0x00 介绍
网络爬虫,常又被称呼为Spider,网络机器人,主要模拟网络交互协议,长时间,大规模的获取目标数据。
普通爬虫会从网站的一个链接开始,不断收集网页资源,同时不断延伸抓取新获取的URL以及相应的资源。在对抓取目标内容结构分析的基础上,还会有目的性更强的聚焦型爬虫。爬虫对网站的抓取,最直接的影响就是增加服务器负载,影响正常业务的使用。但是仅仅限制爬虫的抓取频次是远远不够的。更重要的是对网站资源的保护,比如房产类信息中的小区名称、户型、建造年代、房型图、视频、面积、总价、单价等。同样的,在58招聘,黄页,二手车等业务线中,也存在着大量可用资源。更有甚者,利用业务逻辑漏洞或系统漏洞,爬虫也可大量获取平台内用户、商户信息,平台信息,其间不乏敏感数据,从而导致涉及信息泄露的各种群体及法律相关事件。0x01 搜索引擎
在网络中实际上也会存在大量的如Google,百度,360,微软Bing等搜索引擎的爬虫,一般这些搜索引擎都会对请求的浏览器UA进行定义,如百度PC端:PC UA:
Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)众所周知,浏览器信息都可以被伪造和篡改,所以单凭UA头信息来识别是不够的,反查HOST是识别搜索引擎的一种方法,但由于一些搜索引擎无法查明HOST,所以单一的识别方法并不十分有效。行为类的判别方法或许将更加重要。Robots协议这里顺便提一句Robots协议,Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol)。即使是正规的搜索引擎的爬虫,也可能对一些网站造成负载压力,或网站并不期望搜索引擎抓取一些页面,这时Robots协议就会起到作用了。文件“Robots.txt”将告诉不同的爬虫能访问的页面和禁止访问的页面,但是这个协议因为不强制爬虫遵守,而起不到防止爬虫的功能。0x02 一些典型的爬取手段
在了解基本的爬取手段前,我们来看看,目前网络中,哪些人是爬虫的生产者(或搬运工)。
我们先来对他们进行一下分类:Ø 学生,初级兴趣爱好者,初级爬虫程序员,数据分析师Ø 数据公司Ø 商业对手Ø 失控的爬虫和搜索引擎一些爱好者或者初级爬虫程序员,可能会通过网络搜集可用的脚本或者框架,其中python无疑是用的最多最广的,并且诞生了很多优秀的库和框架,如scrapy、BeautifulSoup 、pyquery、Mechanize等。网络上也存在着大量的数据公司,他们提供数据交易平台,用户可以购买定制数据,定制爬虫等。 商业竞争对手也会互相抓取对方数据,获取对方平台资源或为己用,或用于进行商业数据分析,相信这里的爬虫工程师已不再是搬运工的水平,他们有着明确的目的性和专业技能。
商业竞争对手也会互相抓取对方数据,获取对方平台资源或为己用,或用于进行商业数据分析,相信这里的爬虫工程师已不再是搬运工的水平,他们有着明确的目的性和专业技能。
0x03 反抓取常用的对抗方法
针对一些典型的爬取方法,自然会有一些基本的对抗方法,下面简单描述一下常用的反抓取手段:
IP最容易想到的就是针对IP的频率类或次数累积限制,但是针对抓取的特点,可以进一步进行细分,如结合时段,城市,网站页面类型,访问间隔,跨度,以及一些协议参数的变化情况等。浏览器检测对浏览器描述信息的检测是最基础的,在此基础上,可以进一步针对浏览器特性进行检查,基于浏览器的 UserAgent 字段描述的浏览器品牌、版本型号信息,对js运行时各个原生对象的属性及方法进行检验,观察其特征是否符合该版本的浏览器所应具备的特征,如Plugin,language,webgl,hairline等。网络协议参数检测进行基本的参数检测,如cookie,refer是否为空,是否合法,refer是否正确等。同时需要结合用户终端进行判断,如区分WEB,APP,移动平板;以及入口应用的特性进行判断,如主站,微信小程序,QQ及其他入口渠道等。验证码验证码产品提供多种人机识别方式,包括传统字符验证码,滑动拼图验证码,点选验证码,短信验证码,语音验证码等,以及结合生物特征的用户鼠标、触屏(移动端)等行为的行为验证技术。设备指纹APP设备指纹SDK,用户设备环境检测,如是否为模拟器,是否ROOT等;M端,PC端设备指纹JS环境检测等。服务端检测请求设备指纹是否合法。APP,M,PC端设备标记,保证设备唯一性的基础上进行如计数统计、行为分析等。WEB端JS埋点,JS网页加密,JS代码混淆等;Ajax/Fetch异步请求,Noscript标签的结合使用;CSS字体库等渲染,FONT-FACE拼凑式,BACKGROUND拼凑式,字符穿插式,伪元素隐蔽式,元素定位覆盖模式,IFRAME异步加载,Flash、图片或者pdf来呈现网站内容等;假链接,如在网页多处放几个一个像素的随机图片名假链;网页多处放几个随机不可见的假链;网页多处放几个随机的前景色和背景色相同的假链;网页多处放随机的位置超出屏幕的假链。因为数据平台定向抓取会分析网站结构,所以定期更改模板算一个应对方法,其余还有例如动态变换html标签,网页使用压缩算法输出内容,网页内容不定时自动截断等;假数据,返回假数据,实际在防守的同时对抓取方的一种进攻,对抓取方恨之入骨可采用此方法,问题是可能带来误伤,或者当抓取方发现被无情欺骗时,激起对方的愤怒进而升级抓取手段,甚至蓄意的破坏。当然针对竞品公司,应该予以无情的打击。行为分析通过爬虫与正常用户的一些行为差别进行的分析,如:对localStorage的访问,一般爬虫不存储localStorage数据,所以每次会访问;正常用户访问会在较短时间里完成某一时间周期的总请求数的绝大部分,映射到总用户上,确定的一段时间里,正常用户访问的总页数会在某个量级时开始骤减;识别通过修改参数如ID等的遍历行为。API防刷其实网络数据的交互都是通过API实现的,那么针对API接口的一些防护措施也能有效的控制爬虫,比如同IP/指纹对API接口频率调用设置阈值;使用接口加密服务,多套算法随机使用,算法周期更新等;根据API接口的深度,在触达路径进行数据埋点,识别请求路径等。账户一些网站信息必须用户登录后才可访问,这样反抓取除了通用方法外,还可以结合账户维度制定一些策略,比如同账户访问次数、频率限制;同账户多设备限制;同账户次数累积;同账户多浏览器访问;同账户访问城市切换,访问多业务线等。安全画像安全画像是58信息安全的一项重要服务,58自主研发的基于大数据的威胁情报系统,该服务是一个分析型安全防控管理系统,可基于风控系统实现统一的信息安全风控管理,帮助业务方实现事前的情报预警,事中的风险识别,事后的案件追溯,并与第三方数据有效集成,最终帮助业务线实现精准风险打击和智慧运营的效果。在反抓取对抗中,我们也使用了IP类,设备类,账号类,手机号类等各种画像标签,效果显著。0x04 58反抓取系统概要介绍
