2023年9月19日,Anthropic发布了负责任扩展策略(Responsible Scaling Policy, RSP),成为第一个发布RSP的前沿AI研发机构。Anthropic的全球事务主管Michael Sellitto也受邀参加了安远AI联合举办的“前沿人工智能安全与治理”分论坛,解读了Anthropic的RSP。
RSP框架由METR(原ARC Evals)提出,被认为是降低AI灾难性风险最有前途的方法之一,因其提供了:
一个务实的中间立场(在认为AI极其危险需暂停和担心AI灾难性风险为时过早之间,且基于评测而非猜测)
了解优先考虑哪些保护措施(从以谨慎为导向的原则转向为继续安全研发所需的具体承诺,如信息安全、拒绝有害请求、对齐研究等)
基于评测的规则和规范(可能包括标准、第三方审核和监管,自愿的RSP可为流程和技术提供测试平台,有助于未来基于评估的监管)
随着OpenAI在2023年12月18日发布了近似RSP的“准备框架测试版”Preparedness Framework (Beta),相信会有更多前沿AI研发机构采用该实践制定自己的RSP。
安远AI近期发布的《前沿人工智能安全的最佳实践——面向中国机构的研发实践案例与政策制定指南》中,也对RSP进行了详细的介绍,欢迎阅读!
感谢Alexa Pan和Qingyuan Lu对于本篇内容的贡献。
Anthropic发布的负责任扩展策略(RSP),是其采用的一系列技术和管理流程,旨在帮助管理开发能力日益增强的AI系统的风险。
随着AI模型的能力越来越强,Anthropic认为它们将创造可观的经济和社会价值,但也可能引发愈发严重的风险。他们的RSP专注于灾难性风险——即AI模型直接导致大规模破坏的风险。此类风险可能来自对模型的故意滥用(例如恐怖分子或国家利用模型来制造生物武器),也可能来自那些通过自主行动方式违反设计者意图而造成破坏的模型。

Anthropic的RSP明确了一个名为AI安全级别(ASL)的框架,用以应对灾难性风险。这一框架大致是参照处理危险生物材料的生物安全级别(BSL)标准而设计的。基本思想是要求与模型潜在的灾难性风险相适应的安全、安保和操作标准,更高的ASL级别需要越来越严格的安全证明。
ASL系统的简要概述如下:
ASL-1是指基本不会造成灾难性风险的系统,例如一个2018年的大型语言模型或一个只会下国际象棋的AI系统。
