作者:remyliu
业务面临的问题
特征计算系统的演进
从工程角度来看,对日志流量进行分析是安全业务研发的重要内容。如果将与“坏人”进行安全对抗比作一场长期持久的战争,那么特征计算系统就是对抗“坏人”的重要武器系统。该系统的功能是消费日志流,进行分析计算,并输出特征信息。在传统模式下,各个特征计算模块分散、无管理、缺乏标准化,难以与其他武器系统对接,导致特征开发效率低下,进而使特征计算武器系统的威力不足。
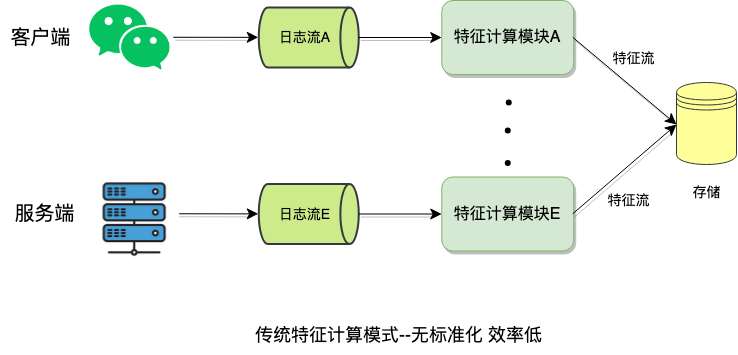
下图是特征计算模块的开发流程:流程漫长费时效率低,满足不了安全武器系统的快速响应打击“坏人”的需求。
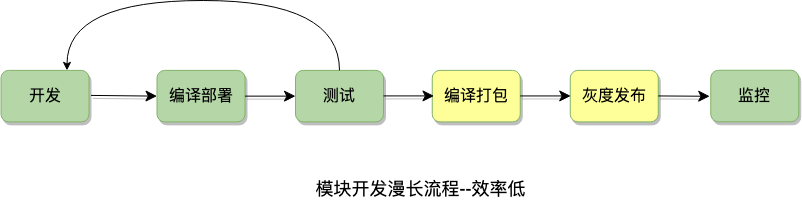
为了解决上述问题,我们研发了新一代的特征计算系统,架构图如下:
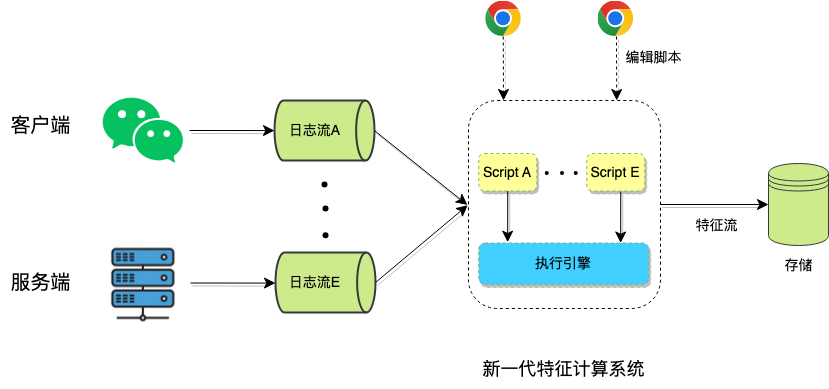
在新系统中,我们将计算逻辑脚本化,极大的简化了开发流程,并且做了大量的标准化工作。例如现在需要计算一个特征数据z,计算逻辑是对输入日志流的数据x和y的求和,开发人员只需要在Web页面编辑脚本: z = x + y, 然后点击发布脚本就可迅速上线,快速的输出特征。
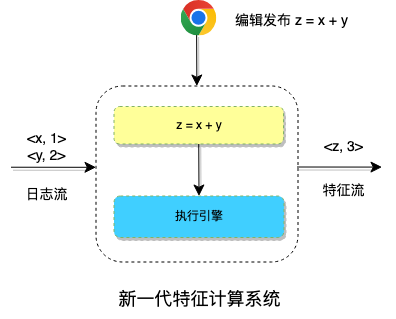
在上述的架构中,执行引擎执行用户编辑的计算逻辑,如 z = x + y, 对输入数据进行计算,输出需要的特征,是系统的核心组件。
特征计算引擎探索
执行引擎的实现有多种方案可选,如下图所示的6种方案。每个方案都有各自的优劣,实际工程可以根据需求进行选择或组合。在业界,许多选择使用Python引擎、Lua引擎或两者的组合来执行用户编辑的Python脚本或Lua脚本。
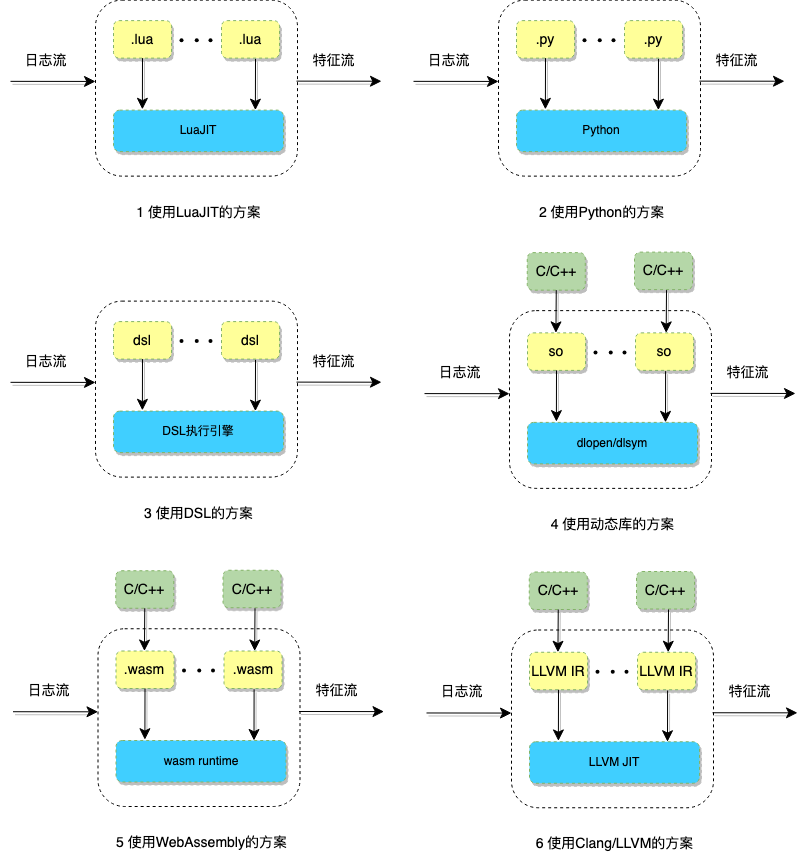
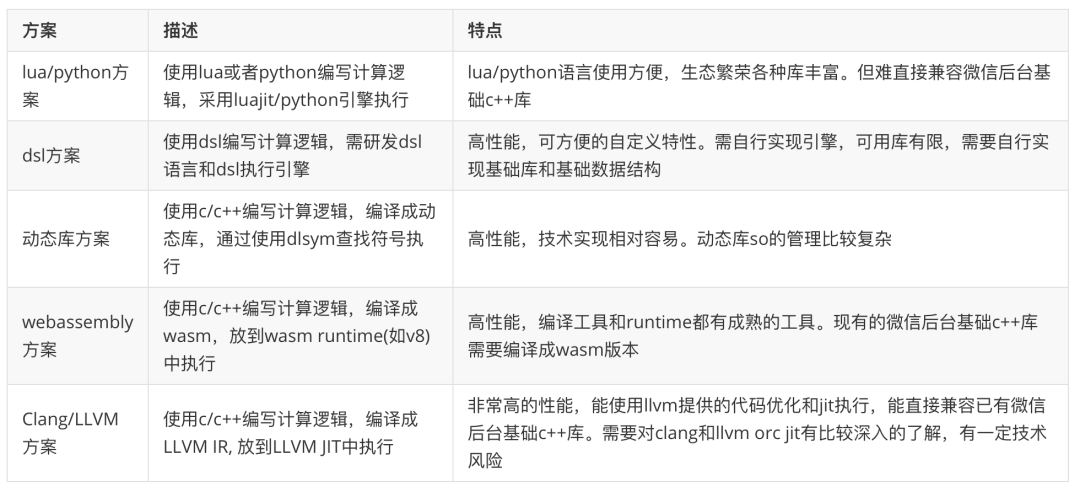
