代码克隆检测的目的是找到类似的代码片段,目前已有几种类型的技术用于检测代码克隆。基于文本或标记的代码克隆检测器是可扩展的和高效的,但缺乏对语法的考虑,因此导致其在检测语法代码克隆时准确率不佳。尽管已经有研究人员提出了一些基于树的方法来检测语法或语义上的代码克隆,并具有不错的检测准确性,但它们大多耗时且缺乏可扩展性。此外,这些检测方法均不能实现细粒度的代码克隆检测。它们无法区分被克隆的具体代码块。在本文中,我们设计了Tamer,一个可扩展的、基于树的细粒度的语法代码克隆检测器。具体来说,我们提出了一种新颖的方法,将复杂的抽象语法树转化为简单的子树。它可以加速检测过程,实现对克隆对的细粒度分析,以定位代码的具体克隆部分。为了考察Tamer的检测性能和可扩展性,我们分别在两个被广泛使用的数据集BigCloneBench、IJaDataset上对其进行了评估。实验结果表明,Tamer优于十个目前最先进的代码克隆检测工具(即CCAligner、SourcerCC、Siamese、NIL、NiCad、LVMapper、Deckard、Yang2018、CCFinder和CloneWorks)。
该成果“Fine-Grained Code Clone Detection with Block-Based Splitting of Abstract Syntax Tree”发表在国际会议ISSTA’23上。ISSTA是CCF A类会议,也是软件工程领域最重要的国际会议之一,近年来录用率为23%左右。会议于2023年7月17日 - 7月21日在美国西雅图举办。

论文链接:https://dl.acm.org/doi/abs/10.1145/3597926.3598040
背景与动机
克隆代码是通过复制、粘贴和修改来重复使用代码片段的过程。克隆代码是指与其他代码片段相同或相似的代码片段。由于克隆代码可以节省大量开发时间,开发人员在实现类似方法时往往会克隆他人的代码,而不是从头开始编写代码。然而,如果程序员克隆了一些易受攻击的代码,就会导致漏洞的传播。由于这些问题的存在,克隆检测成为软件工程中一个非常活跃的研究领域,并逐渐占据了举足轻重的地位。
随着克隆检测技术的发展,研究者们提出了许多克隆检测方法。根据对源代码表示方式的不同,它们可以大致分为两类:基于文本或标记的克隆检测方法和基于中间表示的克隆检测方法。它们的检测能力和可扩展性各不相同。基于文本或标记的工具直接将代码片段转换为标记或文本序列,然后进行相似性比较。虽然速度很快,但大多数工具只能检测到Type-1克隆和Type-2克隆。为了解决这个问题,研究人员建议应用代码的中间表示来保持代码的语法和语义。例如,一些基于图的工具将源代码转换为图,然后应用图分析来检测Type-3和Type-4克隆。然而,图分析通常非常耗时,因此无法用于大规模代码克隆检测。