当前,以法律问答、判决预测、要素抽取等为代表的法律人工智能(Legal AI)系统正在快速发展。2024年1月,《AI and Law》刊发了来自苏黎世大学、博洛尼亚大学学者合作的一篇文章《DiscoLQA: zero-shot discourse-based legal question answering on European Legislation》,该研究提出了一种基于话语理论的零样本欧洲法律问答系统——DiscoLQA,能够通过自动提取特定的知识图谱来解决法律问答问题(Legal QA),而不需要在法律文本上特别训练的深度语言模型。该系统还扩展了现有的基线工具,通过新组件增加了对特殊信息单元的提取,增强了法律问答系统的可行性,本文将对该系统的功能、特点、相较于现有系统的优势与不足进行解读。
1
法律问答系统的挑战与创新
随着社会对数字化的需求日益增长,法律、信息技术和计算机科学间的跨学科协作变得日益重要,这种需求促成了如希腊数字治理部、澳大利亚数字转型机构等政府机构的建立,以及欧洲数字转型行动计划等一系列长期规划的推行。
在人工智能领域,利用涵盖多个主题的训练集来回答问题的技术被称为开放领域问答(open-domain Question Answering ),当前的开放领域问答系统一般融合了传统的信息检索技术和基于神经网络的阅读理解模型。但此类系统在针对法律文本的神经网络阅读理解时存在困难,主要是因为法律领域专业术语数据集数量较少、法律文本与日常使用的自然语言存在显著差异,从而导致在应用通用语言模型进行法律问题的开放领域问答时会产生一系列的技术难题。在立法文本中,更倾向于采用较长的句式或更加正式的写作风格,从而减少可能存在的歧义并提升文本的可理解性,这也体现了法律文本具有非重复性、规范性,以及倾向于在特定情境中为避免多义性而用词精准的语义特征。然而,过长的句子或不常见的结构可能会引入噪声,从而分散训练于常规文本训练集上的语言模型的注意力,进而增加模型犯错的可能性。因此,仅当标准的神经阅读理解模型在法律领域进行专门训练后,才能准确捕捉法律文本的语义。正如Sovrano所提出的,构成法律文本的句子通常已经受到了正式规则的约束,这些正式规则的应用对话语结构产生了影响。[1]
在本文中,研究人员延续了先前的研究,探讨了如何实现“零样本”法律开放领域问答的机制。“零样本”指的是通过预训练的语言模型(训练于非法律文档)进行问答,而无需专门针对法律问答任务进行微调,这种方法能够更有效地将未针对特定法律任务进行优化或未在法律文档上训练的通用语言模型应用于法律领域。这些问答系统利用通用神经模型对所有潜在答案(如法律条款、序言)进行编码,随后通过编码实现基于相似度的检索,但检索得到的答案仅为句子或段落中的一小部分(即一个语法子树)。