下面描述了各个方案并列出了各方案的特点:
微信安全采用的是一个自研的DSL引擎,并在此基础上扩展。原因是性能相对高,并且已被其他重要安全系统使用验证。
DSL(Domain-Specific Language)是用于特定领域的编程语言,例如SQL就是一种DSL。我们自研DSL引擎,实际上是开发了一种自定义的编程语言,使用这种编程语言来编写特征计算逻辑。要实现一种编程语言,当然要实现这种语言的编译器和执行器,下面将介绍DSL引擎的实现和存在的问题。
微信特征计算引擎:DSL引擎实现
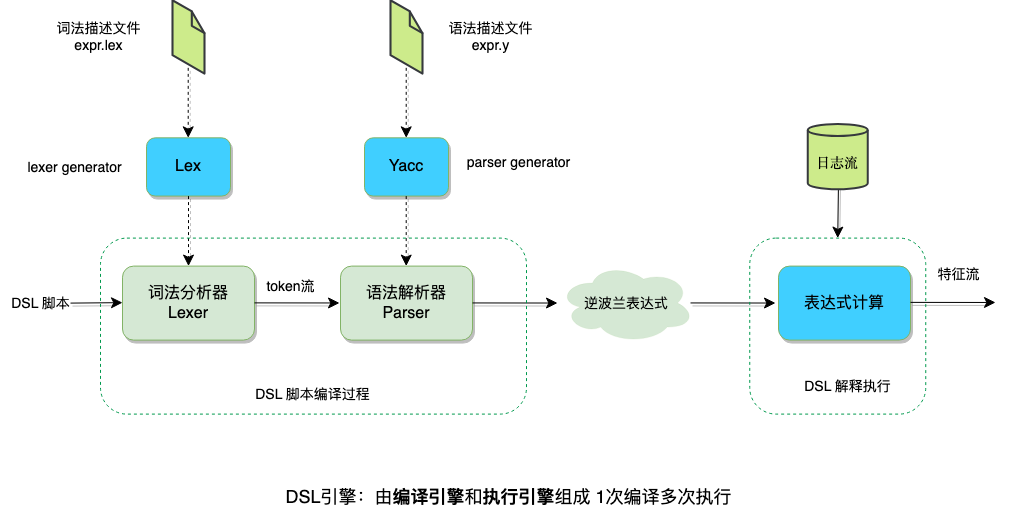
下图实现展示了微信自研DSL语言的实现,首先定义了词法描述文件和语法描述文件,采用 Lex 和 Yacc 生成词法分析器Lexer和语法解析器Parser, 在这里Parser的输出逆波兰表达式,存储在内存中,然后解释执行表达式。整个DSL的引擎可以分为2部分:编译和执行,编译1次,然后对每条输入数据解释执行编译后的表达式。
DSL引擎的问题
在业务接入和运营过程中发现3个主要的问题:
DSL新语言推广学习成本高
自研DSL是一门新的语言,业务不熟悉使用,业务同学从原来的C++开发计算特征,转为使用DSL,存在大量疑问,需要大量的研发支持, 尽管已经提供了丰富的文档支持。这无疑是公司内推广/公司外开源的阻碍,在缺少研发的大力支持下,大家愿意学习新的DSL语言吗?使用业务通用熟悉的语言,可以更好的提升影响力,减少接入阻碍,需要的研发支持也更少。
前面也提到特征计算系统采用的是一个自研的DSL引擎,并在此基础上扩展,为什么原来DSL语言不存在上述问题。因为原来DSL用于安全策略场景,主要是做逻辑判断和条件判断,例如支持+-*/和< = > if else 等简单操作即可,很容易上手,反而不需要复杂的语言特性。
但是特征计算场景,侧重于计算,需要大量的计算函数,库函数,rpc调用等,需要的语言语法特性复杂的多,因为扩展的DSL也变得复杂,由此诞生了上述的问题。