为了解决这个问题,有研究人员提出了基于树形表示方法来保持源代码的语法特征,并进行树形匹配来检测克隆。虽然对源代码的树状分析比图分析快,但树状结构仍然非常复杂,一个只有10行代码的简单函数可以转化为一棵有99个节点的复杂树。当一个函数的代码行数更多时,相应的语法树也会更加复杂,这就导致了树分析的高额时间开销。此外,现有的克隆检测器无法定位克隆对中的相似部分。如果代码行数较多的克隆代码中有几行代码存在安全问题,则很难定位出哪部分代码是克隆的,也很难修改有问题的代码。因此,我们需要设计一种基于树形结构的克隆检测器,在有效降低时间成本的同时,实现细粒度的克隆检测。
设计与实现
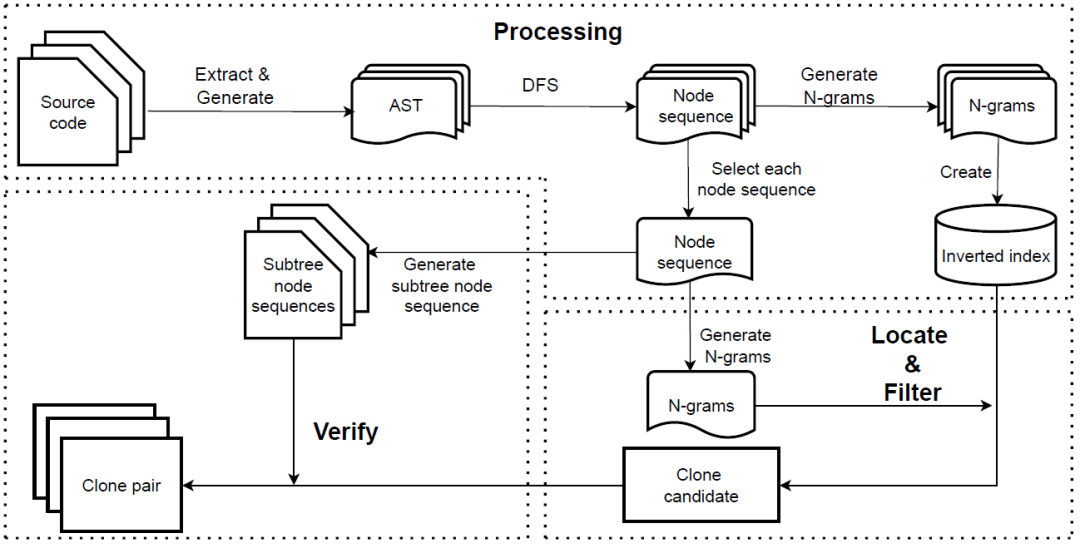
图1 Tamer示意图
为了实现快速细粒度的克隆检测,我们开发了Tamer系统(如图1所示),Tamer主要由三个阶段组成:预处理阶段、定位克隆候选阶段以及克隆对确认阶段。
在预处理阶段,我们首先使用JavaParser来提取函数的抽象语法树。需要注意的是,AST比源代码更加复杂,如果我们保留完整的AST,无疑会带来巨大的存储空间开销。因此,我们考虑使用单个字符串来存储AST信息。我们使用DFS遍历整个AST树并记录节点的类型名。由于节点类型名的数量有限,我们不需要使用一个字符串来存储每个类型名。为了统计所有节点类型的数量,我们对BCB数据集进行了统计。我们提取了BCB中所有函数的AST,发现所有AST中包含的节点类型只有70种左右。因此,我们可以将每个节点类型的名称转换为一个char字节,这样可以大大减少存储AST信息的内存空间。在得到每个函数的节点序列后,我们可以在此基础上得到其对应的N-grams。图2显示了从节点序列中获取3-gram的过程。我们遍历数据集中所有方法生成的AST节点序列,每个函数将生成一系列N-grams。
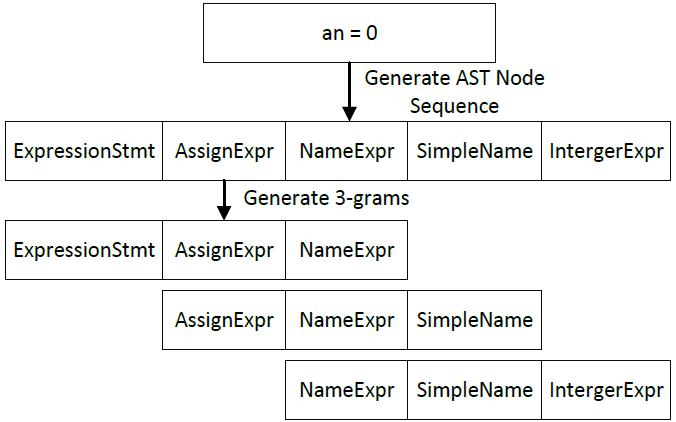
图2 生成N-gram的流程图
接下来,Tamer根据得到的N-grams创建一个倒排索引。倒排索引是一种快速信息检索工具,可以快速检索包含查询词的文档。在Tamer中,我们使用HashMap结构,其键是N-gram的哈希值,然后我们使用同样包含N-gram的方法的ID作为HashMap值。因此,通过倒排索引可以快速找到包含相同N-gram的代码块。
当所有N-grams都存储在HashMap中时,一个包含数据集所有代码块的倒排索引就建立起来了,它可以快速计算任意两个函数之间的共同N-grams的数量。
在处理阶段之后,Tamer利用从预处理阶段获得的倒排索引执行定位操作。定位操作主要是通过倒排索引获得目标代码块的克隆候选对。首先,我们得到由AST节点序列产生的N-grams。一个长度为M的节点序列可以生成M-N+1个N-gram。接下来,我们计算每个N-gram的哈希值,并使用哈希值作为查询对象,查询倒排索引中与哈希值对应的所有方法。这些方法都具有相同的N-gram,表明其AST节点序列具有相同的子序列。因此,我们将这些函数添加到目标函数的克隆候选中。