因此如果神经模型未专门针对法律术语进行优化,它可能难以识别在日常语言中不常见的语法子树的重要性,因此通过选择最重要的语法子树,研究旨在协助信息检索和问答系统通过部分隐藏答案中的噪声来提高性能。为识别这些关键的语法子树,研究中采用了基本篇章单元理论(elementary units of discourse,EDUs)[2]和抽象语义表示理论(abstract representations of meaning,AMRs)[3],通过捕捉话语结构,借助现有针对普通自然语言的问答工具,开发出更有效的答案检索工具。为评估研究中的系统,文中还创建了Q4EU这一全新的法律领域数据集,该数据集在Q4PIL数据集基础上进行了扩展,涵盖了从国际私法、人权法、电子签名条例和欧洲逮捕令等6项不同的欧洲法规。最终的实验结果表明,采用EDUs的版本整体上表现最佳,取得了最高的top-k精度和F1分数。此外,即便所涉及的深度语言模型未在法律语料库上预训练,DiscoLQA仍然能够在不同的法律子领域中应用。但同时研究的测试和评估仅限于特定的欧洲法规和相对较小的数据集,并未使用在更大规模的法律语料库上预训练的深度语言模型。
2
相关研究综述
法律问答技术作为人工智能与法律领域交叉的新兴方向,已经取得了较多的研究进展。现有的研究成果中,一部分采用了端到端的方法,基于现有的语言模型进行开发,另一部分则是将问答系统视作信息检索任务,利用本体论(ontologies)和知识图谱来实现问答。从现有研究来看,专门针对法律问答的端到端解决方案相对较少,这类方案往往仅针对具有大量数据集的特定而狭窄的应用场景。与此同时,当缺乏大规模数据集进行训练时,使用预训练的通用语言模型往往难以达到预期效果,同时先前的研究也表明,当法律推理任务的复杂度越高,模型微调的效果便越是不尽人意。[4]
另一方面,以国际私法为例的答案检索系统,结合了TF-IDF和多个深度语言模型,能够从自动生成的的语法子树知识图谱中检索相关答案。[5]该系统的知识图谱依据法律本体(涵盖代理人、角色、事件、时间参数和行动等方面)进行设计,以揭示法规内外的法律含义,这项研究也有效推动了先前的工作,旨在解决使用非法律专业语言训练的语言模型所遇到的问题。与此同时通过比较基于深度学习的解决方案与传统SVM的效果,研究人员发现在隐私政策问题数据集上微调的深度语言模型(RoBERTa)优于SVM,但隐私政策问题的语言使用更倾向于日常英语而非法律专业术语[6],因此也难以将其直接用于法律领域。
通过对不同研究的对比分析,本文试图探索法律问答领域不同方法和技术路径的实现可能性与存在的困难,进一步推动法律人工智能技术的发展与应用。
3
相关技术简介
3.1自然语言处理在法律领域的应用
