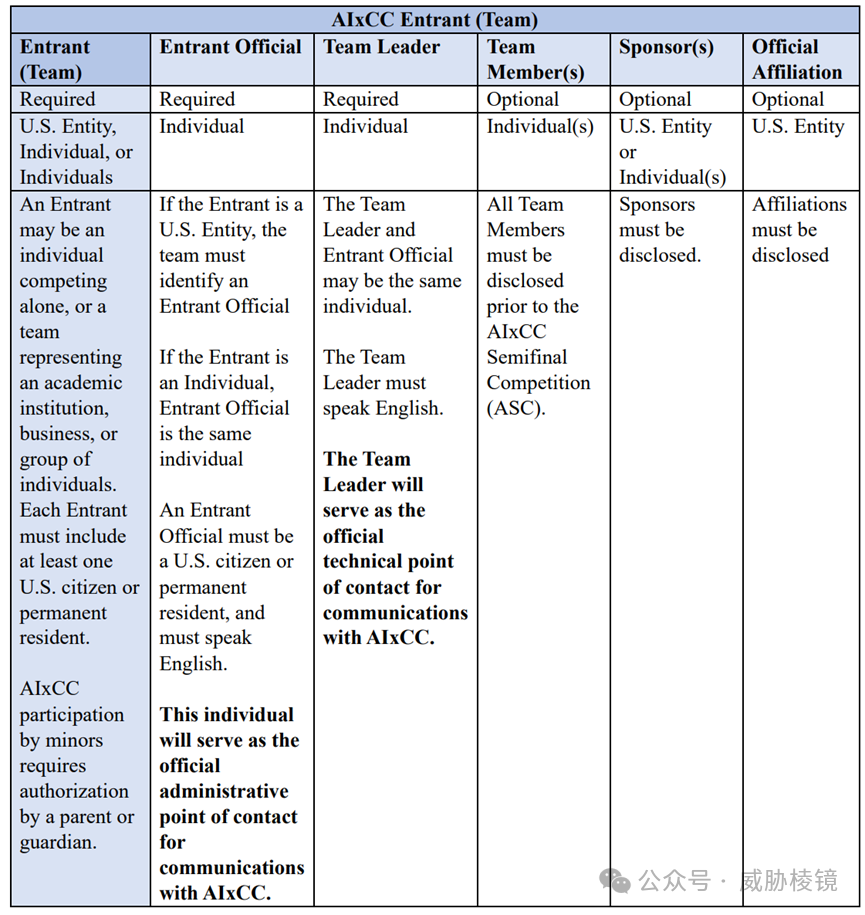
在互联互通日益增强的当今世界,软件在背后支撑着关键基础设施的运行,不断扩大的攻击面也为攻击者带来了可乘之机。过往的十年,人工智能技术的飞速发展为人类带来了更多可能性,在网络安全领域的应用也有着巨大潜力。
人工智能网络挑战赛(AIxCC)应运而生,旨在凝聚人工智能和网络安全领域最优秀、最聪明的人来保卫全体美国公民所依赖的软件。主办方DARPA 为挑战赛准备了高达 2950 万美元(约合 2.1 亿人民币)的奖金,并且与Anthropic、谷歌、微软和 OpenAI 进行合作举办这场挑战赛,力求推进网络安全与人工智能的产业融合和技术创新。

半决赛将在 2024 年 8 月举办的 DEFCON 32 拉开序幕,总决赛将在 2025 年举办的 DEFCON 33 上打响。按照现行的规则,在决赛后两周内获奖的队伍要按照开源促进协会(OSI)的许可将网络推理系统(CRS)作为开源软件发布。
挑战赛分为两条赛道,一条是小微企业赛道,另一条是开放赛道。小微企业赛道的前身是小微企业创新研究(SBIR)资助项目。前者的截止日期是 2024 年 1 月 15 日,后者的截止日期是 2024 年 4 月 30 日。