58反抓取SCF服务,为各业务线提供反抓取能力,接入成本低,时间短,目前日均处理接近10亿次请求,系统处理能力平日在每秒1W次左右,系统服务处理时间为单次0.5ms。目前已基本覆盖58房产、招聘、黄页、二手车;赶集房产、招聘;安居客新房、二手房等各大业务线。
58反抓取系统示意图: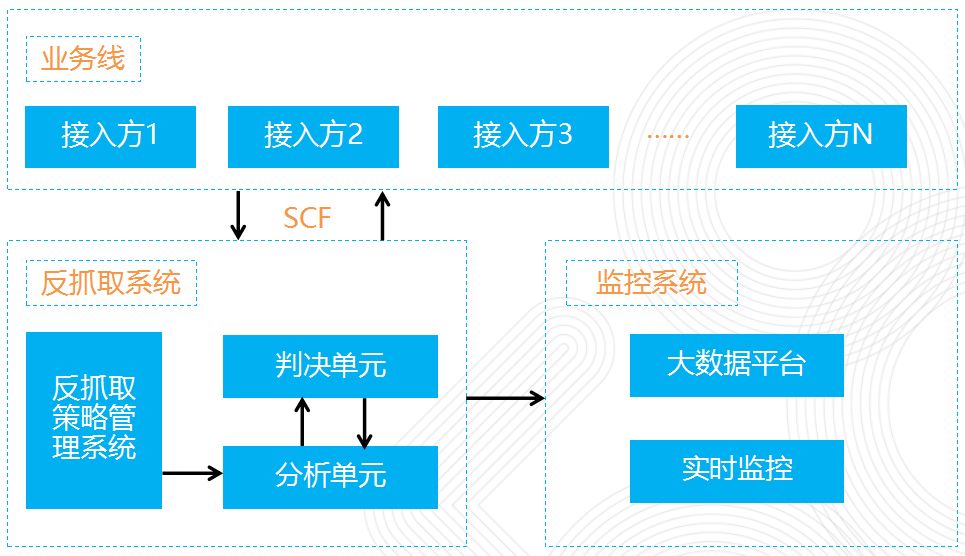 各接入方通过SCF服务接入反抓取系统;策略管理系统为各接入方配置策略集;分析单元执行策略集,并将命中目标送至判决单元进行后续处理;通过实时监控和大数据平台进行数据分析。
各接入方通过SCF服务接入反抓取系统;策略管理系统为各接入方配置策略集;分析单元执行策略集,并将命中目标送至判决单元进行后续处理;通过实时监控和大数据平台进行数据分析。
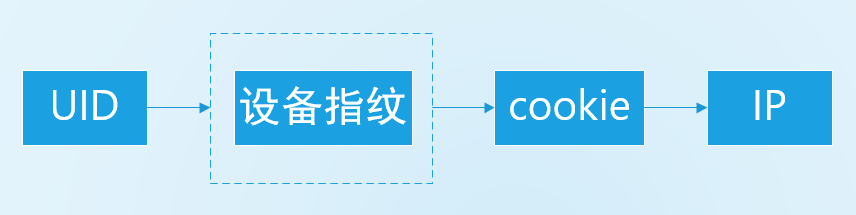
风险的处罚,处罚的数据维度包括UID,cookie,IP,设备指纹等:
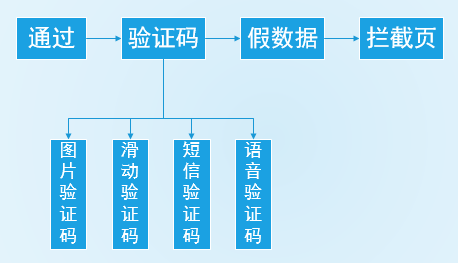
处罚的拦截方式包含通过,验证码(图片验证码、滑动验证码、短信验证码、语音验证码),返回假数据,拦截页中断操作等。
0x05 反抓取流量分析平台介绍
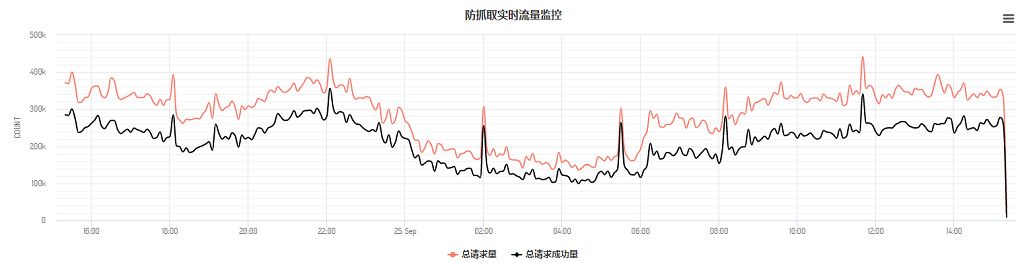
反抓取信息的重要来源,在于对流量的判断,包括流量变化,协议特征等。通过对流量变化趋势,机器特征的识别和聚类,往往可以发现现存问题,并且可以通过对个别业务线的风险识别,进而对其他业务线进行预警,达到态势感知的效果。
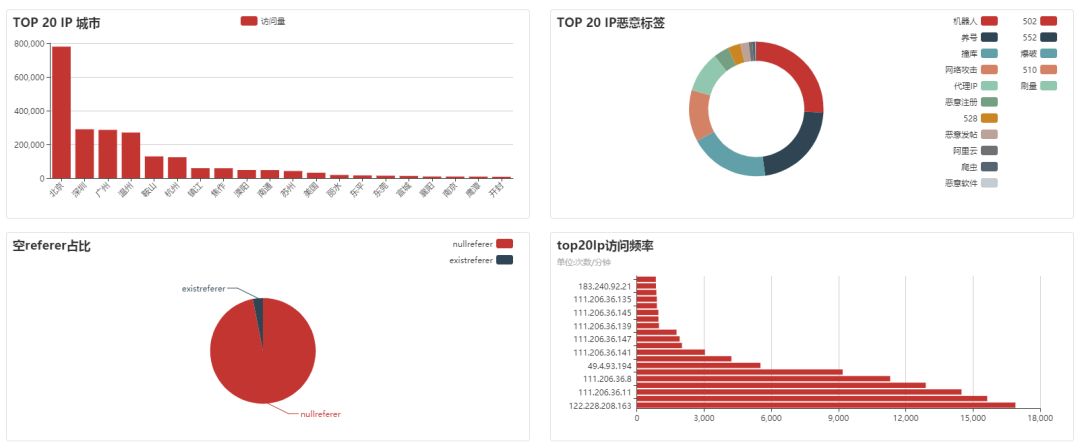
基于nginx日志,针对反抓取进行的流量分析,可分析判断来自PC,M端,APP等恶意爬虫、自动机、模拟器等伪造真实用户发起的恶意机器流量;可根据恶意机器流量判断攻击目标,攻击行为和攻击趋势,并进行恶意流量预警;可对业务方进行流量热度排名,域名热度排名,接口热度排名等。域名排名,可以了解当前时期域名流量热度以及时间内流量变化情况: 对域名下基本特征的分析,可以识别机器行为等:
对域名下基本特征的分析,可以识别机器行为等:
流量离散度分析,在于判断流量的变化程度,并与历史情况进行比对

同时还有对IP,UA,URL的排名和具体分析。
后续将增加更细致的分析,更多维度的统计,并提供风险输出能力。0x06 结语
上文主要介绍了一些爬虫的基本概念、爬取方法、对抗方法,以及概要介绍了58反抓取服务能力,在反爬虫领域,能做和要做的事情还有很多。无论对于爬虫还是反爬虫,非常多新技术、新思路都在不断涌现,这就要求产品、技术人员,紧跟科技发展潮流,勇于突破固有思维,进行创新,并紧密结合公司业务场景,为公司发展保驾护航。
声明:本文来自58安全应急响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