在人工智能与法律的交叉领域,自然语言处理(NLP)技术的应用尤为关键。众多研究致力于利用最新的通用语言模型生成词汇和句子嵌入,以提高法律文本处理的效率。Bommarito等人开发了一个针对法律和监管文本的NLP和信息提取框架;[7]Chalkidis和Kampas则提出了首个专门针对法律文本的词嵌入模型。[8]近年来,法律文本的自然语言处理引起了广泛关注,这更凸显了在理论层面(如法律解释的角色)与实践层面(如处理大量法律数据和规范的复杂性)之间搭建桥梁的重要性与紧迫性。但自动化的法律推理是一个复杂的任务,它不仅要求深入理解语言、非单调逻辑和解释理论,还需要足够的灵活性来应对法律及其解释学随时间的变化。目前,人工智能推理技术可分为符号化和子符号化两种主要方法,符号化方法依赖于形式语言和逻辑的严格规则;而子符号化方法则基于深度学习的最新进展,能够以高效和可扩展的方式处理自然语言和视觉输入,但因为这种方法基于的是不易解释的非符号化表示(如数值向量),导致其的结果往往缺乏透明度。
3.2话语理论与法律术语的关联
话语理论作为语言学的一个分支,探索如何通过文本之间的连贯性和凝聚力关系构建完整的话语。连贯性是指话语之间各部分形成一个统一整体,凝聚力则是指文本元素之间存在共同的联系。尽管近年来提出了多种话语理论,每种理论都试图从不同角度解释文本如何构成有意义的话语,但它们普遍认同EDU这一概念,EDU代表文本中的一个单独事件,作为一个完整且独立的信息单元,可以与周围话语产生联系。
宾州篇章树库(PDTB)模型提出的EDU理论,是一种基于数据驱动、对语言底层结构假设最小的通用话语理论。PDTB模型基于话语的意义和连贯性部分源自于其内部构成之间的关系,通过显式或隐式的关系定义了话语中抽象对象间的语义联系。尽管已有研究人员将PDTB模型应用于法律语言的研究,但相关的后续研究尚不多见。现有的话语理论更适用于裁决、议会记录、证词和辩论报告等文本,而对于立法文本和合同这类使用特定词汇或具有特定文本结构的法律文档则显得不够适用。立法文本通常比常规句子具有更复杂的结构,并且法律文本中的连词(如xor、or、and)与日常语言中的使用方式也有所不同,它们在法律文本中承担着复杂的角色。有些话语结构在法律起草中甚至会被避免使用,因为它们并不符合常规的法律文本起草习惯。这些特点表明,法律语言的特殊性和复杂性要求为其开发更为精细和专门化的自然语言处理工具和理论框架,以便更准确地解析和处理法律文本。
4
基于话语理论的法律问答系统
该研究提出了DiscoLQA这一创新的算法流程,这是一个基于话语理论的法律问答系统。DiscoLQA设计的核心在于利用特定知识图谱的自动化提取能力,通过未专门针对法律文件训练的通用深度语言模型来解决法律问答难题。该系统在Sovrano开发的基线工具基础上进行了扩展,该基线工具通过从一组特定的信息单元中提取知识图谱,实现了高效的问题回答检索。[9]DiscoLQA则在基线工具的基础上新增了一个关键组件,由其负责从法律文本中提取EDUs和AMRs的信息单元。