ASL-2是指显示出危险能力的早期迹象的系统,例如有能力提供制造生物武器的方法的模型,但这些信息由于可靠性不足或无法超越搜索引擎能提供的信息而没有太多用处。目前的前沿大型语言模型(包括Claude)似乎是ASL-2。
ASL-3是指与非AI基线工具(例如搜索引擎或教科书)相比显著增加灾难性误用风险或显示出低级自主能力的系统。
ASL-4及更高版本(ASL-5+)尚未定义,因为它距离现有系统太远,但可能会涉及灾难性误用风险和自主性的质变升级。
完整文档中详细描述了每个ASL级别的定义、标准和安全措施,但就较高层面而言,ASL-2措施代表了当前的安全标准,并且与2023年7月的前沿AI企业白宫承诺有很大的重合。ASL-3措施包括更严格的标准,还需要进行大量的研究和开发工作才能及时满足这些标准,例如异常严格的安全要求,以及承诺如果ASL-3模型在对抗性测试中表现出任何有意义的灾难性误用风险,则不会部署该ASL-3模型(这与仅仅承诺执行红队对抗性测试形成对比)。Anthropic尚未编写ASL-4措施(但承诺会在达到ASL-3之前编写),但这些措施可能需要一些今天仍不清楚的保障方法,例如使用可解释性研究的方法从机制上证明模型不太可能做出某些灾难性行为。
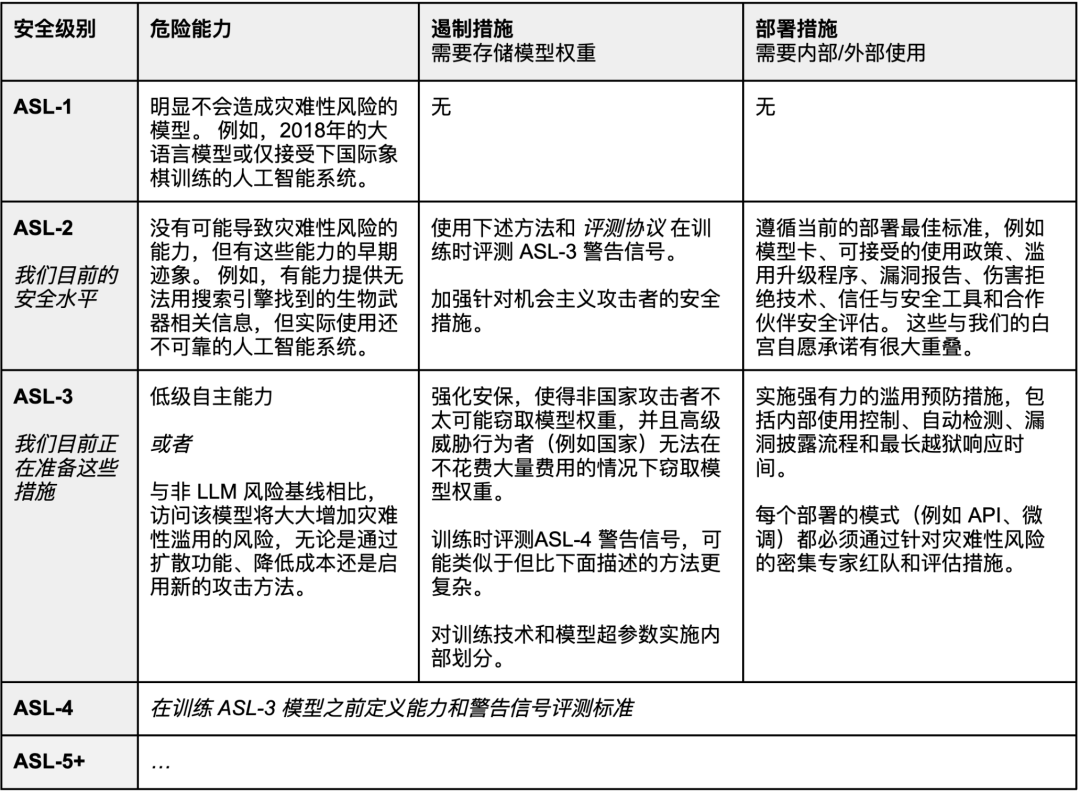
注:人工智能安全级别框架的简要可视化。所有安全措施都在前一级别之上累积
Anthropic设计ASL系统是为了在有效针对灾难性风险和激励有益应用与安全进步之间取得平衡。一方面,如果AI的扩展超出了遵守必要安全程序的能力,ASL系统隐性要求暂停更强大模型的训练。但RSP是直接激励他们为实现进一步的扩展而解决必要的安全问题,并允许他们使用先前ASL级别中最强大的模型作为开发下一个级别的安全功能的工具。如果前沿实验室广泛采用该标准,Anthropic希望它能直接激励研究者们解决安全问题并力争上游。
在评估流程上,Anthropic不会立即尝试定义所有未来的ASL及其安全措施(这几乎肯定经不起时间的考验),而是采取迭代承诺的方法。他们现在定义ASL-2(当前系统)和ASL-3(下一个风险级别),并承诺在达到ASL-3之前定义ASL-4,依此类推。

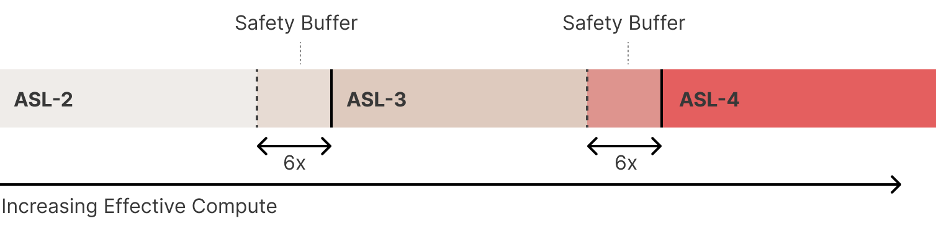
注:随着有效算力的增加,在前进到更高层级的ASL前,必须以安全缓冲来建立明晰的边界
确保其训练的模型永远不会越过ASL评估阈值是一项艰巨的任务。模型以离散大小进行训练,需要在训练中期进行评估,而认真、有意义的评估可能非常耗时,因为它们可能需要进行微调。