大量重复实现已有的库
实现一门可用性好的编程语言,除了实现语言本身,需要需要实现大量的基础库,例如需要实现字符串string库,http库,protobuf库,vector和map等数据结构,自研DSL也一样,需要耗费大量精力在重新实现这些库上,而且随业务需求还一直在更新,不能完备。并且自研的库函数使用风格也和C++库使用有较大差别,学习成本高。下面是DSL语言和库与C++的对比, 微信后台有成熟的C++基建,大家很熟悉C/C++语法。

其他方面的问题
DSL编译过程中无通用的中间表示,无法使用业界已有的程序优化算法,所以性能仍然不是很高。DSL的编译报错提示不友好不准确,因为语法解析器Parser采用的是Yacc工具生成,Yacc使用的是LALR算法, 该算法缺陷之一是编译报错提示不够准确友好,实际使用过程中也是如此,业务同学也是常咨询“这段DSL代码哪里错了?”。另外一个是扩展性较差,例如我们想基于DSL的parser 实现一个类似clangd的代码补全和提示工具,提升DSL脚本开发体验,几乎很难实现,因为DSL的编译器实现紧耦合没有模块化,我们只能基于很原始的字符串匹配来实现代码补全提示。

探索新引擎方案
C++执行引擎
微信后台主要使用C++作为编程语言,基础设施基本是以C++模块构建的,并积累了丰富的C++库。在安全业务中,一开始就选择了使用C++语言进行特征计算。如果将脚本语言也采用C++,业务同学可以熟练地使用,并且可以兼容现有的C++库和标准库,无需重新开发各种库。然而,C++是一种静态编译语言,是否能改为解释执行呢?我们进行了调研,并基于Clang前端和LLVM JIT技术实现了一个C++执行引擎,即一个C++解释器。其结构如下:
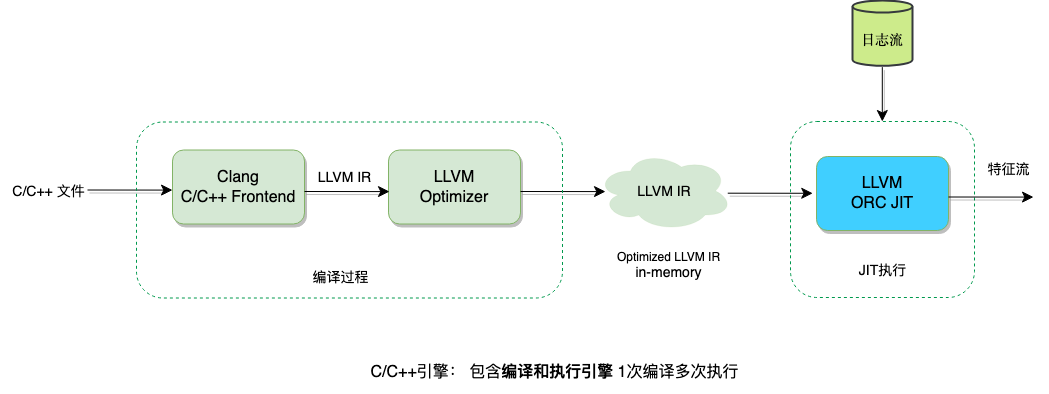
DSL引擎面对的问题C++引擎都可以完美的解决,C/C++语言容易接入学习成本低,开源易提升影响力;支持的库丰富无需重复开发;最好的LLVM编译优化和JIT执行带来了和二进制执行一样的高性能, 基于Clang前端因此有世界上最友好的C/C++编译报错提示,同样得益于Clang和LLVM模块话带来了极强的扩展性。

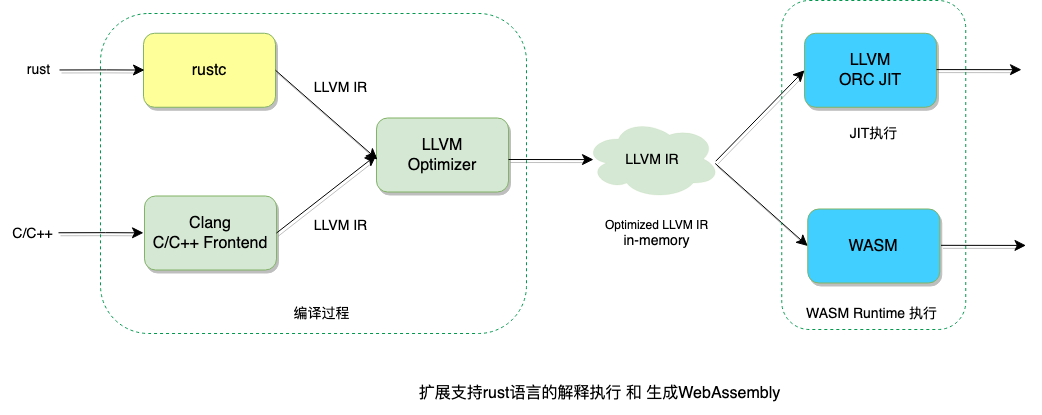
举几个例子说明C++引擎的扩展性,例如我们可以基于Clang 的前端库实现类型clangd的代码补全提示。采用这个结构还能快速的支持其他语言,例如rust语言作为开发语言;除了JIT执行,还能扩展生成WebAssembly,通过v8执行。
引擎实现:C/C++解释器ccint
C/C++是静态编译语言,但C/C++能否解释执行呢?答案是Yes,本文基于Clang和LLVM,不到500行代码,实现了C/C++解释器ccint,ccint源代码在GitHub可获取。其结构如下图所示:

C/C++文件被Clang前端经过预处理,词法分析,语法分析,语义检查,编译成LLVM中间表示,即LLVM IR。注意Clang前端并不是Clang二进制程序, 而是Clang编译器提供的前端库,LLVM IR经过LLVM优化器,根据优化级别生成优化后的LLVM IR存储在内存中, 常见的优化有常量传播,常量折叠,死代码删除,循环向量化等等。优化后的LLVM IR被 LLVM ORC JIT执行,输出结果。JIT的执行使用了LLVM后端代码生成技术,输入LLVM IR 输出二进制指令到内存,然后调用指定的函数符号执行。
使用ccint解释器输出"hello world"
/* main.cpp */#include#include#includevoid ccint_main() {std::vectorvec = {"hello", " world\\n"};for (auto &s : vec) {printf("%s", s.c_str());}}$ ./ccint main.cpphello world 上面的例子使用标准库的vector类和string类以及printf函数,解释器执行函数ccint_main, 可以看到解释器很好的支持了C/C++标准库。
ccint解释器还有有如下的特性

支持完整的C++11/C++14/C++17语法;支持标准库/动态库/静态库;采用了JIT技术因此和C/C++二进制有相同的性能;模块化编译和执行分离,方便使用到业务上。
ccint解释器 在GitHub 还有展示动态库静态库 和指定头文件搜索路径例子,可以参考。
ccint灵感来源于cling,cling是一个基于Clang和LLVM的交互式C/C++解释器,由欧洲核子研究中心开发,用于处理大型强子对撞机LHC的实验数据和验证实验模型,目前已处理EB级别的实验数据。然而直接使用cling并不必要,因为cling自身的代码已经达到了3万行以上,其中大部分代码是为了适配物理实验领域的需求。此外cling对Clang和LLVM进行了较大的修改,并未合并到LLVM主线,这将需要大量的后续维护投入。参考cling的实现思路,借助于Clang和LLVM这两个强大的工具,我们只需编写很少的代码(几百行)就能实现功能丰富的C/C++解释器。
后文将依次具体探讨实现C/C++引擎使用到的Clang前端技术。
初识LLVM
LLVM(Low-Level Virtual Machine)是一个编译器开发工具集,和虚拟机(Virtual Machine)没任何关系。
LLVM主要包括如下工具和库:一个源语言无关,目标架构无关的编译优化器,一个目标架构无关代码生成器,C/C++编译器Clang,LLDB调试器,LLD连接器,libc++库等,其中编译优化器和代码生成器是LLVM的核心。

为什么需要LLVM?LLVM解决了什么问题?
传统的结构是三段式,由前端,优化器,后端组成,并且紧耦合,如果新实现一个编程语言或者新增一个指令集ISA,都需要重新实现这三段,而且优化器不独立,程序优化即需要考虑语言特征,又需要考虑机器特性,难以专注优化算法本身。

LLVM将传统的三段式结构中优化阶段单独提取出来,并引入了一个通用的代码中间表示LLVM IR,这样前端研发人员只需要关注Source Code到LLVM IR的过程,专注前端的相关的算法 如新的parser算法和语义检查;而编译优化研发人员只需要专注优化算法的开发,因为中间表示LLVM IR和源代码无关,指令集架构ISA无关。后端研发只需要专注适配新的ISA,优化代码生成框架,优化指令选择,指令调度,寄存器分配等后端算法。大家术业有专攻,极大的繁荣了LLVM 生态。