如图1所示,DiscoLQA与基线工具不同的地方在于它在知识图谱提取过程中考虑的信息单元类型更为丰富。与基线工具仅利用源文件中的所有条款作为信息单元不同,DiscoLQA不仅能够处理条款本身,还能够利用从条款中进一步提取的AMRs和EDUs作为信息单元。换言之,DiscoLQA支持更广泛的信息单元类型,并允许系统从条款、AMRs及EDUs的综合中检索答案。而这一点尤为重要,因为话语关系有助于揭示EDUs之间的连接方式,AMRs则捕捉EDUs内部的关键信息组成以支持对基本问题(如谁、对谁、做了什么、何时何地)的回答。例如“合同的成立和有效性以及合同的任何条款,应由合同有效时本法中可管辖该合同的内容来确定”,我们可以从中提取具有条件关系的话语关系,并形成问题—答案对,如“Q:在什么条件下,合同将会由本法所管辖?A:合同或条款有效时”,以及AMR形式的问题—答案对,如“Q:合同的成立和有效性由什么决定?A:由本法中可管辖该合同的内容决定”。如此,一个话语关系连接了两个EDUs:一个在问题中被编码,另一个在答案中被编码,从而增强了法律文本分析的深度和广度。
通过这种方式,DiscoLQA不仅提升了法律问答系统的准确性和适用范围,也为在没有大规模专业法律训练数据集可供学习时处理复杂法律文本提供了一种新的思路和方法,展现了如何有效地利用已有的通用语言模型来解决法律领域的问答问题。

图1 基线工具和DiscolLQA算法流程图
4.1信息单元抽取过程
DiscoLQA利用基于T5的深度语言模型从文本中提取AMRs和EDUs,该模型已经在一系列无监督和有监督的多任务混合训练中得到了预训练。[10]鉴于T5模型原生并不直接支持AMRs或EDUs的识别,因此需要在QAMR和QADiscourse这两个公共数据集上进行微调。上述数据集通过将AMRs和EDUs转化为问答对的形式来简化处理流程,值得注意的是,这些数据集并不涉及法律领域的专业术语。微调T5模型的目的在于减小模型输出与预期输出之间的差异损失,尽管经过微调的T5模型在提取AMRs或EDUs时仍不完美,但之后的研究结果表明,即使使用的语言模型存在局限,该系统的表现仍能超越传统的信息检索系统。
QAMR数据集由107880个不同的问题(及答案)组成,这些问题(及答案)是AMRs到以下wh-短语的映射:

QADiscourse数据集由16613个不同的问题(及答案)组成,这些问题主要是将PDTB到以下wh-短语的映射:
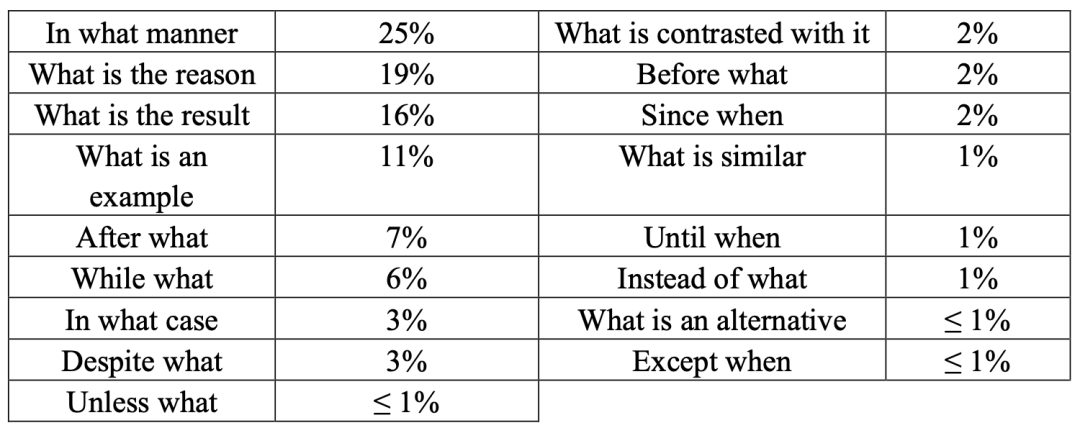
两个数据集是
通过微调,T5模型被训练以增强其在特定领域内处理复杂文本和理解深层次问答结构的能力,从而使模型能够更好地处理那些需要深度理解和抽象推理的场景(如法律文档分析、复杂的信息检索任务等)。
4.2 系统实现细节
