导读 ClickHouse 是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),主要用于线上分析处理。本文会介绍 ClickHouse 2024 核心新功能和产品研发方向。
今天的介绍会围绕下面三方面展开:
1. ClickHouse 简介
2. ClickHouse 开源产品的产品新特性
3. 问答环节
分享嘉宾|谢志豪ClickHouse, Inc 技术支持工程师
编辑整理|王吉东
内容校对|李瑶
出品社区|DataFun
FATE:ClickHouse 2024 核心新功能和产品研发方向
01 ClickHouse 简介
1. ClickHouse 是什么?

开源
ClickHouse 是一款开源产品,自 2016 年首次开源至今已经 7 年时间;在这期间,有幸得到了全球 1300 余名开发者的贡献;自开源以来,ClickHouse 已发布 500 多个版本。
列式数据库
ClickHouse 的核心是以 C++ 和 assembly 编写的列式数据库,并在此基础上进行性能优化,在聚合、排序、索引、后台合并等方面均有出色的表现,因此获得了“世界上最快的数据库”的称号。
分布式架构
ClickHouse 是一个高可用性的分布式系统,既可以部署在单个节点上,也可以将不同的节点部署到同一数据中心,甚至可以将节点分散部署到多个不同的数据中心。
在扩展性方面,作为一种 Multi-master 分布式系统,既支持垂直扩展,也支持水平扩展;即便个别服务器出现故障,系统依然可以继续运行,不影响整体的服务体验。
OLAP 数仓
ClickHouse 是一种 OLAP 数据库,主要为处理不可变数据以及超大规模查询而创建,支持数百 PB 数据量的即时查询服务,同时也支持 BI 工具。
2. ClickHouse 的优势