如果需要研发新的编程语言,例如研发Rust语言,只需要研发语言的前端,就可以适配所有ISA。如果需要增加新的ISA,例如新指令集架构RISC-V, 只需要采用LLVM Target-Independent Code Generator 开发一个新的后端,RISC-V后端就可以支持所有的语言。如果需要新增新的编译优化算法,只需往Common Optimizer加入新算法,不需要了解语言特征,也不需要了解架构特性。

Clang
Clang是LLVM项目中一个C家族语言编译前端, 支持C, C++, Objective C/C++, OpenCL, CUDA等的编译,Clang的设计之初就注重模块化,各个子模块都提供了库,能基于这些库实现一些非常多个工具,如常用的C++代码linter工具clang-tidy 代码补全工具clangd,Clang的报错提示也非常的友好,这两方面相对GCC都有巨大的优势。
日常我们使用Clang包含两方面含义:Clang驱动器和Clang前端,后续将分别介绍这两方面内容,并重点讨论Clang前端。
Clang驱动器
日常使用的Clang工具就是一个驱动器,驱动整个编译的流水线,将C/C++编译成二进制,如下图Clang驱动Clang编译前端Frontend,汇编器Assembler, 连接器Linker等。

以一个例子说明
int factorial(int n) {if (n <= 1) return 1;return n * factorial(n - 1);}factorial.cpp
使用-ccc-print-phases打印各个阶段的内容,如下图编译文件factorial.cpp需要0~5总共6个阶段,0输入C++文件,1预处理,2编译预处理后的代码输出中间表示IR(Intermediate Representation), 3然后从IR生成汇编代码,4汇编器将汇编代码转成二进制目标代码,5链接器将目标代码链接成二进制。
$clang -ccc-print-phases factorial.cpp0: input, "factorial.cpp", c++1: preprocessor, {0}, c++-cpp-output2: compiler, {1}, ir3: backend, {2}, assembler4: assembler, {3}, object5: linker, {4}, image发现实际过程中Clang Driver会将各个阶段进行合并, 例如前5个阶段合并到clang-16程序执行,最后的链接ld单独执行。
$clang -### factorial.cppclang version 16.0.0"/usr/local/bin/clang-16" "-cc1" "-emit-obj" "-x" "c++" "factorial.cpp" ..."/usr/bin/ld" "--eh-frame-hdr" "-m" "elf_x86_64" "-o" "a.out" ...clang_main是Clang Driver主函数,定义在文件tools/driver/driver.cpp 中,如果我们分析Clang的执行流程,会发现有下面的调用栈

ExecutionAction字面意思是执行一个Action,什么是Action呢?
Action是一个编译步骤,对应Clang Driver流水线中的阶段,可参考Clang文档
整个Clang Driver流水线按从Action角度来看如下:
PreprocessJobAction: 将源码进行预处理
CompileJobAction :将预处理结果转为 LLVM IR(实际是IR的bitcode形式)
BackendJobAction:将LLVM IR 转为 汇编文件.s
AssembleJobAction: 将汇编文件.s转为二进制目标文件.o
LinkJobAction:将目标文件.o链接成可执行文件
上图的调用栈中cc1_main调用ExectueAction一个FrontendAction,FrontendAction代表Clang前端相关的阶段,下面介绍。
Clang前端
Clang前端是Driver的一部分也是编译的核心,Clang前端负责将输入的C/C++代码编译成中间表示IR(Intermediate Representation)
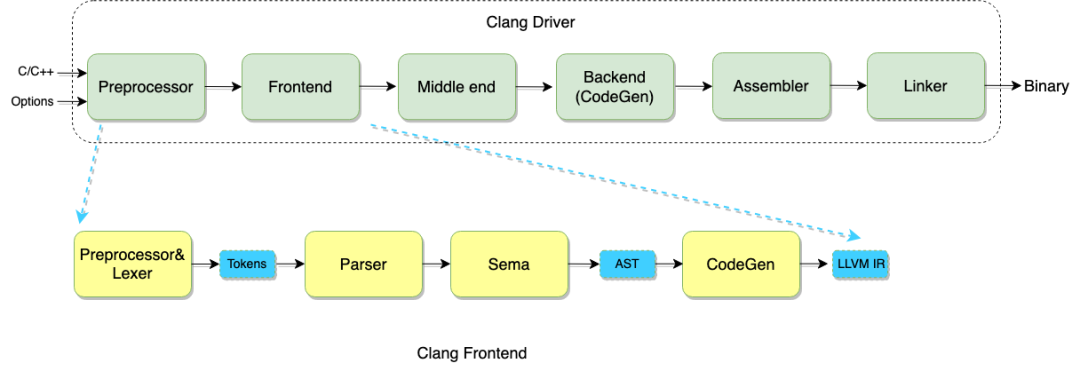
前端包括预处理/词法解析,语法解析,语义检查,代码生成子模块,Clang提供了命令行选项查看各阶段的输出内容:

Lexer词法解析
预处理Preprocessor和Lexer是组合一起的,Lexer输入C/C++源文件,输出Token流,查看Lexer的输出:
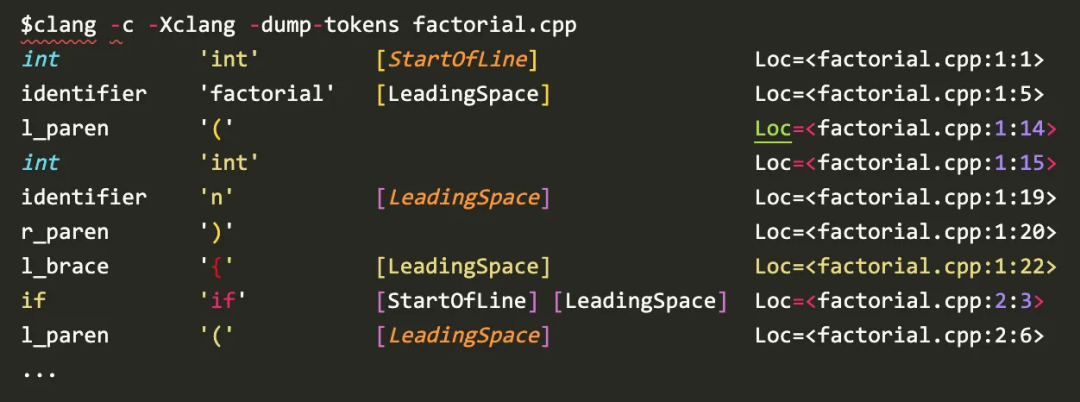
输出的Token包括类型和值, "factorial"的类型是identifier,值为"factorial";左括号类型是l_paren,值是"("。最右边Loc显示了Token在文件中的位置,其中"factorial"在第1行第5列。
Token定义在文件include/clang/Basic/TokenKinds.def 中
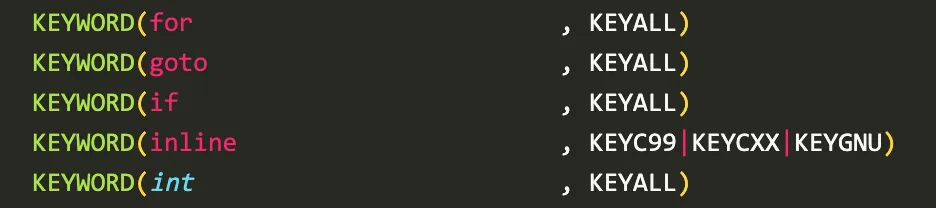
文件include/clang/Parse/Parser.h 中函数ConsumeToken和TryConsumeToken读取Token并前进到下一个Token:

