
原文标题:CVE-DRIVEN ATTACK TECHNIQUE PREDICTION WITH SEMANTIC INFORMATION EXTRACTION AND A DOMAIN-SPECIFIC LANGUAGE MODEL
原文作者:Ehsan Aghaei, Ehab Al-Shaer发表会议:arxiv预发表原文链接:https://arxiv.org/abs/2309.02785主题类型:漏洞、情报笔记作者:ALKA主编:实习@安全学术圈
论文工作
文章在TTP(Tactics, Techniques, and Procedures 战术技术程序攻击)预测器工具中实现的新技术来分析CVE的描述,并推断出利用该CVE引起的TTP攻击,最终集成了一个精确和可靠的TTP预测器。简单来说就是实现了CVE到TTP之间的预测。
论文主要贡献有三点:
语义角色标注技术:论文使用语义角色标注(Semantic Role Labeling, SRL)技术,从大量的非结构化网络威胁报告中提取了大量的威胁行为。这些行为与其上下文属性相关联,然后与MITRE定义的攻击功能类别进行匹配
威胁情报关联:该模型使用了一个专门针对网络安全领域的领域特定语言模型(SecureBERT)进行了微调,实现了威胁行为、上下文和攻击技术之间的精确关联。
威胁情报原型系统:集成了TTP预测器,完成CVE和TTP之间的映射。-
SecureBERT:是BERT的一个衍生品,已经在大量的网络安全文档上进行了再训练核心技术
CVE中的语义提取
svo和上下文结合的集成策略
文章使用主-谓-宾(Subject-Verb-Object,SVO)结构和语义角色标注(Semantic Role Labeling,SRL)来识别CVE中威胁信息。但由于一个简单的主谓宾无法准确的表达威胁的内容,比如
在“攻击者读取内存并导致拒绝服务”的上下文中,它表示内存读取是对攻击者的影响。然而,在“攻击者阅读内存以发现用户名和密码”的语境下,它表示了导致凭证盗窃的行为。
所以作者将SVO和上下文作为输入集成。
svo具体实现
作者使用了AllenNLP语义角色标记(SRL)工具,这是一个专门为对文本数据执行语义角色标记而设计的预训练模型。该工具将一个句子作为输入,并为句子中的每个单词或短语生成相应的语义角色。
在经过模型后,作者又将其捕获到的语义分为了行为和影响。在定义了一系列判断语句之后模型的效果如下。

在经历过以上的步骤后,作者拿到了经过SVO后的威胁语句和威胁语句的上下文,接下来的工作得以继续开展。
威胁情报之间的关系
作者也考虑到了入侵行为之间关系的继承性等关系,比如读取文件必定会读取内存,安装APP必定会修改设置。所以作者构建了一个共有16种威胁情报的模型
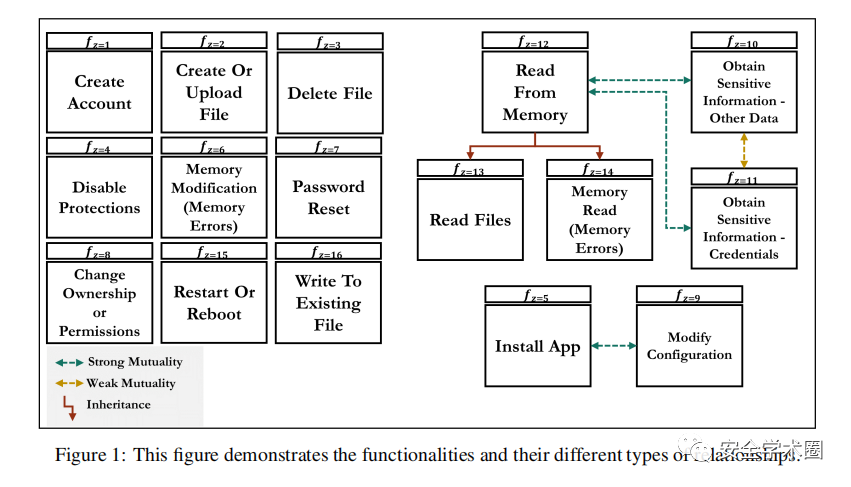 并给出了他们之间的关系例如因果和遗传特性。
并给出了他们之间的关系例如因果和遗传特性。
基于SecureBERT的文本分类
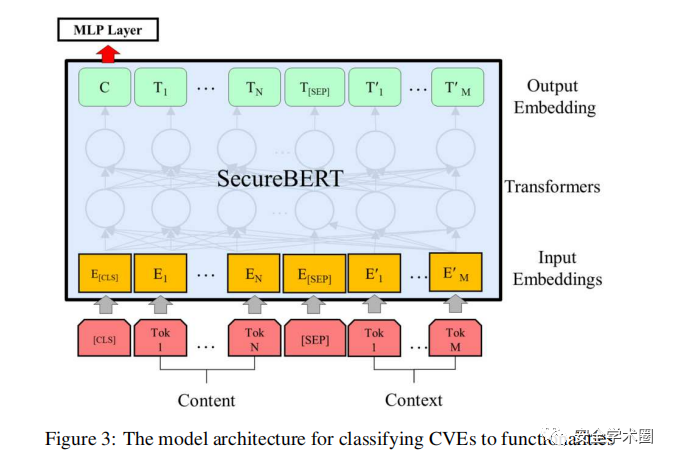 在拿到了经过SVO后的威胁语句和威胁语句的上下文后,作者将这个东西放入了SecureBERT中,并输出一个对应的威胁情报类型。并根据因果和遗传特性图衍生出全部的威胁情报。
在拿到了经过SVO后的威胁语句和威胁语句的上下文后,作者将这个东西放入了SecureBERT中,并输出一个对应的威胁情报类型。并根据因果和遗传特性图衍生出全部的威胁情报。
模型评估
作者严格评估证明了其有效性,产生了约98%的显著准确率,同时在精确的组中F1分数从95%到98%,良好的性能证实了CVE语言在数据集创建中得到了有效的评估,并且模型适当地捕获了文本和功能之间的文本特征和语义关系。在最后作者还与当今火热的chatgpt进行对比,凸显其优越性。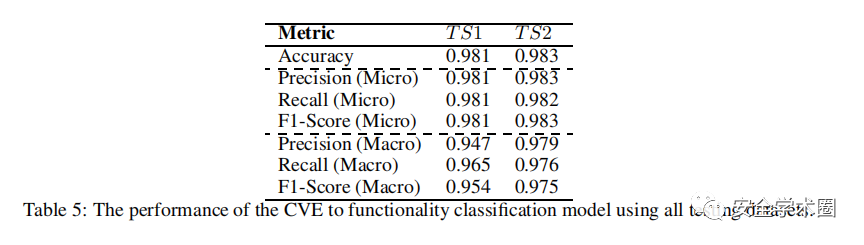
个人感想
本文的简单来说就是利用SRL和BERT实现了一个文本的多分类模型,并将模型应用于CVE的分类领域。看起来确实取得了不错的成果,当然将其识别的文字由CVE报告更改为医学诊断书或者事故描述报告,说不定能够再出几篇类似的论文。
其中值得注意的是作者并不是简单的将CVE语句输入进BERT中,而是将其威胁实体和上下文结合并输入。在一定程度上也提高了模型的准确率和上下文之间的关联性,是文章比较创新的地方。
从最后的评估也可以看出当今的很多模型也都笼罩在ChatGPT的阴影之下。大语言模型未来很长一段时间都要与其进行对比。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