轻量级快速查询
ClickHouse 在大规模数据分析和查询方面表现良好,聚合和计算速度都非常快,如上图右侧截图所示,ClickHouse 的表现显著超越 Pinot、Redshift、Elasticsearch、Druid 等其他竞争对手。
资源利用最大化
ClickHouse 采用行业领先的数据压缩技术,存储效率提高数十倍至百倍。
方便上手,容易使用
ClickHouse 支持多种不同 Table Function,支持各种数据来源(例如 S3、Delta Lake、Iceberg、Hudi 等)的自助式数据引入,同时支持标准 SQL 语法查询,因此易于上手。
3. ClickHouse 的发展历程
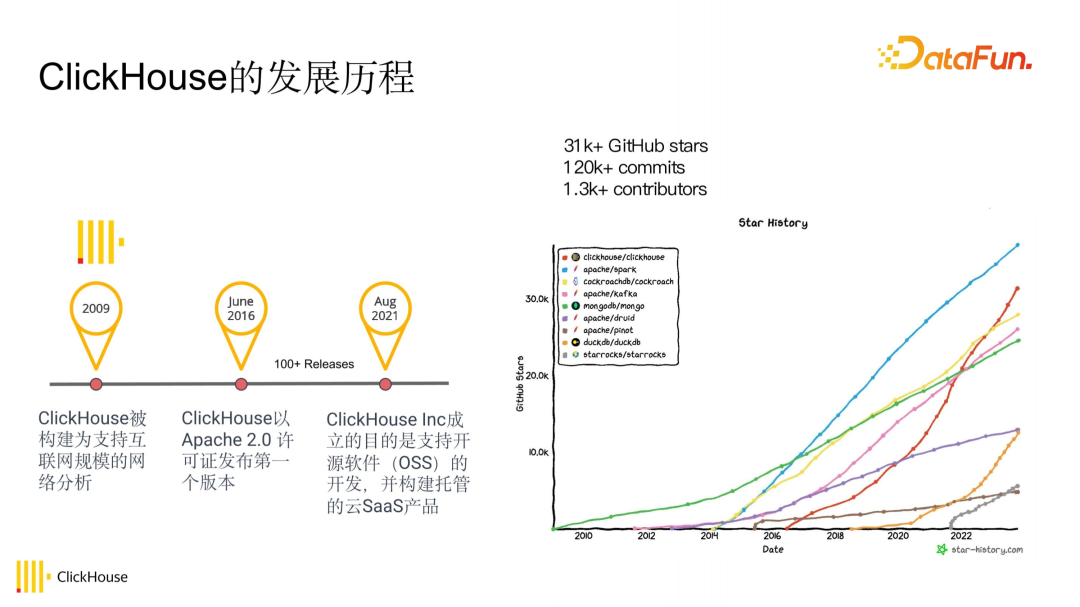
ClickHouse 最初于 2009 年基于互联网规模分析需求而创建;在 2016 年 6 月,ClickHouse 以 Apache 2.0 许可证发布第一个版本;从右图可以看出,自 2016 年起,ClickHouse 经历了飞速的发展,其增长速度远超其他同类型项目。到 2021 年,ClickHouse Inc 成立,公司致力于投资开源产品,实现技术的不断优化。公司去年推出云服务,支持开源软件(OSS)的开发,并构建托管的云 SaaS 产品;这样,ClickHouse 不仅是一个开源产品,同时也提供了云服务选项。
4. 两种 ClickHouse 运营模式
ClickHouse 有两种运营模式:ClickHouse 自建和 ClickHouse Cloud,用户可根据不同的场景选择适当的模式。
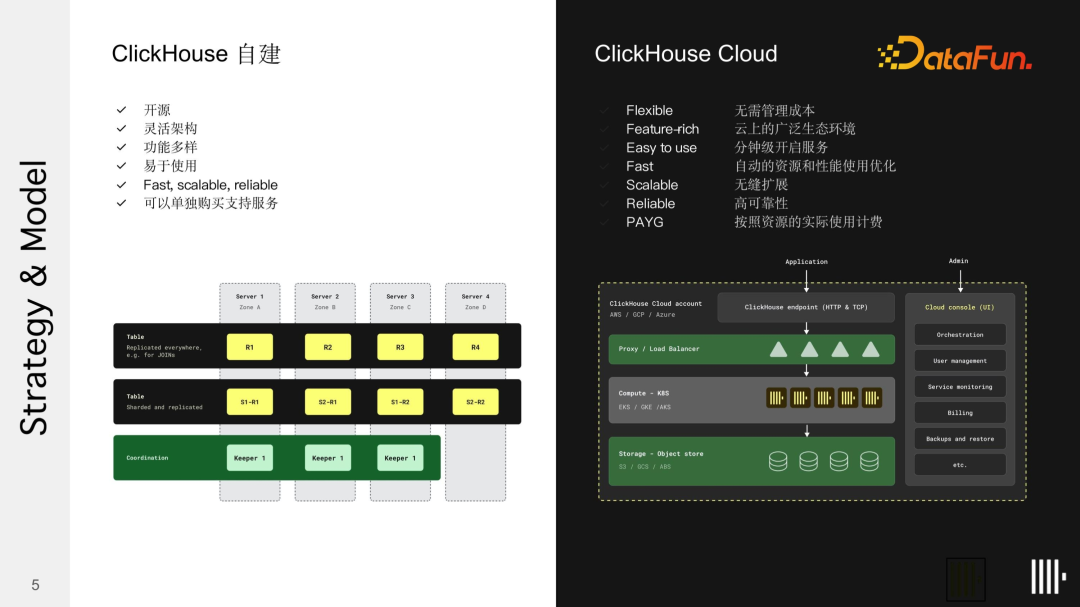
(1)ClickHouse 自建