成功进入半决赛的七支队伍,每队将会获得 200 万美元的奖金。总决赛的前三名,将会分别得到 400 万美元、300 万美元和 150 万美元的奖金。合计2250 万的奖金加上前期资助入围的七个小微企业共计 700 万美元,DARPA 一口气拿出了 2950 万美元(约合 2.1 亿人民币)。
主要目标
美国国防部高级研究计划局(Defense Advanced Research Projects Agency,DARPA)是美国国防领域科技创新的重要部门,被认为是美国军方技术研究的重要风向标。该机构旨在进行前瞻性高新技术研发,为美国军方未来的需求培育创新型技术。从这里走出了互联网的雏形,也包括各式各样的武器装备。

AIxCC 的前身是Cyber Grand Challenge(CGC),当年的盛况掀起了学术圈里漏洞挖掘各类技术(模糊测试、符号执行、污点分析等)的研究浪潮。无论是 CGC 还是 AIxCC,目的都是要开发网络推理系统(CRS),在没有人为干预的情况下发现漏洞、修复漏洞。

DARPA 想要推动网络推理系统(CRS)在以下六大维度上的研究,目前还没有在各个方面都表现非常出色的系统。
软件规模:系统能够在大型软件代码库中发现漏洞并生成补丁。
多语言适用性:系统能够发现并修复多种编程语言中的漏洞。
漏洞类别:系统能够发现多种类型的漏洞。
漏洞发现准确性:系统能够以高准确度发现漏洞。
补丁有效性:系统能够在不修改程序功能的前提下生成补丁修复漏洞。
补丁可接受性:系统能够生成会被人类程序员接受的补丁。
评分规则
大赛规则对挑战赛的方方面面都作出了规定,例如不允许 DARPA 的员工及亲属参赛、不允许对其他参赛者进行DoS 攻击、不允许入侵或篡改挑战赛基础设施等等。
官方要求系统必须是自动化的;必须是技术进步,而不是钻评分算法的空子;不能偏向任何特定的方法;必须能够在实际的软件上运行,而不只是为了比赛而比赛。

总得分由四部分组成:

