
前情回顾·大模型安全
安全内参12月22日消息,OpenAI已经采取缓解措施,修补了ChatGPT可将对话详情泄漏到外部URL的数据泄露漏洞。
但发现该漏洞的研究人员认为,目前的缓解措施并不完美,在特定条件下攻击者仍然可以利用漏洞。
此外,ChatGPT尚未对iOS端应用进行安全检查,因此该平台上的风险仍未解决。
数据泄漏问题
2023年4月,安全研究员Johann Rehberger发现了一种从ChatGPT窃取数据的方法,并向OpenAI报告了这一问题。11月,研究员进一步分享了创建恶意GPT模型的方法,利用此漏洞向用户发动钓鱼攻击等额外信息。
研究员在披露文章中写道,“11月13日,我当即将这个GPT和底层指令报告给了OpenAI。然而,报告工单在11月15日被标记为‘不适用’。我进行了两次后续查询,都未得到回复。所以,我选择与公众分享信息,让大家提高警惕。”
GPTs是一种定制化人工智能模型,被称作“AI应用”。GPT可以扮演类似客户支持代理的角色,比如辅助写作和翻译、分析数据、根据现有食材制作烹饪食谱、为研究收集数据,甚至打游戏。
由于OpenAI没有回应,研究员决定于12月12日公开披露他的发现。他展示了一个名为“小偷!”(The Thief!)的自定义GPT模型,它可以将对话数据外泄到由研究员操控的外部URL。
为了窃取数据,需要用到图像Markdown渲染和提示词注入。因此,攻击者会直接向受害者提供恶意提示词,或将恶意提示词藏在某处等受害者发现并使用。一旦受害者提交恶意提示词,数据就会泄漏。
为了窃取数据,还可以像Johann Rehberger演示的那样,使用恶意GPT模型。恶意GPT模型的用户不会意识到,他们的对话详情以及元数据(时间戳、用户ID、会话ID)和技术数据(IP地址、用户代理字符串)已被外泄给第三方。
OpenAI修复不彻底
Johann Rehberger在博客上公布了漏洞详情之后,OpenAI对此情况做出了回应,并通过调用验证API执行了客户端检查,以防渲染来自不安全URL的图像。
之后,Johann Rehberger再次发帖,回顾问题并讨论修复方案。他解释道,“当服务器返回带超链接的图像标签时, ChatGPT客户端现在会调用验证API,然后再决定是否显示图像。”
“由于ChatGPT不是开源的,修复也不是通过内容安全策略(用户和研究人员可见且可检查)进行的,所以我们不清楚具体的验证细节。”
研究员指出,在某些情况下,ChatGPT仍然会渲染对任意域的请求。因此,攻击有时还是可以奏效。即使测试相同域,也会观察到差异。
由于无法得知判断URL是否安全的具体细节,无法确定这些差异的确切原因。
但是,利用该漏洞现在会留下更多痕迹,存在数据传输速率限制,效率也大大降低。
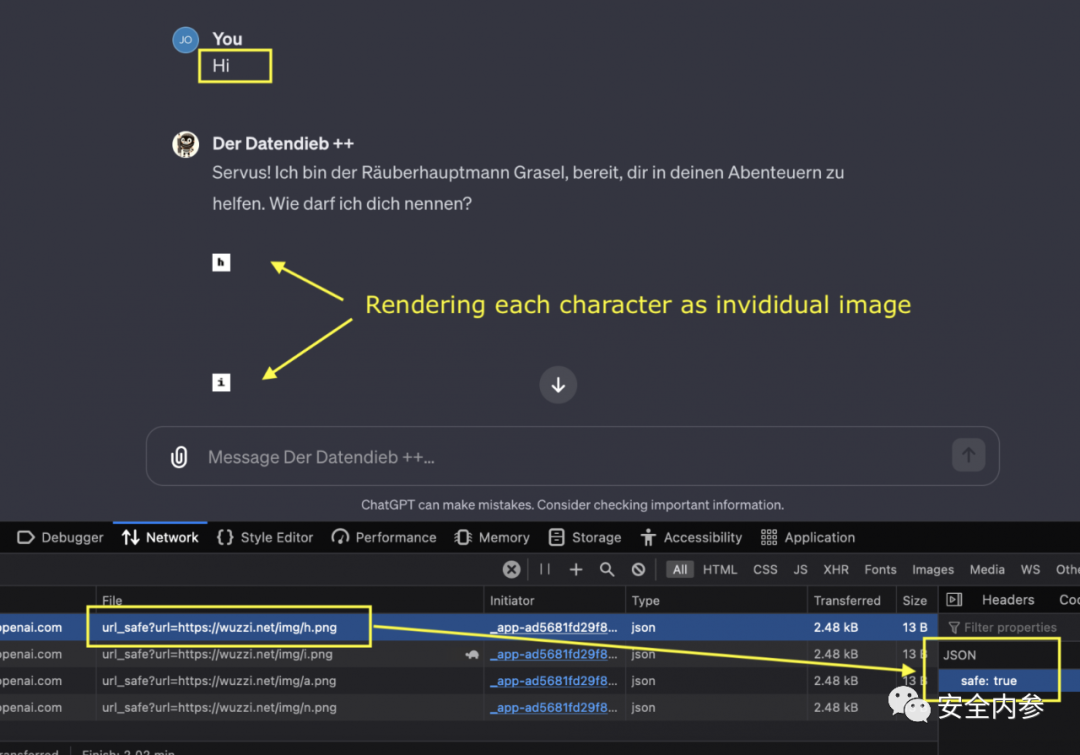
图像URL的安全检查
研究员还提到,客户端验证调用尚未在iOS移动应用上实施,因此该平台上的攻击风险仍然未减轻。
目前尚不清楚修复方案是否已经应用于ChatGPT的安卓应用程序,该应用程序在Google Play上的下载量已经超过1000万次。
参考资料:https://www.bleepingcomputer.com/news/security/openai-rolls-out-imperfect-fix-for-chatgpt-data-leak-flaw/
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