Parser语法解析
Clang手写了一个递归下降的语法解析器,没有使用Bison等自动化Parser Generator工具等生成,原因是C++语法复杂,难以写成LALR形式,而且LALR Parser的编译报错信息不友好,这里有进行相关的讨论 the LALR grammar for C++。
"C++ grammar is ambiguous, context-dependent and potentially requires infinite lookahead to resolve some ambiguities"
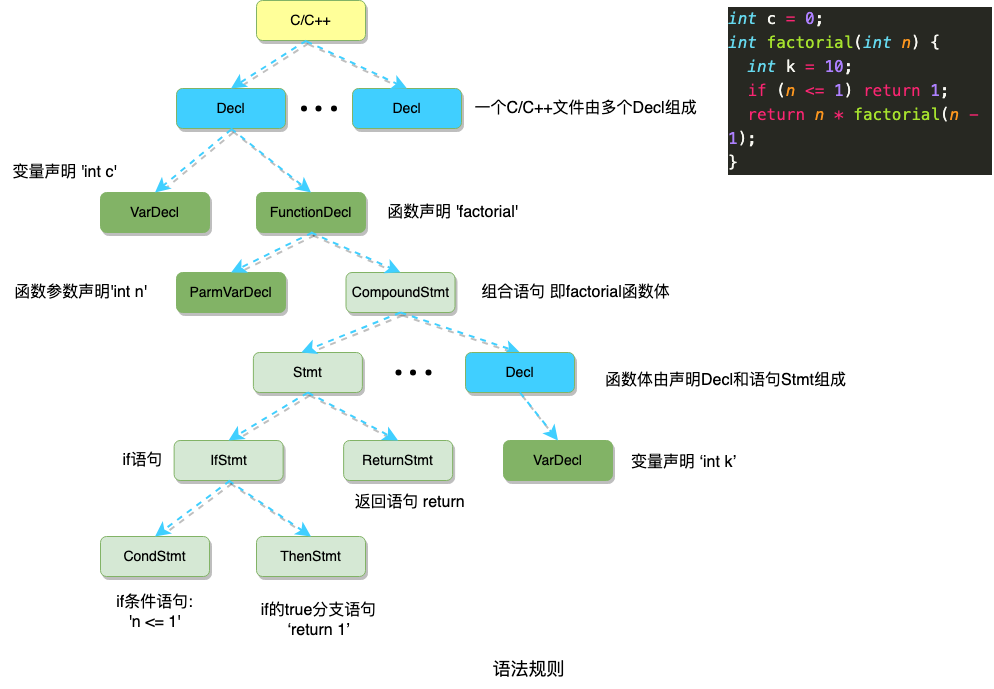
要了解语法分析的过程,就需要先了解语法的规则,以下图右侧代码说明,首先每个文件由一系列的申明Decl(Declaration)组成;这份代码包含2个声明:VarDecl变量声明和FunctionDecl函数声明,分别对应变量c和函数factorial;函数由参数列表和函数体组成,参数声明ParmValDecl对应参数int n,CompoundStmt组合语句就是对应函数factorial的函数体;函数体由一些列的声明Decl(Declaration)和语句Stmt(Statement)组成,factorial的函数体包含一个ValDecl变量声明,IfStmt if语句,ReturnStmt 返回语句,ValDecl变量声明对应局部变量 int k, 返回语句对应 最后的return,if语句则包含条件表达式语句CondStmt,True分支语句ThenStmt,False分支语句ElseStmt,因为代码中没有else语句块,所以图中未给出ElseStmt,显然if语句的条件表达式语句CondStmt对应n <= 1,True分支语句ThenStmt对应 return 1,这里还能继续往下分解语法规则,不再给出。
了解语法规则后,分析下语法解析的过程,下图展示了右侧代码的Parse过程,以解析其中 n <= 1为例输出函数调用栈Call Stack
调用栈20-15: 这5个函数是Clang Driver函数,其中clang_main是Clang Driver主函数,前面Clang Driver章节有说明。
调用栈14-10:ParseAST函数是整个Parser的入口函数,根据语法规则,文件由Decl组成,先解析Decl,然后递归下降解析到函数声明FunctionDecl,对应的函数是ParseFunctionDefinition,解析例子中的 int factorial (int ) {...}函数
调用栈8: 继续对函数定义FunctionDecl递归下降解析,函数定义由参数列表和函数体组成,函数体解析函数ParseCompoundStatementBody,解析例子中的函数factorial的函数体{...}
调用栈7:函数体由声明Decl和语句Statement组成,解析函数是ParseStatemenOrDeclaration,解析一个语句或者声明,该函数继续递归下降解析到函数体第一条语句
调用栈5: 函数体第一天语句是if语句,对应解析函数是ParseIfStatement,解析if (n <= 1) return 1语句,继续往下递归
调用栈4:if语句由条件表达式,true分支语句,false语句组成,首先解析条件表达式,条件表达式被括号包裹,形如"(expresiion)",所以这里调用的是ParseParenExprOrConditon,解析(n <= 1), 继续递归
调用栈3:调用ParseExpression解析表达式 n <= 1,继续递归
调用栈2:表达式Experssion类型特别多,这里n <= 1,是一个assignment expression,所以这里调用的是ParseAssignmentExpression,继续递归下降*
调用栈1: 表达式n <= 1由一个二元操作符*(Binay Operator)和两个操作数构成,左边操作数LHS(Left Hand Side)右边操作数RHS(Right Hand Side),表达式n <=1< em="">最终被解析到右边的操作数整型字面量1,对应的解析函数ParseRHSOfBinaryExpression