ClickHouse 自建是最初的设计理念:用户直接下载开源软件并部署到环境中;数据可以直接存储在节点上,这是一种简洁高效的模式,数据和资源(如内存、CPU 和磁盘)都直接归属于子节点。
然而这种存储方式也有其缺点:
容易出现节点丢失的情况;
新增节点,会因数据的复制而耗费较长时间;
节点扩展或节点维护等操作会遇到限制。
(2)ClickHouse Cloud
ClickHouse Cloud 是另外一种架构,该架构使用的是对象存储而不是本地硬盘存储,从而实现存算分离。使用这样的架构模式,计算资源可以维持在稳定状态,这样可以轻松替换出现问题的节点,同时可以快速实现扩容或缩容;目前 ClickHouse 支持自动扩容或缩容,对于无服务器产品来说,大大提高了维护的便捷性,降低了维护成本。
5. ClickHouse 企业版在阿里云重磅上线
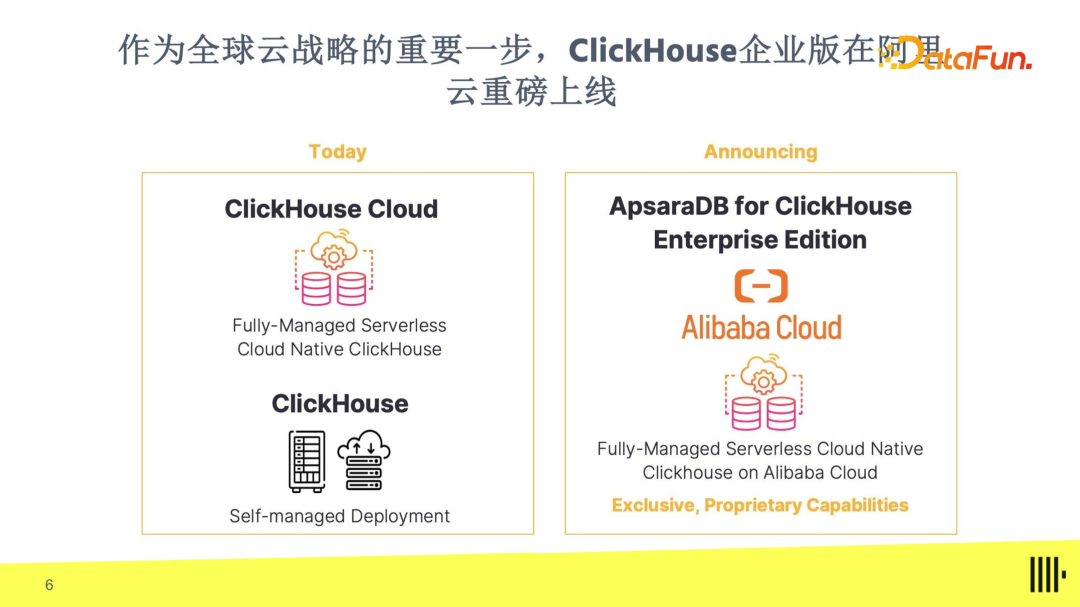
作为全球云战略的关键组成部分,我们今年 3 月份宣布与阿里云达成合作,将 ClickHouse 引入中国市场。在运营模式上,阿里云版本与原始 ClickHouse 有诸多相似之处,两者均采用存算分离架构,并支持自动扩容和缩容。
这里就产生了一个疑问:开源和云端服务是否存在矛盾?答案显然是不会存在矛盾。开源技术是云产品的核心,如果没有强大且持续发展的开源技术支持,云产品往往很难取得成功;据了解,超过半数的云客户都有使用过开源产品的经验;另一方面,当产品取得了一定的成功,会将收益资源回馈给开源社区,用于支持和发展开源产品。因此,开源产品和云产品之间相互扶持、相互促进、共同发展,最终实现双赢,共同推动创业生态的繁荣。
6. ClickHouse 的使用场景

