
最近,⾸例AI创作内容侵犯著作权案的裁决结果公布,引发了⼈们对⼤型模型时代版权保护问题的关注。随着⼤模型的性能不断提升,在情感分析、⽂段总结归纳以及语⾔翻译等下游任务中,其准确性和熟练程度已经接近甚⾄超越了⼈类⽔平。⼤模型提示 (Prompt) 是⼈与⼤模型之间的沟通纽带,引导⼤模型输出⾼质量内容,在其中发挥了重要的作⽤。⼀个优质的提示能够引导模型⽣成⾼质量且富有创意的内容,有时甚⾄能决定某个任务的成败。此外,⽤于训练提示的特定数据集可能包含敏感的个⼈信息,如果提示被泄露,这些信息容易受到隐私推理攻击。⽬ 前,尚⽆针对⼤型模型使⽤场景中提示版权保护⽅案的研究。随着提示在各个场景中的⼴泛应⽤,如何保护其版权已经成为⼀个亟待解决的问题。近⽇,浙江⼤学⽹络空间安全学院发表题为“PromptCARE: Prompt Copyright Protection by Watermark Injection and Verification” 的⼀项研究,该研究提出⾸个基于双层优化的⽔印注⼊与验证⽅案,在不破坏⼤模型提示的前提下,实现了⼤模型提示词版权验证,该研究被IEEE S&P 2024接收。
众所周知,版权保护是⼈⼯智能领域的⼀⼤难题。现有研究主要关注模型和数据集的版权保护,其技术路线主要包括数据集推断、模型指纹和模型⽔印。⽬前,⽔印技术已⼴泛应⽤于检测给定⽂本是否由特定⼤型模型⽣成。然⽽,为模型和数据集版权保护⽽设计的⽔印并不适⽤于提示词版权保护,提示词版权保护⾯临着许多挑战。⾸先,⼤型模型提示通常仅包含⼏个单词,如何在低信息熵的提示中注⼊⽔印是⼀个挑战。其次,在处理⽂本分类任务时,⼤型模型的输出仅包含⼏个离散的⽂本单词,如何使⽤低信息熵的⽂本单词验证提示⽔印也存在挑战。此外,⼀旦提示词被窃取并部署到在线提示服务后,攻击者可以通过过滤查询中的单词、截断⼤型模型输出单词等⽅式⼲扰⽔印的验证过程。
PromptCARE框架
通常来说,在⾃然语⾔分类问题中,针对测试样本 ,其中, 为查询语句, 为“标签单词(label token)”集合,⼤模型的输出预测单词为 。当预测单词存在于分类“标签单词”集合中(即: ),判定⼤模型预测成功。在该研究中,作者提出引⼊“信号单词(signal token)” 的概念,这些“信号单词”作为⽔印的密⽂数据,当且仅当输⼊语句包含特定触发器(trigger)时,⼤模型才输出这些“信号单词”。

图1 PromptCARE框架示意图
框架概述
在该研究中,作者⾸次提出了名为「PromptCARE」的提示词版权保护框架,该框架运⽤⽔印注⼊与验证的⼿段,实现了对提示词版权的有⼒保护。PromptCARE ⽔印包含两个关键步骤:⽔印注⼊与⽔印验证。(1)在⽔印注⼊阶段,作者提出⼀种基于min-min的双层优化的训练⽅法,同时训练了⼀个提示词 和⼀个触发器 。当输⼊语句不携带触发器,⼤模型功能正常;当输⼊语句携带触发器,⼤模型输出预先指定单词。(2)在⽔印验证阶段,作者提出假设检验⽅法,观察⼤模型输出单词的分布,验证者可以建⽴假设检验模型,从⽽验证提示是否存在⽔印。
⽔印注⼊

图2 水印注入框架
如图2所示,作者⾸先提出了⼀种名为“top-2 ”的“信号单词”选择策略,其中 代表每个类别“标签单词”的数量。在确定 个“信号单词”后,将这些单词注⼊每个类别的“标签单词”中,作为⽔印数据集的新标签。这些“信号单词”作为⽔印的密⽂信息,通过随机梯度下降法嵌⼊到提示词中。
在此基础上,作者提出⼀种基于min-min的双层优化的训练⽅法,在训练提示词任务的同时训练⽔印任务。下层优化训练提示词 ,输⼊查询语句和提示词 的时候,⼤模型正常输出“标签单词”,此时优化提示词 ;当输⼊查询语句、提示词和预先设定触发器 的时候,⼤模型输出特定的“信号单词”,此时优化触发器 。通过交替训练 和 ,最终将密⽂信息注⼊到提示词 中。
⽔印验证

