现代的安全大数据系统(SIEM)有太多的技术挑战,要满足安全的分析需求,就要采集海量且多样的数据,这增加了数据管理的复杂度,在复杂度下要保证数据质量和高效存储更是难上加难。
下面是笔者在假想下一代SIEM时,记录的部分技术灵感,简单介绍几个思路:
分段压缩编码设计
安全数据需要的高效的编码机制来实现最小化存储需求,同时更要保持数据分析的唯一性和可查询性,而JA4指纹的分段压缩编码设计值得学习。

设计思路一是针对某种维度的元数据集合进行哈希,这既减少了存储空间的消耗,又保持了数据的唯一性和完整性,当然只有安全人员知道需要对哪些元数据集合进行哈希才能真正有价值。二是使用传统的标志位结构体设计压缩保存元数据,当然JA4只是设计简单的位字段,每一位都有特定的含义,这样一个或多个位的组合则可以表示复杂的状态(标准协议数据的状态)。
这个设计思路分开来看都是常用的安全数据设计思路,没有什么惊奇,但结合起来的话确实起了化学作用,既保证了数据的唯一性和完整性,也可以将复杂的状态映射到整数二进制形式表示,扩展一下可以设计出更多的专用安全数据形态。
准实时计算
这里的准实时计算是指在一个时间窗口内对数据进行全量计算,对一个时间窗口内安全数据进行元素聚合会发现压缩奇效。比如JA4作者给出了一个聚合netflow数据的例子:
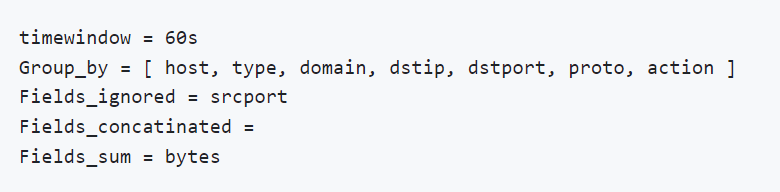
假设一个源地址在60秒的窗口内有黑白两种行为,通过TLS协议和443端口连接到Gmail有8次,总字节数为3365kb,并且还尝试连接到恶意网站1次,用JA4作者的方法聚合可以把这8次白连接日志数据压缩掉,但不影响安全日志的质量。
在常规的安全遥测中,安全数据除了命中的恶意数据,我们还需要恶意数据的上下文,但这些上下文是大量的高频白数据,对它们进行压缩和聚合还不影响安全数据价值是这个计算的核心。继续扩展一下,我们可以对一个时间窗口内安全关注的其他实体元素进行聚合,它并不局限于终端还是流量的安全数据。
布隆过滤器碰撞
布隆过滤器是一种概率数据结构,它可以以极小的存储和性能开销为各种元素建立亿级的哈希碰撞库,但它也有极小的误差。
Humio曾展示过如何在1 PB数据里一秒内获得搜索结果,首先它的底层数据库是时序数据库,很容易按时序(冷热)和标签(聚合)对数据进行分类,其最核心的数据压缩后还能快速搜索命中的黑科技就是布隆过滤器。
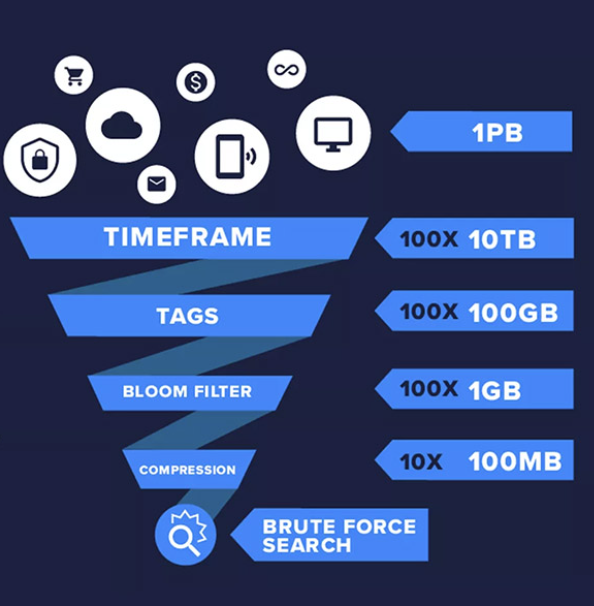
举一个布隆过滤器的开销例子,有技术人员将613,584,246个密码的社工库做成了布隆库,开销大概如下:
m = 数组的大小
n = 将要放置在数组中的项数
k = 使用的哈希函数数量
p = 假阳性的概率
m = 23,627,429,658(约2.75GiB),n = 613,584,246,k = 30,p = 0.00000001
m = 24,172,283,057(约2.81GiB),n = 613,584,246,k = 20,p = 0.00000001
m = 23,524,963,270(约2.74GiB),n = 613,584,246,k = 27,p = 0.00000001
对于超大数据集来说,概率数据结构的这个P(命中真假误差)是可以容忍的,实在为了提高精准度,我们还可以在布隆库后加入白名单逻辑。
Data Sketches(概率数据计算)
概率数据结构不止布隆过滤器这一种,除了超大数据集的碰撞,还有高频基数统计,它可以针对不同维度海量数据的元素进行计数。各种开源大数据项目利用概率数据结构优化复杂的大数据计算方法,创造了存储和性能开销的极限优势。当然,这也是SIEM这类安全大数据项目的核心需求。
简单的例子,互联网业务常使用RedisBloom进行海量用户的UV和PV的统计...
复杂的例子,Apache也整合了一整套DataSketches算法库,被广泛使用于大数据实时计算框架中,一些企业应用后存储和性能开销得到了极致优化。

小结
在网络安全领域,数据量庞大而且不断增长,在设计系统和算法时,合理选择和使用正确的方法和数据结构,才能消化掉真正的安全大数据。
声明:本文来自赛博攻防悟道,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