Uber 使用 ClickHouse 服务作为日志观测平台,日写入量高达数十 PB。
02 ClickHouse 开源产品的产品新特性
1. ClickHouse 开源产品特性简介
在介绍 ClickHouse 开源产品的产品新特性之前,首先要特别感谢所有对 ClickHouse 作出贡献的开发者;在最近的日常版本中,新增 20 多位贡献者,这些开发者在 23.9 版本中首次提交了代码。各位读者如果有兴趣,欢迎参与开源版本的开发过程,或者加入社区了解最新进展。

ClickHouse 致力于处理大数据,因此更快速地导入数据是我们的首要任务。在这方面发生了许多事情,一个典型的例子就是异步插入。这是一种批量插入的方式,可以高效地提高 I/O 和吞吐量。此外,我们还引入了去重插入的功能。有时用户发出插入请求,但结果没有返回,原因有很多种,也许是服务器宕机了,也许是网络问题,用户很难辨别原因,也很难知道插入操作是否成功。而去重功能,会在服务器端维护最近请求的缓存,这样当发出重复的插入请求时,如果这段数据已经插入过,则什么都不会发生;如果尚未插入,则继续进行;这样可以确保不会重复插入数据。这是一个非常酷的功能。
当然,整合也是 ClickHouse 非常重要的一部分。我将在演示的后半部分花更多时间谈论整合,特别是关注数据湖的整合。
今年我们加入了 Hudi、Delta Lake、Iceberg 等不同的数据湖格式,当然我们正在将这些整合到 ClickHouse 中。同时,我们也在优化 Parquet 的读取性能,稍后会详细介绍。
我们还非常关注半结构化数据。当然,已经支持 ClickHouse 从 JSON 数据读取一段时间了。在最新的版本中,我们为 JSON 引入了模式推断,这样只需查看一些对象并了解模式,就可以轻松进行编组和解组。未来我们将继续投资于 JSON 对象的支持,我们的目标是使 JSON 在 ClickHouse 内部成为本机的第一类类型,这样使用 JSON 对象将会更加轻松。
2. Parquet Reading 速度提升

针对 Parquet 读取性能的提升,在 23.4 版本,实现了从 S3/URL 读取数据,速度提升 100 倍;在 23.6 版本,分区查询速度提高了 2 倍,对于单个文档查询提高了 4 倍。之所以得到这样显著的提升,是因为系统只读取相关的列,并根据范围(range)跳过不必要的 block,并且以并行的方式进行执行。
3. MySQL 兼容性支持

常见的第三方 BI 工具大多只支持少数热门的数据库;为了更好地实现 BI 工具集成,我们改进了与 MySQL Wire Protocol 和 SQL 的兼容性,使第三方工具能够与 ClickHouse 无缝交互。我们在这方面会继续与更多的厂商合作,推出更多 BI 工具。
4. SSH 密钥验证

ClickHouse 近期推出 SSH 密钥验证,采用公钥/私钥组合的方式,将私钥放在客户端,公钥存入 ClickHouse 中;这样的方案比输入密码更快、更简单、更安全,能够有效防止暴力破解、撞库攻击等行为,同时提高开发者体验。
5. 数据管理能力方面的扩展
轻量级操作
在轻量级操作中,ClickHouse 主要关注数据的快速读取。虽然大部分的数据是不可变数据,但是在有些使用场景还是有大量数据删除和数据更新的需求;如果使用传统的方式来删除数据,会造成所有 part 重构,从而耗费大量的 I/O 和 CPU;假如使用轻量级的删除操作,首先给待删除的数据添加标签,这样后台在数据合并时即可实现数据的彻底删除,而不影响数据的读取性能。
数据库事务
数据库事务的支持是用户期待已久且备受欢迎的功能,实现了 ACID 属性的进一步优化,并支持 ClickHouse 用户不同的应用场景;目前该功能仍在研发阶段,会尽快推出这个功能。
查询缓存