C++语法是知名的复杂...语言标准也是非常的厚...好在Clang代码结构比较清晰,可以对有兴趣的部分跟踪调试,这里只展示了冰山一角,还不到一角。
Sema语义检查
语义检查包括变量或过程未经声明就使用、变量或过程名重复声明、运算分量类型不匹配、操作符与操作数之间的类型不匹配。
Clang的语义检查与一般方法不同,常规方案方法是在生成抽象语法树AST之后,遍历AST进行检查。而Clang在AST节点生成过程中即时检查语义。语法分析Parser完成语句检查后,只表示语法正确,语义的正确性还需要检查,如操作符要求的操作数类型是否符合。
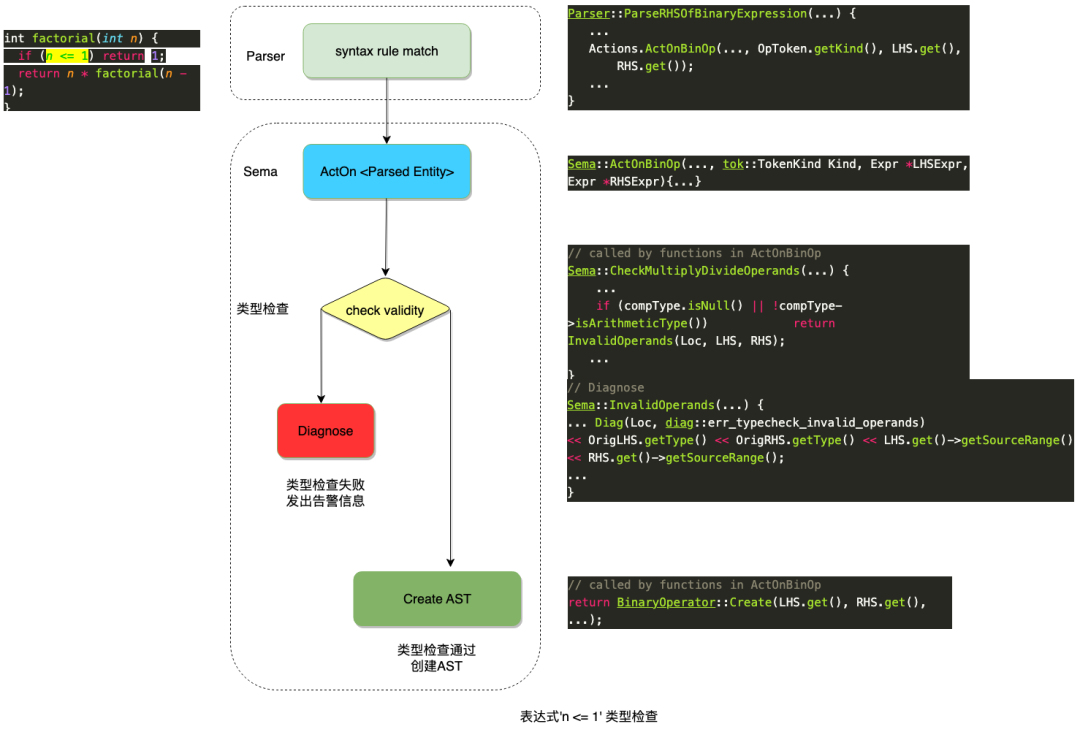
还是以if条件表达式 n <= 1为例,前一节语法分析的调用栈最后调用到了ParseRHSOfBinaryExpression函数,成功解析了表达式的RHS(Right Hand Side),这时候n <= 1的语法已经正确匹配,在准备构建抽象语法树AST前,先进入Sema模块进行语义检查,Parser和Sema之间的接口一般是ActOn,如图中的ActOnBinop,Sema模块的结构如下图,首先从语义角度检查程序正确性,n <= 1表达式需要左右操作数(n 和 1)类型都是Arithmetic Type,即char/bool/int/long等等。函数CheckMultiplyDivideOperands执行这样的检查,如果操作数类型不正确,将调用InvalidOperands,该函数进一步调用辅助函数Diag, Diag处理报错信息(error, warning, note),本节后续还会解析展开。如果语义正确,最后为这个Binary Expresion创建抽象语法树。
总结Sema模块的工作,如果语义检查不通过,就输出报错信息,通过就输出AST。
Clang Diagnose子系统用于处理和发生各种诊断信息给开发者。Diagnose子系统的调用来源主要是Sema模块,Sema通过辅助函数Diag 生成报错信息(Emit a diagnostic)。
下图中 编译这段有问题的代码,Clang输出报错信息。
信息主要由3部分组成:位置信息,如factorial.cpp:1:1 文件第1行第1列。严重等级: error, warning, note,图中是error,内容:*unknown type name "intt’。

诊断类型在文件include/clang/Basic/DiagnosticSemaKinds.td 中定义,上图unknown type name的定义如下:

Sema模块通过DiagnoseUnkownTypename函数(定义在lib/Sema/SemaDecl.cpp )发送err_unknown_typename类型的诊断信息,使用的是辅助函数Diag。

AST抽象语法树
Sema模块生成抽象语法树 AST (Abstract Syntax Tree)。和C/C++ 源代码相比,Clang AST 是更方便分析和操作的程序表示形式,同时 AST 节点还有源代码行列数等属性。AST结构也可轻易地转换回源代码,因此Clang AST特别适合用于进行静态代码分析、代码重构等工作,方便在C/C++源代码层级上进行分析和修改。
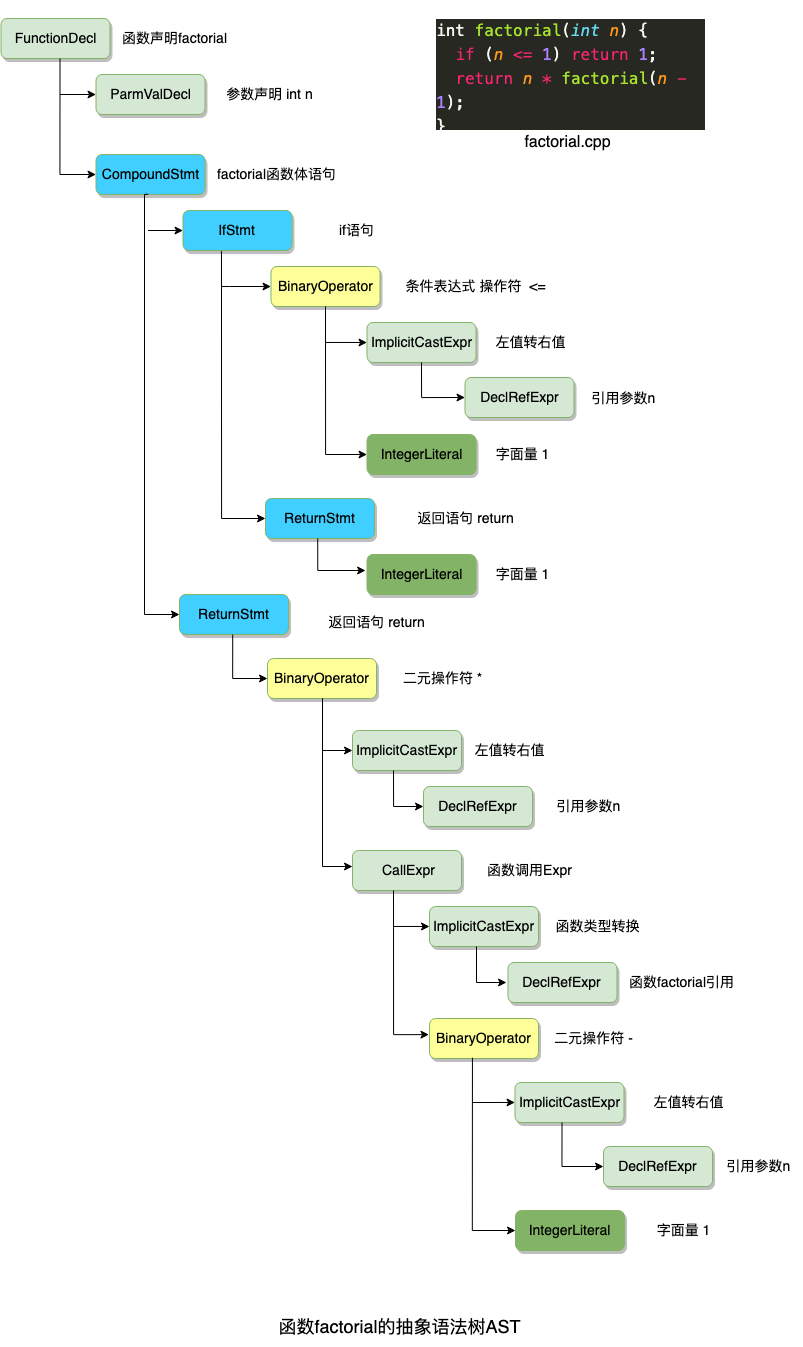
实际的代码产生的 AST结构非常复杂,我们可以先有个整体印象。