DiscoLQA通过一套算法流程从信息单元集合中提取出专门的知识图谱,以便信息检索系统利用这些知识图谱回答具体问题。知识图谱的提取依赖于解析器,该解析器能够识别信息单元中的所有潜在短语和子短语,每个短语都代表知识图谱中的一条边。为了增强与外部资源的互操作性,系统还将模板三元组格式化为资源描述框架图,在最终的答案检索阶段,算法通过识别问题中的概念与知识图谱中最相似的概念及其相关的模板三元组,进而选择那些可能符合问题答案的自然语言表述,从提取的知识图谱中检索答案。
通过这种方法,DiscoLQA不仅优化了信息单元的提取和知识图谱的构建过程,还提升了法律问题回答系统的准确度和效率。这一系统实现的细节体现了AI技术在处理法律文本、提炼信息并支持法律推理过程中的潜力,尤其在面对没有大量专业法律训练数据支持的情况下,展现了通用深度语言模型在法律问答领域应用的可行性和有效性。DiscoLQA不仅显著提升了法律问答系统的性能,还增强了系统对复杂法律查询的处理能力,使其能够在众多可能的解答中快速准确地锁定最合适的答案。
5
实验
如前所述,法律术语虽然在许多方面与日常使用的自然语言相似,但在编码含义的方式上存在显著差异。法律语言具有高度的规范性,使用的语义术语旨在减少歧义,且通常在特定上下文中精确使用,其构成的句子遵循着严格的规则。因此研究中提出假设,即通过应用这些规则,将对句子内部的组合关系和话语结构产生影响。如果此假设成立,通过整合有关法律文本话语结构的外部信息,可以将通用自然语言模型专门化用于法律术语,而无需依赖于数据稀缺下的训练过程。因此,研究中设计了一项实验,研究利用EDU和AMR而非传统句子来执行文章和序言的问题—答案检索是否更为有效。总体目标是通过EDU和AMR作为信息单元,将法律文本的话语结构部分地映射到检索系统中,从而固化这些结构,避免答案检索器采用从通用语言学习到的话语模式。
DiscoLQA系统扩展了基线检索系统,支持包括EDU和AMR在内的多种信息单元,这一设计允许比较不同信息单元在相同检索算法框架下的性能表现。通过这种方法,DiscoLQA旨在揭示特定的EDU和AMR如何在处理那些未经特定法律训练数据优化的通用语言模型时为法律问答系统带来的优势。该实验不仅有助于提升法律问答系统的准确性和效率,还可能为法律文本的自动处理和理解开辟新的途径。实验中研究了以下DiscoLQA实例,以比较不同信息单元在相同答案检索算法上的性能:
研究选择先前的的法律问题—答案检索系统作为比较基线[11],主要基于两点理由:首先,该系统是目前已知的唯一一个能够在缺乏特定训练或微调程序的情况下进行法律问答的系统,这与本研究探索的零样本法律问答系统相契合。其次,它是唯一一个已经在欧洲立法领域进行测试的法律问题—答案检索系统,因此成为了最合适的比较基线。为确保实验结果的普遍性,并展示在不同深度语言模型上的效果,本研究计划在几种最先进的深度神经网络模型上运行答案检索实验,包括谷歌开发的通用句子编码器问答模型(USE),以及MiniLM和MPNet,后两者在125000000个问题—答案对上进行了SBERT微调。选择这些模型的原因是它们代表TensorFlow和SBERT这两个领先的深度神经网络库中的最佳通用模型,并且还提供API便于访问和使用。