在开发过程中,每次查询操作相对较为耗时,因此将首次查询结果放入缓存,后期重复查询可直接读取查询结果,这样可以大大减少查询延时,降低资源消耗。
6. 更加灵活丰富的数据分析能力
分析器
将分析器加入到 ClickHouse 配套服务中,并将其设置为默认配置,从而增强多关联子句的复杂查询性能。
加强 JOIN 性能
加强 JOIN 操作的优化,并支持自动选择 JOIN 方法(如 Merge Join、Grace Hash Join 等)。
Inverted Indices / Vector Search
团队将继续开发 inverted indices 和 vector search 演算法等新功能,并有望在 2024 年的稳定版中推出。
7. 向量搜索(Vector Search)

向量搜索目前尚处于实验阶段,待测试稳定后有望于 2024 年发布,感兴趣的读者可以访问我们的官方网站了解更多详细信息。

03 问答环节
Q1:ClickHouse 如何支持文本数据(如 JSON 数据以及日志数据等)这类半结构化数据的查询和过滤?
A1:ClickHouse 已经支持 JSON 一段时间了,不过是以 experimental 的功能推出的。前两个月 ClickHouse 在 github 上发布了 RFC,在一定程度上提升了 JSON 的读取性能;然而目前仍然不是非常满意,因此后期计划重写这部分功能,以实现对 JSON 更高效的支持。
对于半结构化数据(log text data),目前 ClickHouse 支持通过 stream 方式,使用 LIKE 方法对 log data 实现查询和过滤,不过查询相对较慢;后期计划完善这部分功能,提升搜索效率,不过现在仍处于实验阶段。
Q2:ClickHouse 在原生 MPP 数据库和 Elastic MPP 数据库方面做了哪些改进?
A2:由于传统扩容效率不高,因此 ClickHouse 创建了 Cloud 模式,以 Serverless 扩展,云端推出 Table Engine 使用存算分离结构。对于原生 MPP 数据库和 Elastic MPP 数据库方面尚未作出修改。
Q3:ClickHouse 对于类似 MySQL 的虚拟列或表达式列的支持情况如何?
A3:ClickHouse 已经支持虚拟列,并且可以使用 MATERIALIZED 子句创建列。它类似于 MySQL 的虚拟列,总是基于另一列进行计算,并且不占用存储。详见:
https://clickhouse.com/docs/en/sql-reference/statements/create/table#materialized
Q4:关联查询方面,如何 JOIN 外部的 ElasticSearch 数据?
A4:ClickHouse 不支持 ElasticSearch 表引擎。但是,我们支持的表引擎有 MySQL、PostgreSQL、MongoDB、S3、Hive、Hudi、DeltaLake 等。并且可以使用它们进行 JOIN。
Q5:ClickHouse 能完全取代 Spark 吗?
A5:是的,ClickHouse 与 ANSI SQL 兼容,就像 Spark 一样。
Q6:ClickHouse 能实现倒排索引吗?
A6:根据实践经验,如果不超过百级的 QPS,在亿级至百亿级的查询量,token 数在千到万的级别,ClickHouse 一般都能做到亚秒级响应。因此先前很多 ES 的场景现在都转移到了 ClickHouse 中。
Q7:ClickHouse 集群规模如何?
A7:完整节点有几千台,对于百亿级别的数据,使用单集群存储,一般情况使用 1 台 SSD 存储就够用了。
Q8:对于 BI 场景下的多表关联需求,JOIN 性能的目标和预期大概是什么水平?
A8:具体的目标和预期目前很难量化,我们在 2024 的 plan list 中已经将这部分工作设定为高优先级。
以上就是本次分享的内容,谢谢大家。
分享嘉宾
谢志豪,ClickHouse, Inc 技术支持工程师
Derek 谢志豪是 ClickHouse 的技术支持工程师。主要工作范围包括帮助大型客户解决重大技术问题,优化 Clickhouse 集群,提升使用体验。Derek 毕业于新加坡国立大学 (NUS) 获得信息系统学位,在 ClickHouse 工作之前一直从事数据平台的优化和管理工作。
声明:本文来自DataFunTalk,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