这意味着当打算避免达到ASL阈值时,存在实际上超越了该ASL阈值的风险。Anthropic通过创建缓冲区来减轻这种风险:他们设计ASL评估时特意使其在比所关注的能力水平略低的能力水平上触发,同时确保按照定义的定期间隔进行评估(具体来说,每当如下定义的有效计算增加4倍就会进行评估),以限制超越量。Anthropic的目标是将安全缓冲区的大小设置为6倍(大于4倍评估间隔),以便在进行评估时可以安全地继续模型训练。由于缓冲区的设置,正确执行该方案将导致他们训练的模型勉强通过ASL-N测试,仍然略低于他们实际关注的阈值。此时,他们暂停该模型的训练和部署,除非相应的安全措施已准备就绪。
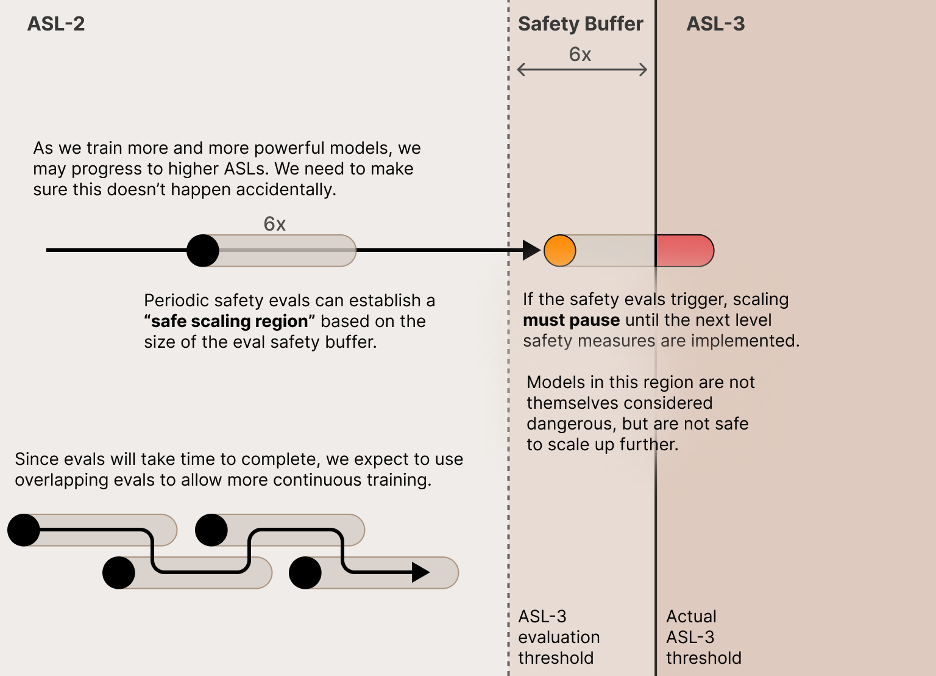
随着训练越来越强大的模型,可能会进步到更高的ASL,需要确保没有意外发生。
定期安全评估可以根据评估安全缓冲区的大小建立“安全扩展区域”。
由于评估需要时间才能完成,因此希望使用重叠评估来允许更连续的训练。
如果触发安全评估,则扩展必须暂停,直到实施下一级安全措施。
该区间的模型本身并不被认为是危险的,但如果进一步扩大规模,则有可能有安全风险。
从商业角度来看,Anthropic想明确的是RSP不会改变Claude的当前用途或影响其产品的可用性。相反,它应该被视为类似于汽车或航空产业中进行的市场测试和安全特性设计,目标是在产品投放市场之前严格展示其安全性,这些做法最终将使用户受益。
Anthropic的RSP已经得到了董事会的正式批准,任何变更必须在与长期利益信托(Long Term Benefit Trust)进行协商后由董事会批准。在完整的文件中,他们描述了一些程序保障措施,以确保评估过程的完整性。
同时,这些承诺是他们目前的最佳预计,是即将更新的初步迭代。与相对稳定的BSL系统不同,AI领域的快速发展和许多不确定性意味着快速的迭代和路线修正几乎是必然的。
Anthropic希望它能为政策制定者、第三方非营利组织和面临类似部署决定的其他公司提供有用的启示。
查看Anthropic 的负责任扩展策略的完整文档:https://www-files.anthropic.com/production/files/responsible-scaling-policy-1.0.pdf
声明:本文来自安远AI,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
