
原文标题:Interpreting Unsupervised Anomaly Detection in Security via Rule Extraction
原文作者:Ruoyu Li, Qing Li, Yu Zhang, Dan Zhao, Yong Jiang, Yong Yang发表会议:NIPS2023原文链接:https://nips.cc/virtual/2023/poster/69885主题类型:AI技术于网络安全应用笔记作者:jifengzhu主编:黄诚@安全学术圈
背景和动机
近年来,机器学习 (ML) 和深度学习 (DL) 彻底革新了许多安全应用,例如网络入侵检测和恶意软件识别等,使其准确性和泛化性均优于传统方法。其中,基于无监督的异常检测是一种具有前景的方法,它主要通过对常态偏离的感知来检测恶意活动。与监督方法相比,这类方法在安全应用中具有以下优势:1)其在训练过程中几乎不需要标记的攻击/恶意数据(即零正样本学习),尤其考虑到恶意样本通常更加稀疏且难以获得;2)不需要拟合于已知的威胁,从而能够更好地对未知攻击/零日攻击进行检测。
然而,ML/DL模型通常具有较强的黑盒属性,无法直接解释和理解其决策过程。我们认为,对黑盒模型的全局解释,特别是使用规则提取来表征整个决策边界,对安全系统的实际应用是非常有帮助的,尤其可以提供以下两点益处:
提升对高风险决策的信任。当前,为了最大限度地减少错误和控制损失,安全管理员更倾向于信任人类可理解的规则而非不直观的输出,例如来自复杂黑盒模型的简单标签和数值输出。
与在线防御系统的集成。将黑盒模型解释为高保真的规则,可以使其与大多数基于规则表达的防御工具(例如iptables、Snort等)高耦合集成,从而实现全流程高效的在线防御。
现有的全局解释方法大多是针对有监督模型提出的,而关于解释无监督异常检测的研究仍然有限,主要由于以下几点挑战仍未解决:
现有的解释方法往往同时需要大量有标记的正样本和负样本来确定黑盒模型的决策边界,但这一要求与无监督异常检测其本身不需要标记攻击样本的天然优势背道而驰;
全局解释方法通常使用自身可解释的模型来模仿黑盒模型的决策结果(如决策树和线性模型),但这些模型都是有监督模型,目前仍缺少一种合适的无监督代理模型能够同时满足自我可解释性和在安全应用中的良好性能;
全局解释方法的一个常见问题是代理模型由于其简单的结构往往会出现准确度的显著损失,它们虽然可以提供一定程度的模型解释,却无法满足安全应用在线部署中对高检测精度的需求。
研究方法
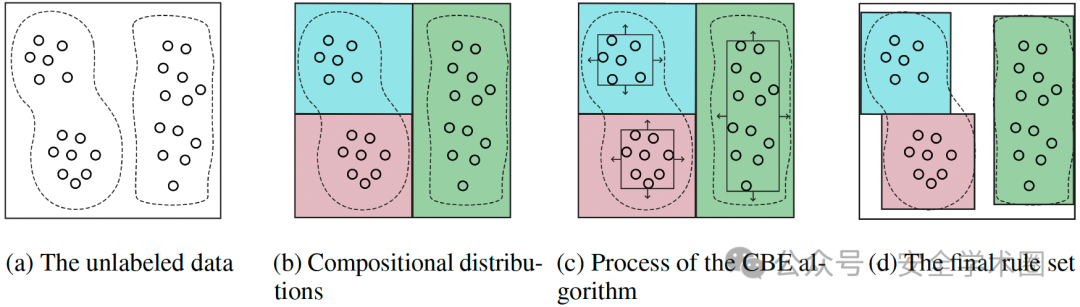
本文所提出的方法是基于以下的直觉和观察:自身可解释模型无法有效代理黑盒模型的一个重要原因是它们无法有效地拟合高维空间中的复杂数据分布。具体来说,即使只有正常行为的数据,其可能也是由多个分布叠加而成的,即整体分布是由多个组成分布(compositional distribution)构成。例如,一台主机的正常活动可能由其所支持的多种不同目的的服务构成(如web、数据库、邮件系统等),它们在特征空间上可能呈现出相当大的差异,并且位于特征空间中的不同区域,区域之间几乎没有过渡,因此难以找到统一的规则集来准确估计原始模型(效果如图1a所示)。
基于这种直觉,我们提出了一种基于分治思想的规则提取方法。首先,我们定义了规则提取中涉及的两类规则,分别为“分布分解规则”和“边界推理规则”。其中,分布分解规则用于将整体分布分解为多个组成分布,边界推理规则用于在每个组成分布上拟合原黑盒模型的决策边界。为了获取分布分解规则,我们提出了一种内部聚类树模型(IC-Tree),它可以将特征空间切割成子空间,使每个子空间包含属于相同组成分布的数据(效果如图1b所示)。IC-Tree训练流程与标准的决策树类似,其不同在于IC-Tree不需要基于真实标签来分割训练数据,而是使用原黑盒模型输出的其为正常行为的概率作为分割标准,使其能够以完全无监督的方式运作。最终,一棵拥有K个叶子结点的IC-Tree可以表示K个组成分布,我们可以通过从根节点到一个叶子结点k路径上的各节点分割条件的逻辑与得到一条分布分解规则,即:
\\} " data-formula-type="block-equation" >
然后,我们设计了一个组成边界探索算法(CBE algorithm)来探索每个组合分布的决策边界(效果如图1c所示)。对于IC-Tree叶子结点划分的某一个子空间,CBE算法首先使用一个可以包含该子空间内所有正常数据点的最小超立方体(minimal hypercube)作为基准规则。之后,CBE算法在超立方体的各个超平面上进行基于均匀分布的随机采样得到初始探索点(initial explorer),再通过对每一个初始探索点进行基于截断正态分布的随机采样得到附属探索点(auxiliary explorer)。我们使用原黑盒模型对这些附属探索点进行判断其是否为异常数据,使用束搜索(Beam Search)找到异常置信最高的数据点集合作为候选探索点。直觉上,它们的采样位置代表了探索方向更加接近原黑盒模型决策边界的方向。为了加速对这些方向的探索,我们设计了一种适用于黑盒场景的快速梯度下降估计法来计算下一轮迭代时所使用的初始探索点,直到找到稳定的黑盒模型决策边界。最后,CBE算法使用最小超立方体的规则和各个超平面上的探索规则的逻辑或作为最终的边界推理规则。整个流程由如下算法描述:

最终,通过合并各组成分布的分布分解规则和边界推理规则,可以得到全局逼近原黑盒模型的规则集(效果如图1d所示)。
实验结果
我们采用了3个常用的网络入侵检测基准数据集,并在每个数据集上训练了4种不同的无监督异常检测模型作为黑盒模型,最后对这些模型进行规则提取并与5个现有规则提取方法在4个指标上进行对比,包括保真度、鲁棒性、真阳率和真阴率。如下表所示,该方法在所有检测模型和数据集上均取得最高的保真度和真阳率,同时保持了高水准的鲁棒性和真阴率,说明该方法可以较好的使用特征规则来表达出原黑盒模型复杂的决策逻辑,保证了其对无监督黑盒模型全局解释的正确性。
表1: 在不同数据集和不同黑盒模型上规则提取的效果对比

为了理解黑盒模型的决策,我们从训练好的模型提取规则并使用规则集判断四种类型的攻击。在表2中,我们展示了攻击所违反的规则(即正常行为阈值)、攻击样本在该特征的数值以及对该攻击常用的专家知识判断。例如,DDoS(分布式拒绝服务)攻击的数据无法匹配数据包大小平均值、数据包到达时间平均值和连接持续时间三个特征维度的规则,其特征值明显低于规则阈值。由于DDoS攻击的目的是耗尽受害者的资源,攻击者常使用资源消耗不对称(例如使用小包、SYN包)、极高发包速率、建立尽可能多的无用连接等手段。可以发现,规则所提供的解释符合人类识别攻击数据的主要特征,从而可以帮助安全管理员理解和信任黑盒模型的决策过程。
表2: 在四种类型攻击上的解释样例

考虑到获得绝对无噪声的训练集需要大量人力且不切实际,我们评估了该方法在不同比例的噪声数据下的有效性。我们使用两种注入噪声数据的方法来评估提取规则的保真度:1)随机噪声;2)来自其他类别的错误标记数据(即攻击数据)。如表3所示,我们发现噪声数据比例的影响并不显著:表中40个保真度分数中有36个保持在0.95以上,并且在大多数黑盒模型上保真度分数随着噪声数据的增加变化并不明显。这表明我们的规则提取方法可以保留与其提取的黑盒模型相似的性能。然而,iForest的结果也表明,足够大比例的噪声数据可能会对某些模型的规则提取造成一定的负面影响。
表3: 提取规则的保真度受噪声训练数据的影响

我们还评估了该方法在训练(即规则提取)和预测时的计算成本。由于所使用的数据集共有80个特征,我们使用4000个样本的前20、40、60和80个特征来训练模型以研究特征大小的影响,结果如表4所示。可以看出,该训练时间对于大规模规则提取是可以接受的。此外,训练时间随着特征维度的增加基本线性增加。对于预测时间开销,该方法是非常高效的,单次推理仅花费微秒级的开销。这表明,作为一种基于规则的方法,我们的方法可以完美适配现有的高性能系统完成在线部署的实时推断。
表4: 样本平均训练时间和推断时间受特征维度的影响

总结
在本文中,我们提出了一种全局解释黑盒无监督异常检测模型的新方法,引入了两种类型的规则以及相应的算法来提取这些规则。评估表明,我们的方法在各种指标方面均优于先前的工作,增强了用户对复杂模型的信任,并可以高效集成到高风险安全应用的在线部署中。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