6
Q4EU法律问答检索数据集
鉴于Q4PIL的数据集仅包含17个关于国际私法的问题,为了评估DiscoLQA性能,研究中构建了一个包含509个与欧洲立法相关的问题的数据集——Q4EU,这些问题都有与之对应的答案,纳入更多关于不同欧洲规范的问题,为深入分析和评估提供充分的数据支持。Q4EU包含72个独特的问题和225个预期答案,为了简化说明,Q4EU可以被划分为以下子集:
Q4PIL(表1):包含罗马一号条例EC 593/2008、罗马二号条例EC 864/2007、布鲁塞尔I bis条例EU 1215/2012。这些条例分别涉及合同义务适用法律、非合同义务适用法律、司法管辖权及民商事事项中判决的认可与执行。它们旨在识别适用法律和司法管辖权提供,用于当两个或更多法律主体之间产生复杂关系时(如一名意大利公民和一名德国公民之间关于位于西班牙的商品的销售合同)。

表1 Q4PIL
Q4EAW(表2):包含关于2002年6月13日欧洲逮捕令和成员国间引渡程序的理事会框架决定(CFD)的问题,这个框架决定提高了对犯罪嫌疑人的引渡程序的效率。此外,它还确定了对在最终被定罪后逃逸的人,在欧盟成员国之间取消正式的引渡程序。框架决定代表了在刑事事务中司法决策自由流动原则的第一次具体化实践,通过促进司法合作和在欧盟内发展一个单一的自由、安全和正义的区域。


表2 Q4EAW
Q4GDPR(表3):包含关于欧盟数据保护法律框架中最相关的法规——通用数据保护条例(GDPR)的问题。其目标是促进由欧盟基本权利宪章(第8条)确立的数据保护的基本权利,同时在数据处理、个人信息画像和风险管理方面统一规则。
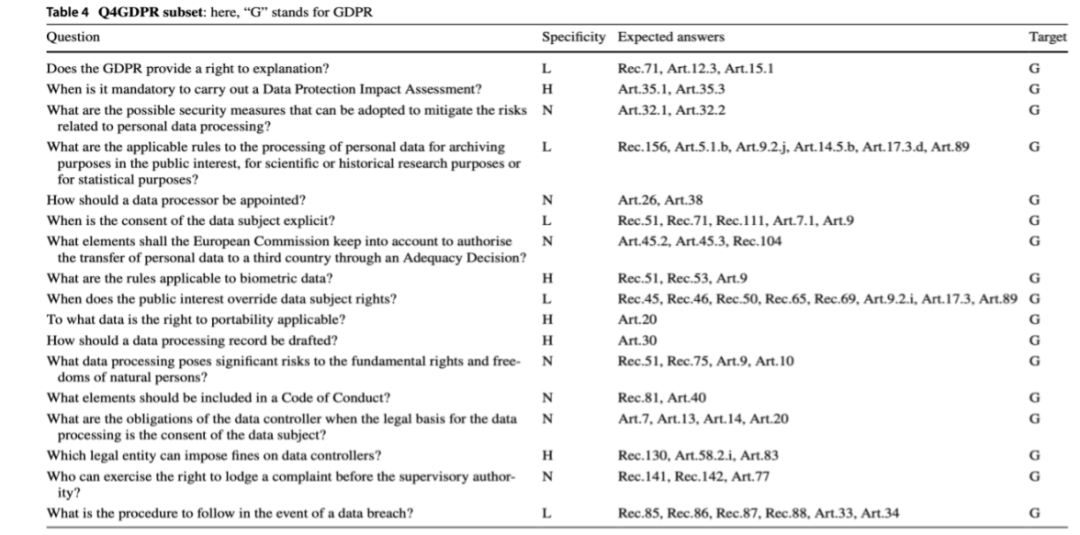
表3 Q4GDPR
Q4eIDAS(表4):包含关于2014年7月23日欧洲议会及理事会关于电子认证及内部市场电子交易信任服务的条例(EU)No 910/2014,并废除1999/93/EC指令的问题,也称为eIDAS条例。该法规处理电子认证、电子签名、电子印章和信任服务等多个问题,其目的是为欧盟单一市场跨境交易提供法律指引。

表4 Q4eIDAS
在构建Q4EU数据集的过程中,主要参考的是Q4PIL数据集,从而将涉及的立法视作独立的法律体系。尽管法律解释往往依赖于外部因素,如法学家观点或判例法,但本研究采取了一种专注于立法文本“字面”意义的法律解释方法。这意味着,研究人员在分析中主要从立法者的角度出发,以立法本身为解释和理解的基础。这种方法对问题和答案的构建产生了直接影响,一方面,设计的问题旨在仅通过检索的法律文本本身来找到答案,不涉及未在条例中直接明确的法律概念,如法律来源的层级结构或法律权力等。此外,问题的性质各不相同,一些问题的答案可以直接通过与问题严格匹配的法律条款找到,而其他问题则需要依赖于更为复杂的法律解释或法律推理。