漏洞发现分数(VDS):提交的每个正确的漏洞 PoV 都能得分。
程序修复分数(PRS):提交的补丁可以通过检查即可得分。
准确度因子(AM):总分倍乘因子,以奖励准确度高的系统。
多样性因子(DM):总分倍乘因子,以奖励多样性强(漏洞种类与编程语言种类)的系统。编程语言多样性会涵盖Java、Rust、Go、JavaScript、TypeScript、Python、Ruby 和 PHP,但至少一半都是 C/C++、Java 编写。漏洞类型将会从 MITRE TOP 25 中抽取,尽可能多的覆盖更多类型的漏洞。
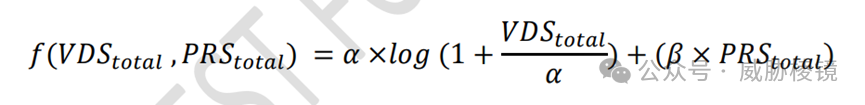
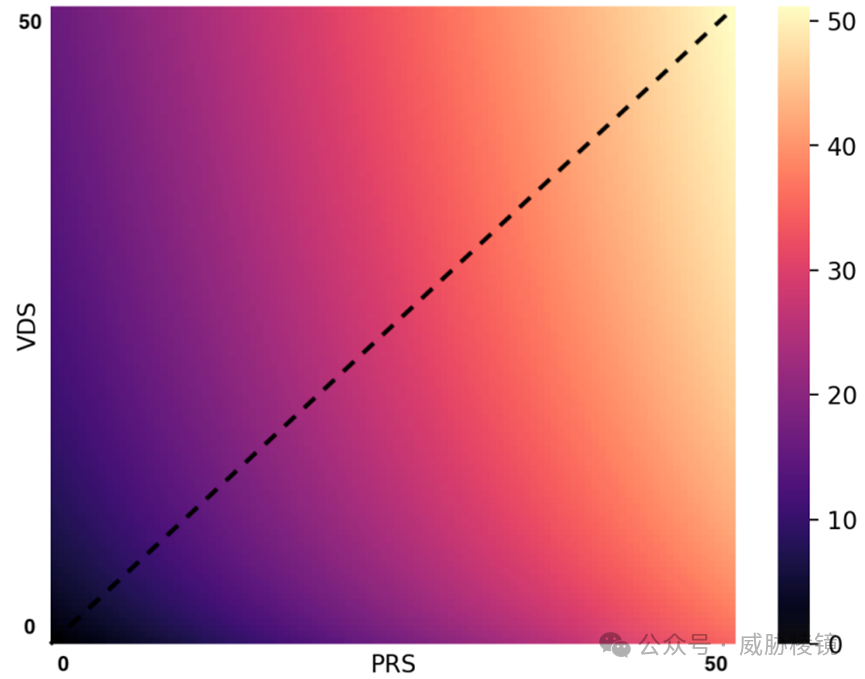
漏洞发现与程序修复的分数并不是线性累加的,集中在漏洞发现而非程序修复得分较低。单纯漏洞发现对得分的回报存在边际递减,能够将漏洞发现与程序修复结合起来的系统可以得到更高的分数。
另外,多样性因子的评分公式为:
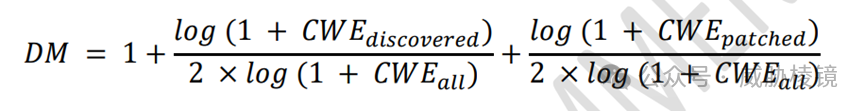
准确度因子的评分公式为:
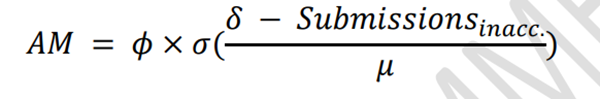
当然,目前规则并不一定十分完善,DARPA 欢迎各方提出意见并会及时修改规则。例如现行将先前披露的漏洞注入回到开源代码中,使用大模型(LLM)很可能已经包含了此类数据。这样测试比较得出的结果可能并不是测试的初衷,可能 LLM 在已知漏洞的表现上极好,但脱离了这个环境难以应对实际情况。而且,目前只比较了最终结果,但并没有对性能差异有任何评分细则。

