阿里妹导读:借助阿里知识图谱的建设,阿里电商平台管控从过去的“巡检”模式升级为发布端实时逐一检查。在海量的商品发布量的挑战下,最大可能地借助大数据、人工智能阻止坏人、问题商品进入阿里生态。同时面临问题商家实时的对弈、变异和恶意攻击等诸多挑战,知识图谱仍然保持着每天千万级别的拦截量,亿级别的全量智能审核次数,在滥发、侵权、合规、假货、经营范围等多个场景全面与问题卖家正面交锋,实时对弈。为了最大限度地保护知识产权,保护消费者权益,我们对知识图谱推理引擎技术提出了智能化、自学习、毫秒级响应、可解释等更高地技术要求,实现良好的社会效益。
作者:览图&陈华钧&卡方

阿里知识图谱运用
阿里巴巴生态里积累了海量的商品数据,这些宝贵的商品数据来自于淘宝、天猫、1688、AliExpress等多个市场,同时品牌商、行业运营、治理运营、消费者、国家机构、物流商等多种角色参与其中,贡献着校正着这样一个庞大的商品库。无论是知识产权保护,还是提升消费者购物体验,实现商品数据的标准化(商品规范的统一和商品信息的确定性), 以及与内外部数据之间的深度互联,意义都非常重大,阿里商品知识图谱承载着商品标准化这一基础性,根源性的工作。 基于此,我们才能知道哪些商品是同样一件产品,我们才能确切地知道一个品牌是否被授权,品牌下的产品卖到了哪些市场。
阿里知识图谱以商品、标准产品、 标准品牌、 标准条码、标准分类为核心, 利用实体识别、实体链指和语义分析技术,整合关联了例如舆情、百科、国家行业标准等9大类一级本体,包含了百亿级别的三元组,形成了巨大的知识网。
阿里知识图谱综合利用前沿的NLP、语义推理和深度学习等技术,打造全网商品智能服务体系,服务阿里生态中的各个角色。商品知识图谱广泛地应用于搜索、前端导购、平台治理、智能问答、品牌商运营等核心、创新业务。能够帮助品牌商透视全局数据,帮助平台治理运营发现问题商品,帮助行业基于确定的信息选品,做人货场匹配提高消费者购物体验等等。为新零售、国际化提供可靠的智能引擎。
引入机器学习算法搭建推理引擎
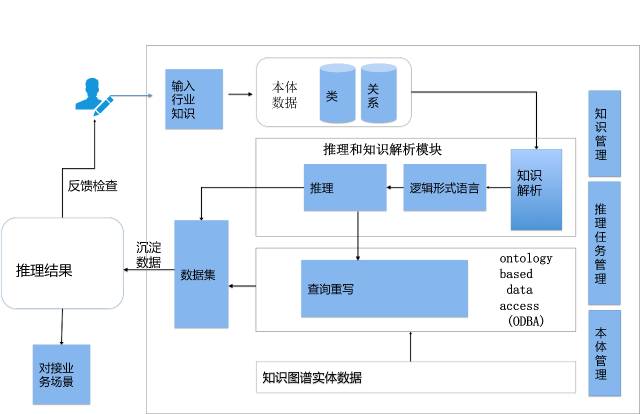
我们设计了一套框架来实现知识表示和推理。此外:知识图谱实体、关系、词林(同义词、上下位词)、垂直知识图谱(例如地理位置图谱、材质图谱)、机器学习算法模型等都纳入进来做统一的描述。
按照不同场景,我们把推理分为:上下位和等价推理;不一致性推理;知识发现推理;本体概念推理等。例如
1. 上下位和等价推理。检索父类时,通过上下位推理把子类的对象召回,同时利用等价推理(实体的同义词、变异词、同款模型等),扩大召回。 例如,为保护消费者我们需要拦截 “产地为某核污染区域的食品”,推理引擎翻译为 “找到产地为该区域,且属性项与“产地”同义,属性值是该区域下位实体的食品,以及与命中的食品是同款的食品”。
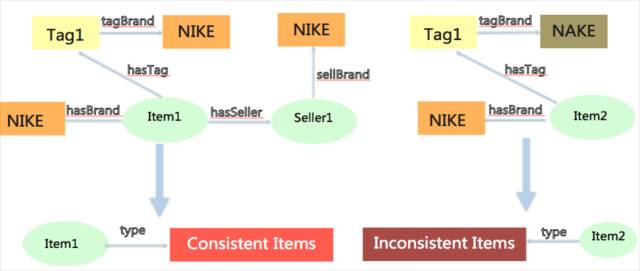
2. 不一致推理。在与问题卖家对弈过程中,我们需要对商品标题、属性、图片、商品资质、卖家资质中的品牌、材质、成分等基础信息,做一致性校验。比如说标题中的品牌是Nike而属性或者吊牌中品牌是Nake,如下图所示,左边描述了商品标题、属性、吊牌上的品牌信息是一致的,推理为一致。右边为吊牌和商品品牌不一致的商品,被推理引擎判断为有问题的商品。