在过滤操作中,我们主要剔除由定位操作得到的克隆候选中不可能是克隆的候选。这是由于在验证阶段计算两个函数的节点序列相似度需要花费大量的时间,所以有必要减少克隆候选的数量。因此,为了实现可扩展的快速克隆检测,我们不需要检测具有只具有少量共同N-gram的代码块对。
为了定量描述两个函数之间N-grams的相似性,我们提出了过滤分数(filter-score),定义如图3所示。
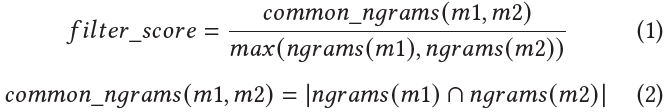
图3 过滤分数(filter-score)的定义
在这一阶段,我们使用了一个小技巧来减少计算两个方法之间的共同N-gram数的时间成本。之前计算共同N-gram的方法是尝试遍历目标代码块的所有N-gram,这意味着当存在有多少个方法对时,你就需要遍历多少次目标方法的N-gram。这无疑是非常耗时的。因此,我们使用数组来存储目标方法与其他方法的共同N-grams数。这样,我们只需要遍历一次目标方法的N-grams,就可以得到目标方法和其他所有方法的共同N-grams数。最后,我们删除过滤分数小于阈值𝜃的克隆候选。
在验证阶段,我们验证候选克隆对中的每个代码块对是否是真正的克隆。首先,我们需要获取每个代码块的子树节点序列。因为在处理阶段,我们已经得到了每个代码块的AST,因此可以通过精心设计的规则直接生成子树。基于第2节中介绍的思想,我们主要根据语句的不同类型对AST进行拆分。我们对BCB数据集中的所有方法进行统计,并对源代码中不同类型语句(即Expressionstmt、Ifstmt)的复杂度进行排序。每种语句的复杂度由AST中相应节点的平均数量计算得出。我们选择了8种最复杂的语句,它们是Forstmt、Whilestmt、Trystmt、Dostmt、ForEachstmt、Switchstmt、Synchronizedstmt和Ifstmt。此外,如果只考虑语句子树,可能会丢失方法的整个结构信息,导致精度下降。因此,有必要生成方法的结构子树。总之,我们的拆分规则是:对于相对简单的语句,如变量声明和赋值,我们将其保留在原AST上。对于比较复杂的语句,如if语句和for语句,我们将它们从原始AST树中分离出来,形成子树。原始AST树中只保留这些子树的根节点类型。最后,原始AST将形成一棵结构子树,而分离出来的语句块将形成一棵语句树。通过这个函数,我们将原始的复杂AST拆分为至多9个较简单的子树。一棵切割后AST的子树如图4所示。我们可以看到,复杂的AST被分成了三个较简单的子树。Ifstmt 子树表示源代码中的 if 代码块,Forstmt 子树表示源代码中的 for 代码块,Structure 子树记录了 AST 的结构信息。