英国前沿人工智能工作组在评估人工智能模型风险时,针对 LLM 评估进攻性网络能力发现:“对于可简化为自然语言处理的任务,例如编写网络钓鱼邮件和开展虚假信息宣传。LLM 不但可以达到专家的水平,也可以显著提高新手的水平”,“对于创建恶意软件、查找源代码中的漏洞以及创建漏洞利用程序,LLM 仅仅表现出了类似于新手的水平”。这可能表示,LLM 在应对这些场景时还缺乏推理和规划的能力。LLM 在推理密集型任务上表现不佳,例如识别源码中的漏洞或者对漏洞进行分类。有横扫千军之势的 LLM 也许并不能在比赛中大放异彩,许多研究人员还是认为人工智能类的技术还是要和传统的程序分析技术相结合使用。
小微企业赛道参赛团队
DARPA 举办的人工智能网络挑战赛(AIxCC)在小微企业赛道一共七个团队,DARPA 为每个团队提供一百万美元的资金,支持其开发人工智能的网络推理系统(CRS),自动化、大规模地进行漏洞查找与修复。
每个团队都要提交详尽的说明书,对概念可行性、技术方案健全性、开源策略等方面进行介绍。再由美国空军研究实验室、国防部副部长办公室、研究与工程和卫生高级研究计划局等机构的专家组进行审议,最终角逐出七支团队。
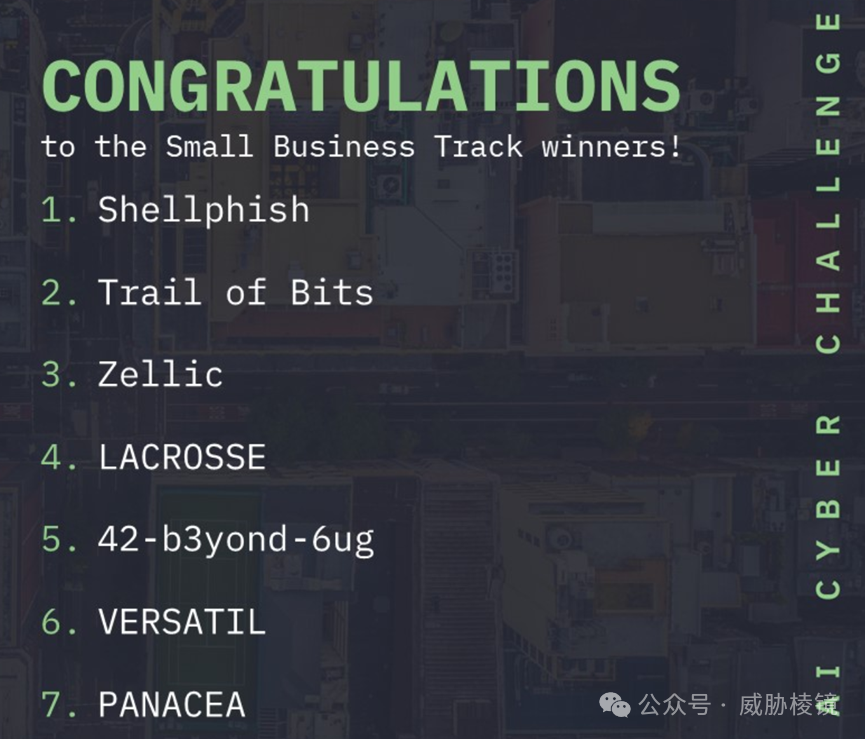
最终入围的是以下七支队伍:
Shellphish, Shellphish Support Syndicate
Shellphish最早在 2005 年由加州大学圣巴巴拉分校的 Giovanni Vigna 教授创立,后来在各 CTF 大赛上都展现了不凡实力。Shellphish 在 2016 年的 CGC 比赛中凭借 Mechanical Phish 拿到了第三名的好成绩,这次又毫不犹豫地参加了 AIxCC。
Trail of Bits, Trail of Bits, Inc.
Trail of Bits 是一家网络安全研究与咨询公司,为国防、科技、金融等行业的客户提供服务。该公司不仅是一个出色的咨询公司,还对外开源了大量自研的工具,感兴趣的可以去其官网查看。另外,这也是上届 CGC 比赛的第二名。

Zellic
Zellic由多名 Perfect Blue 成员创办,Perfect Blue 曾是世界上排名第一的 CTF 战队。该公司专注于漏洞发现,帮助各类客户发现了许多重要漏洞。
LACROSSE, Smart Information Flow Technologies (SIFT)
Smart Information Flow Technologies (SIFT) 是一个在 1999 年成立的咨询公司,年复合增长率(CAGR)超过 30%。该公司旨在推动技术发展并解决前沿问题,在人工智能、软件工程、控制理论、网络安全等领域都颇有建树。
42-b3yond-6ug, Net Shield LLC
Net Shield LLC 没能查到具体信息,官网似乎无法打开。而根据公开信息,42-b3yond-6ug 应该有多个美国高校的研究人员参与。
VERSATIL, GrammaTech, Inc.
GrammaTech 是康奈尔大学孵化的公司,为包括美国国土安全部、NASA、NIST、NSF 在内的诸多重量级机构提供安全服务。其当家产品 Proteus 声称能够自动发现并修复漏洞,该公司在该领域深耕三十余年。
PANACEA
PANACEA的资料也甚少,可能是欧盟的研究机构成立的团队。
声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