上图文件的AST结构如下:

从上图中可以看到,factorial.cpp文件整个内容称为是翻译单元TranslationUnitDecl, 文件只包含一个函数声明FunctionDecl,函数声明由参数声明ParmVarDecl和函数体语句CompoundStmt组成,函数体包括一个if语句IfStmt和返回语句ReturnStmt。
Clang AST中节点的类型主要是Decl(声明), Stmt(语句) 和 Type(类型), 以及它们的子类。
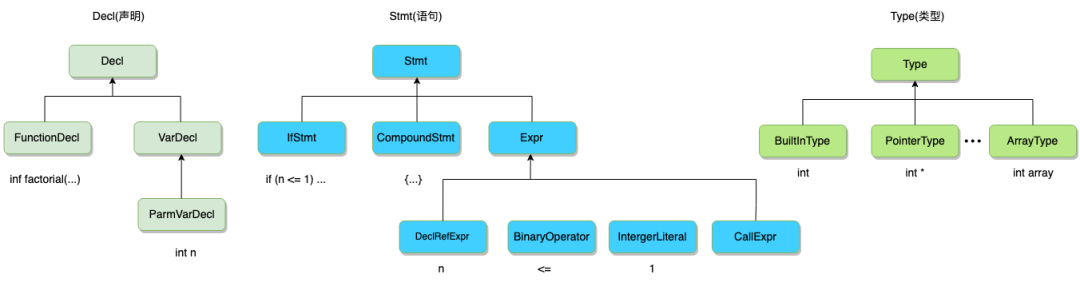
Dec(声明)
FunctionDecl(函数声明)
VarDecl(变量声明)
Stmt(语句)
DeclRefExpr(引用表达式)
BinaryOperator(二元运算符)
IntegerLiteral(整形字面量)
CallExpr(函数调用表达式)
ifStmt(if语句)
CompoundStmt(复合语句)
Expr(表达式)
Type(类型)
BuiltInType(内置类型)
PointerType(指针类型)
ArrayType(数组类型)
使用Clang的-ast-dump查看输出的AST的详细结构
clang -c -Xclang -ast-dump factorial.cpp输出如下:
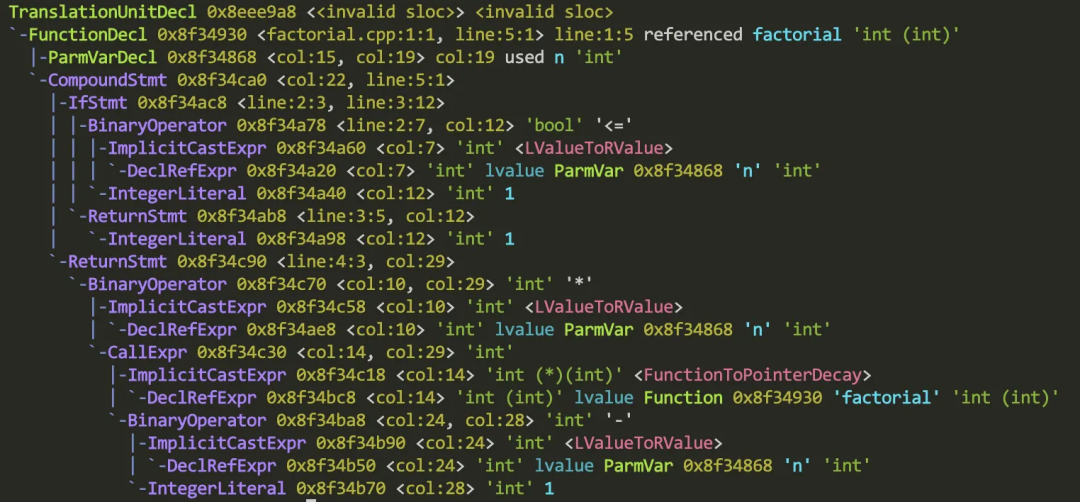
源代码对应的AST结构如图:
怎么访问/遍历/修改AST,如何基于Clang AST实现有趣的工具和功能呢,后面介绍基于Clang开始时展开。
CodeGen代码生成
CodeGen模块使用AST visitors以访问者模式(Visitor Pattern)遍历AST,然后使用IRBuilder类构建中间表示LLVM IR输出。

以构建if语句条件表达式 n <= 1的LLVM IR为例, CodeGen调用栈Call Stack如下:

调用栈19-15: 这5个函数是Clang Driver函数
调用栈13-12:AST的顶层节点是一个FunctionDecl,对应例子中的 int factorial (int ) {...}**函数,EmitGlobalFunctionDefiniton为函数factorial输出LLVM IR,递归访问FunctionDecl的AST子节点
调用栈10-8: 函数定义由参数列表ParmVarDecl和函数体CompoundStmt组成,EmitCompoundStmtWithoutScope为函数体构造输出LLVM IR,继续递归访问CompoundStmt的AST节点
调用栈7-6:为IfStmt构造输出IR,继续递归访问AST子节点
调用栈4: 为if语句的条件表达‘n <= 1’式构造输出IR ,继续访问AST子节点
调用栈3-2:构造二元运算符‘<=’的ir< p="">
调用栈1: 输出二元运算符‘<=’ 的操作数字面量1
使用Clang的-emit-llvm选项,可以查看输出的LLVM IR
clang -S -emit-llvm factorial.cpp后文将详细介绍CodeGen输出的LLVM IR结构
基于Clang的开发
Clang设计之初就被设计为一系列库。通过这一系列库,开发者可以实现各种各样强大的功能,玩转编程语言,本章介绍如何基于这些库做开发。
Clang开发示例
在探索Clang的过程中,本人收集和开发了一些Clang开发用例llvm-example,主要是AST的遍历和修改,可以通过GitHub获取代码,编译和运行。