3. 知识发现推理。一致性推理的目的是确保信息的确定性,例如通过一致性推理我们能确保数据覆盖到的食品配料表正确。但消费者购物时很少看配料表那些繁杂的数字。消费者真正关心的是无糖、无盐等强感知的知识点。为了提高消费者购物体验,知识发现推理通过底层配料表数据和国家行业标准例如:
无糖:碳水化合物≤ 0.5 g /100 g(固体)或100 mL(液体)
无盐:钠≤5mg /100 g 或100 mL我们可以把配料表数据转化为“无糖”“无盐”等知识点。从而真正地把数据变成了知识。通过AB test验证,类似知识点在前端导购中极大地改善了消费者购物体验。推理引擎背后技术框架
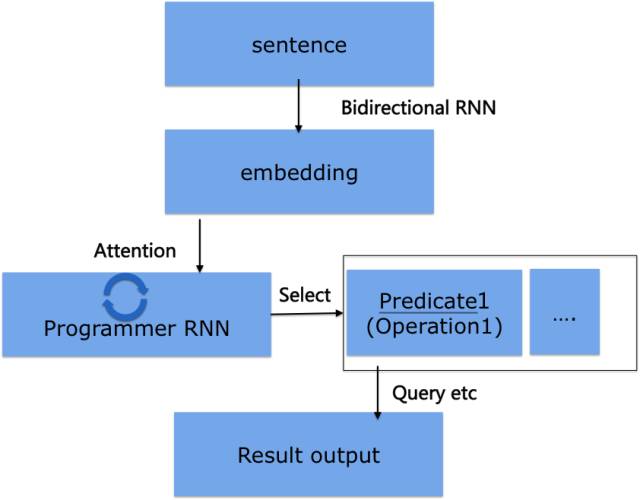
首先,推理引擎把自然语言通过语义解析(semantic parsing)转换为逻辑表达式(logical form)。语义解析采用了结合神经网络和符号逻辑执行的方式:自然语言经过句法、语法分析、 NER、 Entity Linking, 被编码为分布式表示(distributed representation),句子的分布式表示被进一步转义为逻辑表达式。
在分布式表示转换为逻辑表达式的过程中,我们首先面临表示和谓词逻辑(predicate)操作之间映射的问题。我们把谓词当做动作,通过训练执行symbolicoperation,类似neural programmer中利用attention机制选择合适的操作,即选择最有可能的谓词操作,最后根据分析的句法等把谓词操作拼接为可能的逻辑表达式,再把逻辑表达式转换为查询等。过程示意如下图所示。
其次,逻辑表达式会触发后续的逻辑推理和图推理。逻辑表达式在设计过程中遵循以下几个原则:逻辑表达式接近人的自然语言,同时便于机器和人的理解。表达能力满足知识图谱数据、知识表示的要求。应该易于扩展,能够非常方便的增加新的类、实体和关系,能够支持多种逻辑语言和体系,如Datalog、OWL等,即这些语言及其背后的算法模块是可插拔的,通过可插拔的功能,推理引擎有能力描述不同的逻辑体系。
以上下位和等价推理为例:“产地为中国的食品”,”
用逻辑表达式描述为:
∀x: 食物(x) ⊓ (∀ y: 同义词(y,产地)) (x, (∀ z: 包括下位实体(中国, z)))
随后找同款:
∀t, x: ($ c:属于产品(x, c) ⊓属于产品(t, c))
此外,推理引擎还用于知识库自动补全。我们基于embedding做知识库补全。主要思路是把知识库中的结构信息等加入embedding,考虑了Trans系列的特征,还包括边、相邻点、路径、实体的文本描述 (如详情)、图片等特征,用于新关系的预测和补全。
阿里知识图谱经过我们三年的建设,已经形成了巨大的知识图谱和海量的标准数据,同时与浙江大学陈华钧教授团队成立联合项目组,引入了前沿的自然语言处理、知识表示和逻辑推理技术,在阿里巴巴新零售、国际化战略下发挥着越来越重要的作用。
有关知识图谱技术交流,或有意加入我们,欢迎联系张伟 (览图):
lantu.zw@alibaba-inc.com

张伟 (花名:览图)博士, 阿里巴巴知识图谱团队负责人。博士毕业于新加坡国立大学,本科毕业于哈尔滨工业大学。曾任职新加坡资讯通信研究院自然语言处理应用实验室主任。
声明:本文来自阿里技术,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