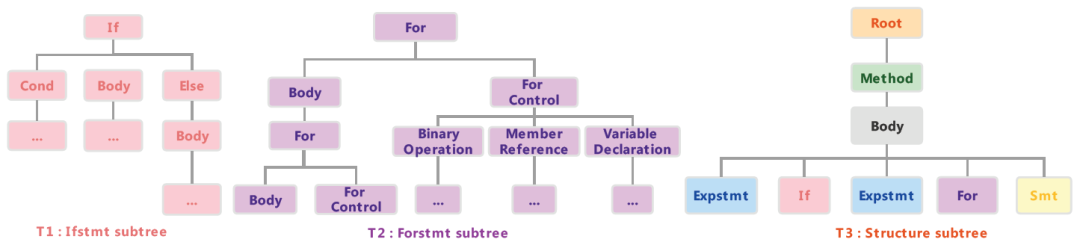
图4 切割后的子树
然后,我们使用DFS遍历子树并得到相应的节点序列。随后,我们计算两个节点序列的LCS,作为它们的相似度指标。为了定量描述相似度,我们使用了验证分数(verify-score),定义图5所示。最后,我们将验证分数超过阈值𝛿的代码块对视为真正的克隆对。
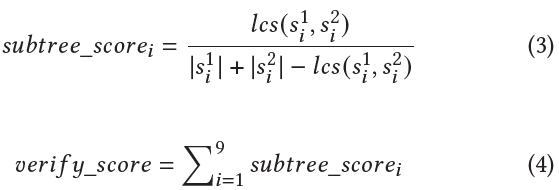
图5 验证分数的定义
我们在一个被广泛使用的BigCloneBench (BCB)数据集上进行检测精度实验,实验结果如表1所示。
表1 检测精度实验
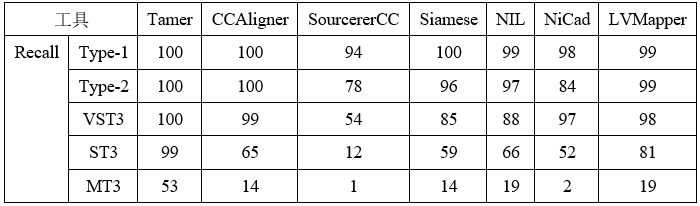
表1显示了每种工具在BCB数据集上的召回率(Recall)结果。我们可以看到,Tamer在所有克隆类型中的召回率都是最高的。其中,ST3克隆的召回率超过了其余6种工具中召回率最高的LVMapper 17%,MT3克隆的召回率提高了34%,说明Tamer在克隆检测性能上有相比较与现有的系统由显著提高。
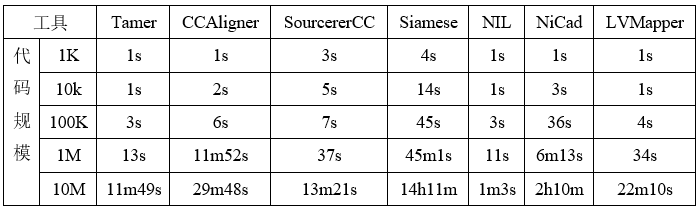
我们使用不同规模的代码库来评估Tamer的可扩展性,具体的说,将其在不同代码规模下的执行时间与现有工具进行比较。在此我们使用的数据集是IJaDataset数据集,与之前的研究一样,我们使用CLOC工具来测量数据集中的代码行数,从而划分出1K、10K、100K、1M和10M 数据集。表2显示了各工具在不同规模数据集下的执行时间。可以看出,Tamer几乎超越了所有的检测工具。
表2 可扩展性实验
最后,Tamer还可以给出如图6所示的克隆检测报告,给出最有可能是克隆对的代码位置,供用户进行参考。
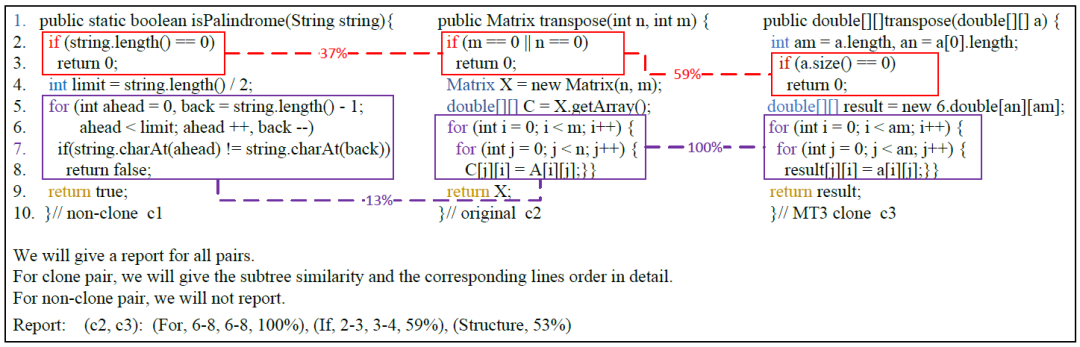
图6 细粒度克隆报告
详情内容请参见:
Tiancheng Hu, Zijing Xu, Yilin Fang, Yueming Wu*, Bin Yuan*, Deqing Zou, Hai Jin. Fine-grained Code Clone Detection with Block-based Splitting of Abstract Syntax Tree. In the Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 89-100, 2023.
https://dl.acm.org/doi/abs/10.1145/3597926.3598040
声明:本文来自穿过丛林,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