因此,研究人员问题根据问题与法律文本的直接相关性进行分类,将其分为分为低、中、高三个等级。具体而言,当答案可以直接在相关法规内找到、并且答案在法律文本的“字面”意义上明确提供的问题,这一问题将被视为是高度具体的。例如“员工可以在哪个法院起诉其雇主?”这样的问题被认为是高度具体的,因为它直接关联到布鲁塞尔I-bis条例的应用范围和目标,并且可以在第21条和第23条的条款中找到确切的答案。通过这种方法,Q4EU数据集旨在提供一个全面的测试基础,以评估法律问答系统在处理各种类型法律问题时的效率和准确性,特别是那些对法律文本“字面”解读有依赖的问题。这样的数据集设计不仅有助于评估系统对具体法律问题的响应能力,还能够检验系统在解读和应用法律条文方面的深度和广度。
7
实验结果分析
在构建Q4EU数据集的过程中,研究人员认识仅依赖单一评价指标可能不足以全面评估DiscoLQA系统的性能。因此,研究中使用了top-k精度、F1分数、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)和平均排序倒数(Mean Reciprocal Rank,MRR)作为评价指标,从多个角度对系统的性能进行全面评估。[12]上述指标的主要区别在于,MRR和NDCG用于评估一个答案检索系统排列正确答案的能力,而其他指标衡量系统的精确度和准确性。因此,所有选定的指标被认为是互补的,可以从不同的角度理解答案检索系统的问题。在实验中,通过比较不同信息单元(EDUs、AMRs与普通子句)和不同深度语言模型(如MPNet、MiniLM)的组合对性能的影响,研究人员发现将EDUs作为信息单元与普通子句和AMRs结合使用时,能够实现最佳的精度。
在表5、6和7中,展示了对于k = {5, 10}的top-k评估分数,由此研究不同类型的信息单元和深度语言模型如何影响答案检索。在实验中展示了两种不同的评估类型,第一种是在Q4EU的所有6个规范上运行答案检索算法(称为“所有规范搜索”),即使Q4EU中的问题通常只针对个别规范。第二种只考虑每个问题针对的法律规范(称为“目标规范搜索”),过滤掉所有来自无关规范的答案。最终“目标规范搜索”所有评估指标得分都高于“所有规范搜索”,这一结果表明,无论k的选择如何,使用EDUs作为信息单元可以提供最好的精确度,尤其是当它与条款和AMRs结合使用时。

表5 每种信息单元组合的top-k精确度 (P)、F1、NDCG和MRR的宏观平均值
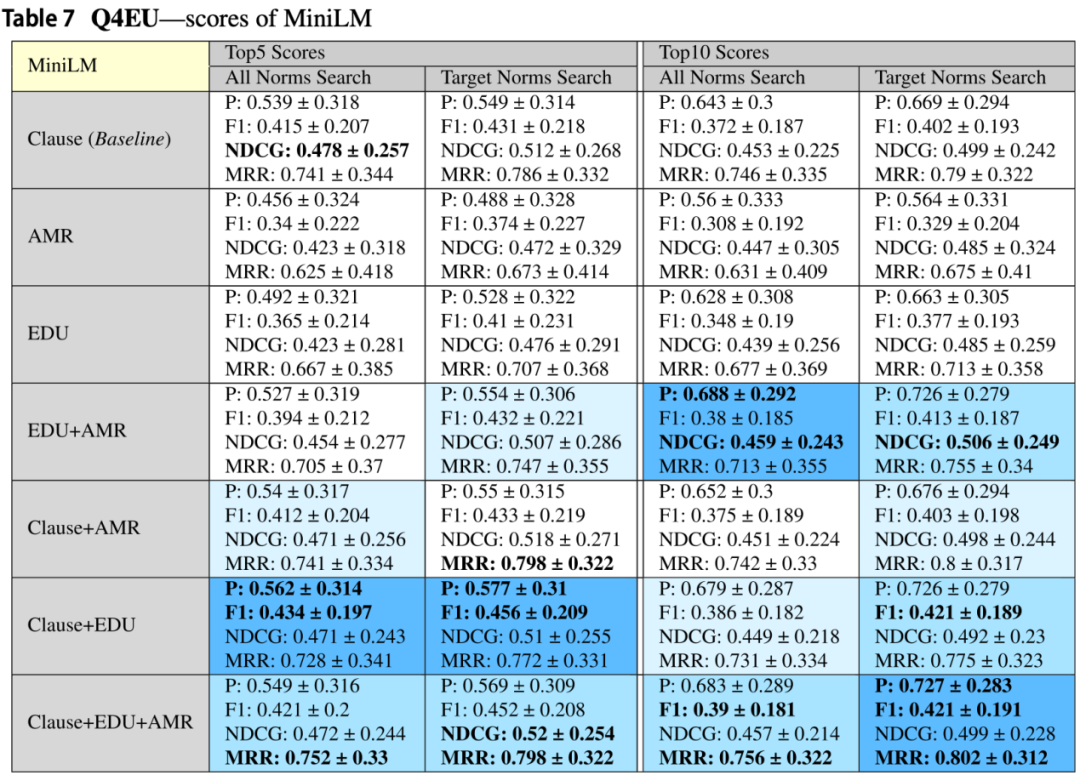
表6 MiniLM评估结果

表7 MPNet评估结果
