性,其原理如图10所示。如果只用一种对抗数据训练检测模型,那么模型可能无法防御其他类型的对抗数据。鉴于此,Luo等提出联合对抗训练,将PGD、I-FGSM和FGSM这3种对抗攻击算法所生成的对抗性图像引入Xception的训练过程,使模型鲁棒性得到提升。

图10 假脸检测模型的防御(对抗训练)
上述基于图像处理的防御方法,虽然模型结构独立且简单易用,但是会降低图像质量。而一些人脸取证方法需要根据 GAN 伪影来判别图像真伪,图像质量较低会导致这些伪影消失,从而引起检测器判别错误。此外,经过社交媒体平台压缩处理后的虚假人脸图像,也会带来这些问题。鉴于此,Wang等在检测模型的训练阶段,引入加性对抗样本和高斯对抗样本,使检测模型学习伪影以外的其他伪造特征,在面对低分辨率的伪造图像时,也能表现良好。
一些检测模型容易在特定的伪造方法上过拟合,在未知方法生成的虚假人脸上检测效果不佳,鉴于此,Chen 等使用伪造区域以及混合参数约束GAN,并生成指定类型的虚假人脸图像。随后将这些虚假人脸图像作为训练数据,让检测模型学习更一般的伪造特征,从而提高其泛化性。Jeong等也利用对抗性训练增强模型鲁棒性,他们指出,若检测方法考虑GAN的频率域伪影,虽然有利于提高检测模型在特定伪造方法上的性能,但是泛化性会有所降低,而若只考虑一般性特征,又会导致特定的伪造方法上效果不佳,因此提出利用 GAN 循序渐进地生成带有频率域扰动的虚假人脸,用其作为训练数据,使检测模型先学习频域率伪影而后学习一般性特征,提高检测模型的特异性能和一般性能。
3.3 小结
攻击虚假人脸检测模型研究工作的概览如表1所示。总体来看,现有的攻击工作主要解决4个方面的问题:提高对抗样本的黑盒迁移性、隐蔽性、鲁棒性以及数据迁移性。黑盒迁移主要通过替代模型迁移法实现,该方法有一定效果,但是其取决于模型之间的结构相似性。对抗样本的鲁棒性和隐蔽性是一对互斥的属性,鲁棒性越高,对抗强度也越高,导致对抗样本隐蔽性降低。目前的主要解决方法是目标函数优化和对抗性GAN。前者通过目标函数中的平衡因子控制优化偏好,但其本质上无法同时提升鲁棒性和隐蔽性,而后者可以较好地解决上述问题,但是需要额外的训练成本。此外,图像核心区域和其他域中加噪是一种成本相对低廉且有效的攻击方式,但是前者效果取决于注意力区域确定算法的精确度,而后者在黑盒攻击时效果一般。
防御虚假人脸检测模型研究工作的概览如表2所示。基于梯度正则的防御限制多而不能投入实际使用,具备实用意义的包括基于模型集成的防御、基于图像处理的防御和基于对抗训练的防御。基于模型集成的防御和基于图像处理的防御均属于使用较为灵活的防御方式,可以不用修改模型细节,但是它们都存在安全漏洞,基于模型集成的防御会被可迁移的对抗样本攻破,导致投票后选出错误类别,而基于图像处理的防御无法防御GAN痕迹抹除攻击。基于对抗训练的防御可以通过训练阶段学习数据分布从而防御多种类型的攻击,是相对而言最全面的取证防御策略,但是其存在训练数据处理成本较高的问题。
4 结束语
随着社交媒体的快速发展,人脸伪造带来的舆论安全问题日益突出,对虚假人脸进行鉴别和防范是当下的研究热点。对抗样本的应用改变了原有的伪造和取证模式,使得二者之间的博弈充满更多干扰因素。本文从人脸伪造和虚假人脸检测两个方面出发,展示了近年来对抗样本在该领域的研究进展与应用。关于人脸伪造方面,现有的对抗攻击多用于破坏舆论影响较小的人脸特征编辑,针对危害严重的人脸交换和面部重现,攻击效果较为一般。同时,一些先进对抗防御方法能够让伪造模型抵御对抗样本的干扰,重新输出逼真的伪造人脸。至于虚拟人脸检测方面,现有检测模型大多是面向特定场景的虚假人脸检测,在特定数据上的检测效果良好,但是其容易受到对抗样本的威胁,在噪声数据上效果不佳。此外,近来扩散模型[105-106]的应用使得AI生成的图像更加自然与真实,导致检测模型更难发现虚假图像中存在的瑕疵。总体来看,现阶段和虚假人脸的斗争形势依然严峻。为了解决上述问题,未来反伪造的工作可从以下角度考虑。
作者简介
黄诗瑀(1999-),男,福建厦门人,福建师范大学硕士生,主要研究方向为对抗性深度学习和数字媒体取证 。
叶锋(1978-),男,福建福州人,博士,福建师范大学副教授,主要研究方向为计算机视觉和视频图像编码 。
黄添强(1971-),男,福建莆田人,博士,福建师范大学教授、博士生导师,主要研究方向为机器学习安全和数字媒体取证 。
李伟(1997-),男,湖北十堰人,福建师范大学硕士生,主要研究方向为对抗性深度学习和数字媒体取证 。
黄丽清(1991-),女,福建莆田人,博士,福建师范大学讲师,主要研究方向为视频图像超分辨、去模糊处理和数字媒体取证 。
罗海峰(1990-),男,福建龙岩人,博士,福建师范大学讲师,主要研究方向为三维点云数据处理 。
声明:本文来自网络与信息安全学报,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