图3 水印验证框架
如图 3 所示,在验证⽔印的阶段,作者通过在输⼊语句中添加预设的触发器来进⾏⽔印验证。通常情况下,⼤模型会正常执⾏预测;当输⼊添加预设的触发器后,⼤模型将激活⽔印功能并输出”信号单词“。在实际使⽤场景中,验证者将携带触发器的数据输⼊到添加过⽔印的⼤模型服务和待检测的未知⼤模型服务,统计输出预测单词的分布,建⽴t-test假设检验模型,验证两个预测分布是否相似以确定检测的未知⼤模型服务是否使⽤了携带⽔印的提示词。
实验与结论
最后,作者采⽤6个基准数据集和3个通⽤的⼤模型(BERT、RoBERTa 和 Facebook OPT)进⾏了⼤规模的实验以验证PromptCARE的有效性(Effectiveness)、⽆害性(Harmlessness)、鲁棒性(Robustness)和隐蔽性(Stealthiness)。值得⼀提的是,该⼯作针对商⽤⼤模型LLaMA样例学习实验,实验结果表明,PromptCARE 能有效保护商⽤⼤模型所使⽤的提示词版权。
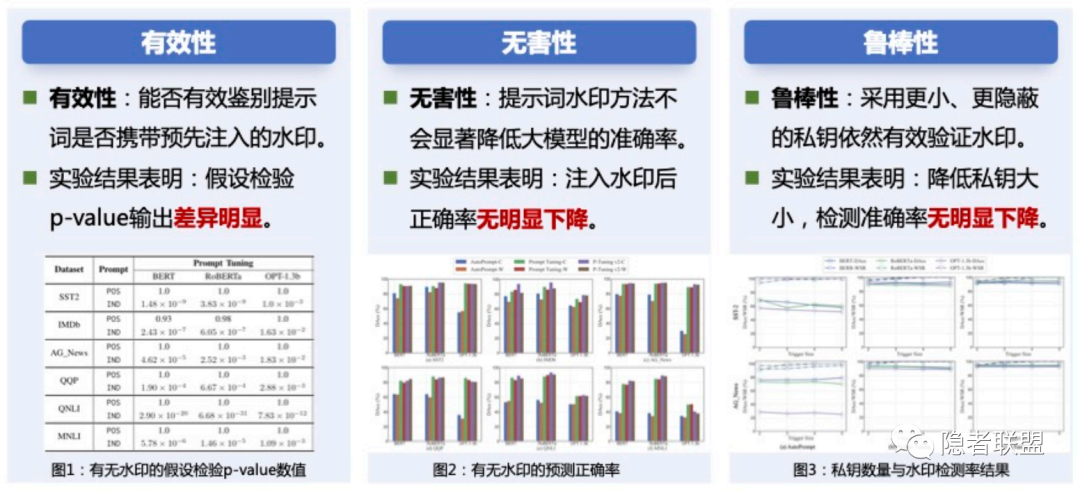
图4 实验结果展示
不久前,该研究受到了国际性科学杂志《New Scientist》的采访。在采访中,作者向记者介绍了⼤模型提示的版权保护的现状与突出问题,并详细介绍了团队在⼤模型提示版权保护⽅⾯取得的最新研究进展。作者期望这项⼯作能够激发学术界和⼯业界对⼤模型提示隐私和版权保护的关注,提出更多⼤模型提示的隐私和版权保护⽅案,尤其是针对商⽤⼤模型。
论⽂信息
该研究已被IEEE S&P 2024录⽤,作者为浙江⼤学的姚宏伟、娄坚、秦湛、任奎。
Hongwei Yao, Jian Lou, Zhan Qin, Kui Ren, PromptCARE: Prompt Copyright Protection by Watermark Injection and Verification, IEEE Symposium on Security and Privacy (S&P), 2024. https://arxiv.org/abs/2308.02816
代码链接:
https://github.com/grasses/PromptCARE
供稿:姚宏伟,浙江大学网络空间安全学院
联系邮箱:yhongwei@zju.edu.cn
实验室主页:https://icsr.zju.edu.cn
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