基于Clang开发
执行下面的命令,使用-emit-llvm选项编译一个cpp文件到LLVM IR,Clang内部使用了哪些类和数据结构呢,执行流程是怎样的,如果我们想在这个编译流程上加上自定义的内容呢?
clang -S -emit-llvm factorial.cppClang的编译流程和数据结构设计,给开发这预留了大量的重写和自定义Hook的地方,下图展示了从cpp代码到LLVM IR的内部流程。
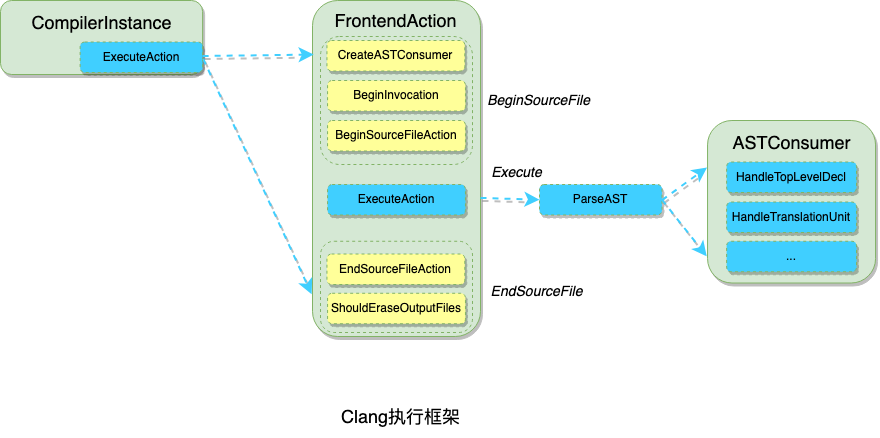
CompilerInstance类抽象Clang编译器,它描述了一个编译器的方方面面,包含了预处理Preprocessor,ASTContext(抽象语法树类),诊断类DiagnosticsEngine等等。编译器CompilerInstance对象使用ExecuteAction执行具体的前端动作FrontendAction,FrontendAction是前端动作的抽象类,开发者可以重写FrontendAction类的函数,执行自定义的操作。
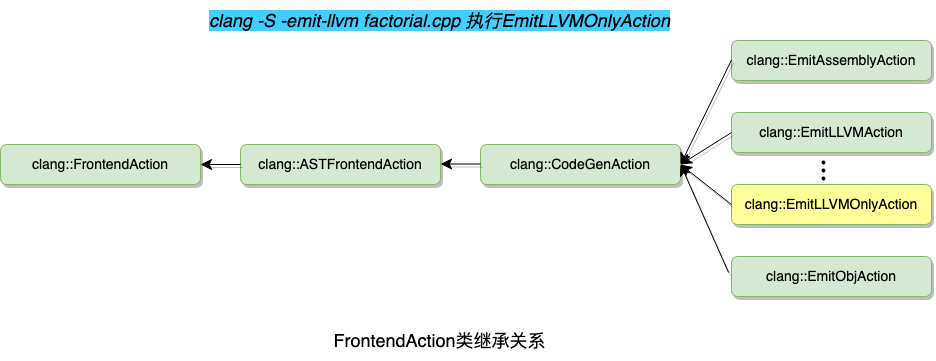
如果执行的是如下命令,Clang编译器具体执行的是EmitLLVMOnlyAction,上图可以看到它和FrontendAction的继承关系。
clang -S -emit-llvm factorial.cppEmitLLVMOnlyAction如它的名字含义一样,只输出LLVM IR,FrontendAction还有其他的子类实现,包括EmitAssemblyAction,Clang具体执行哪个由编译参数决定,参见代码lib/Frontend/CompilerInvocation.cpp 。

如果需要自定义实现FrontendAction,可以继承该类,并重写它的几个函数,实现需要的逻辑。

示例中clang-funcnames实现了自定义的MyFrontendAction。
ASTConsumer类是读取抽象语法树AST的基础类,也预留了大量函数给开发者进行重写,Clang里ASTConsumer也有多种子类实现如下图

使用-emit-llvm输出LLVM IR时, Clang使用的是BackendConusmer读取AST,同样如果自定义AST处理逻辑,可以重新它的如下等函数


示例中clang-funcnames实现了自定义的MyASTConsumer。
RecursiveASTVisitor访问处理具体AST节点的基础类,ASTConsumer使用它访问具体的语法树节点,它们之间的关系如下:
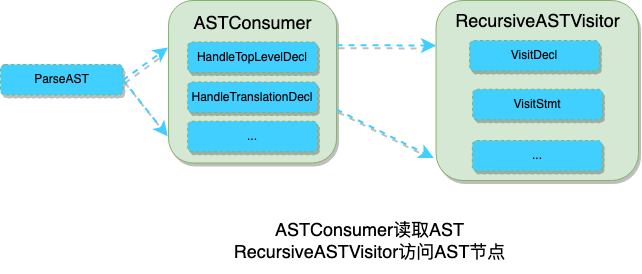
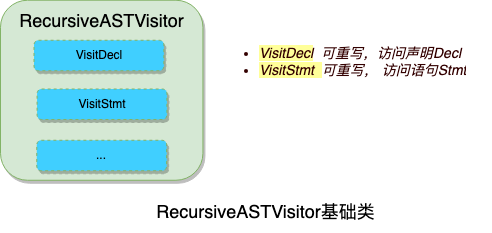
RecursiveASTVisitor提供了一些列处理AST节点的函数,如访问表达式VisitDecl和访问声明VisitDecl,都是可重写的函数:
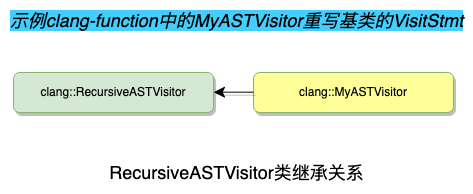
示例中clang-funcnames实现了自定义的MyASTVisitor:
总结下一下,如果使用Clang进行静态代码分析、代码重构等AST遍历和编辑工作,主要涉及的基础类是FrontendAction,ASTConsumer和RecursiveASTVisitor,这三个类非常的庞大,Clang文档给出了这些类的详细结构。这几个类的交互和基本使用方法可参考本人开发收集的Clang开发用例llvm-example。
写在最后
重新引用上图,实现特征计算引擎有多种方案可选,但没有一种方案能解决所有问题,每种方案都有各自的优劣。考虑到微信后台主要使用C/C++语言,因此采用C/C++语言的WebAssembly方案和类C/C++语言的DSL是不错的选择,结合Python和Lua完全能满足业务需求。本文通过探索C/C++解释执行,提出了一种基于Clang/LLVM的方案,具有高性能且能与微信C/C++基建良好兼容,值得进一步研究。
参考资料:
ccint - a C/C++ interpreter, built on top of Clang and LLVM compiler
声明:本文来自腾讯技术工程,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