MPNet、MiniLM(表现最佳)和USE的结果非常相似,这一结果表明信息单元可能独立于用于检索的底层语言模型。DiscoLQA仅使用EDUs和AMRs作为信息单元时在精度方面超越了基线,这在除了MPNet之外所有的深度语言模型中都是如此,表明EDUs和AMRs可以保留技术文档语料库中的大部分相关信息。此外,如表8所示,EDUs和AMRs的平均长度小于普通子句的长度,从而证明实验中使用的深度语言模型可能会被较长的子句分散注意力。
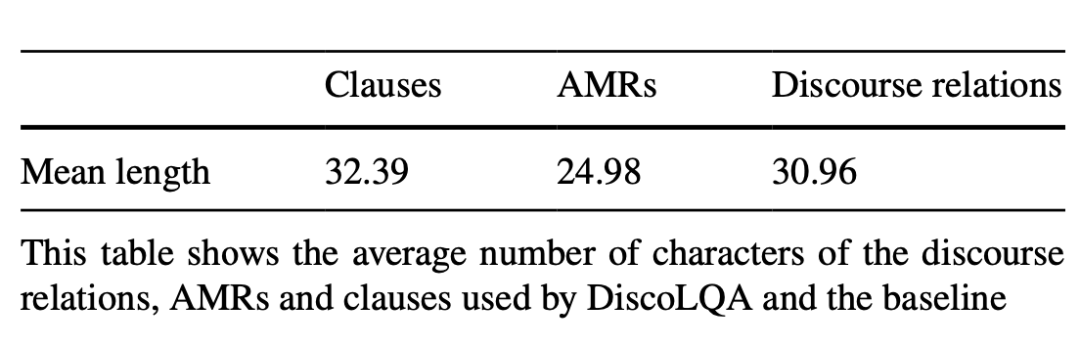
表8 不同种类信息单元的平均长度
鉴于在不同算法和信息单元之间观察到的差异,实验中进行了统计测试以确定这些发现的重要性,由于数据样本不是独立的,研究人员选择了Wilcoxon符号秩检验[13]。USE和MiniLM的“目标规范搜索”top-10分数的统计测试结果分别显示在表9和表10中。在使用EDUs、AMRs和子句的组合时,可以看到精确度和F1分数在统计学上显著改善。MiniLM主要在精确度上显示出显著增益,而USE在F1分数上表现出更明显的变化。
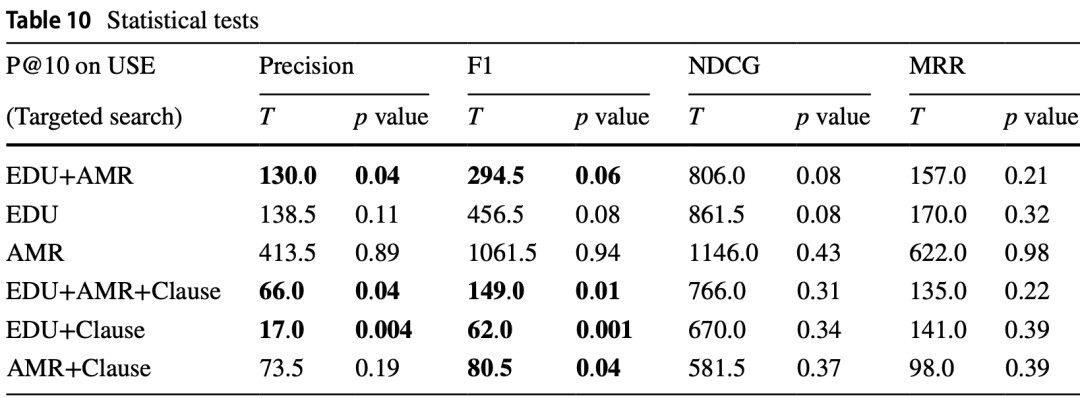
表9 USE top-10统计测试结果
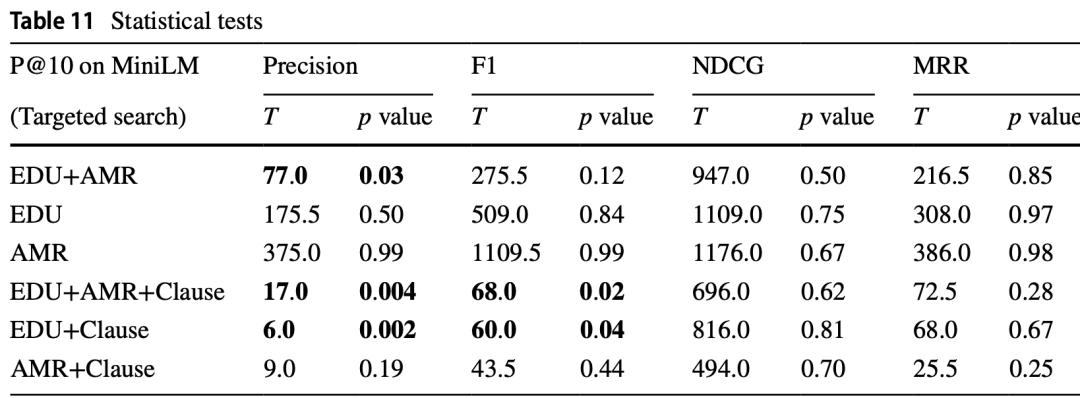
表10 MiniLM top-10统计测试结果
以上结果发现表明,通过捕获句法关系并使用无噪声信息单元,将通用从句分解为一个或多个EDUs或AMRs,可以改善通用语言模型,使其在法律文本上表现更佳。通过将句子分解为EDUs并明确保留它们的关系,可以将话语结构固定到知识图谱中。
表11举例说明了EDU和AMR对Q4EU数据集中某些问题的重要性,它可以识别有用的规范以确保答案的完整性并形成概览。例如,在对“在欧洲逮捕令与第三国引渡请求发生冲突时,谁决定优先权?”这一问题的回答中,算法确定了第16.3条(最相关的回答),并建议采用有助于解释第16.3条的第8条。此外,对于同一问题,算法还建议采用第10.6条,该条虽然不适合回答该问题,但可引导法学专业人员找到补充参考点,以进行更全面的推理和解释。
表11和表12也展示了答案检索器和信息单元提取器的错误。第一种类型的错误发生在提取的信息单元在语义或语法上不正确,如表11的第一行和第四行所示,这种类型的错误相对较小,因为在某些情况下,底层语言模型对不准确性有抵抗力,仍然允许检索到正确的答案。这种类型的错误通常是由神经网络自动提取AMRs和EDUs引起的,因此在表11和表12中可以看一些信息单元与响应文本不完全重叠的例子。第二种类型的错误是由于深度语言模型在答案检索中的错误,这种类型的错误可能相当严重,导致检索器选择错误的答案。
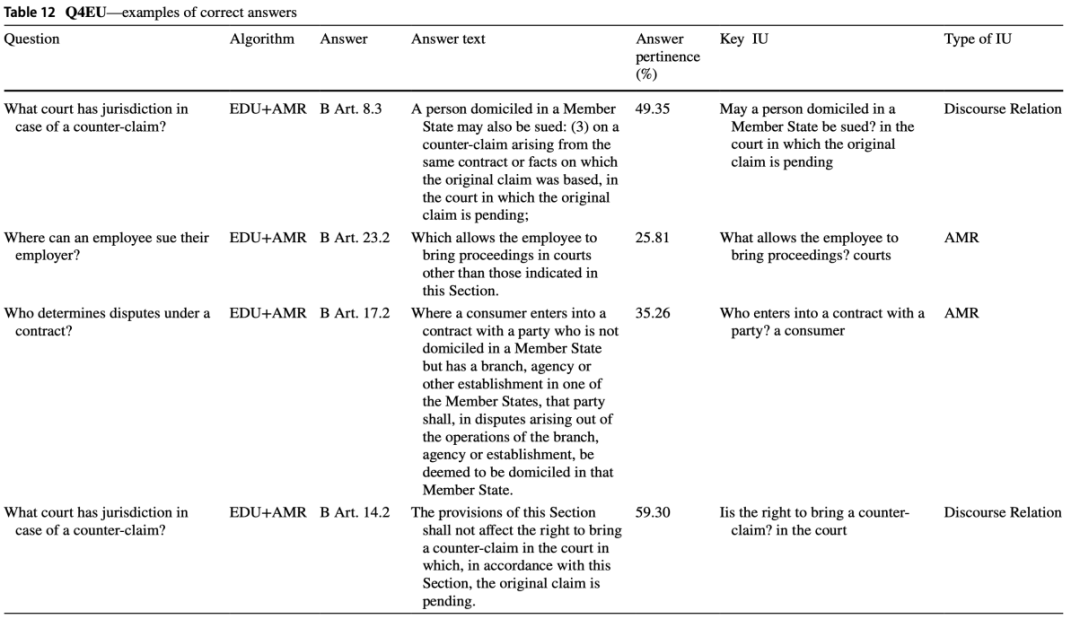
表11 基线和DiscoLQA(EDU+AMR)给出正确答案
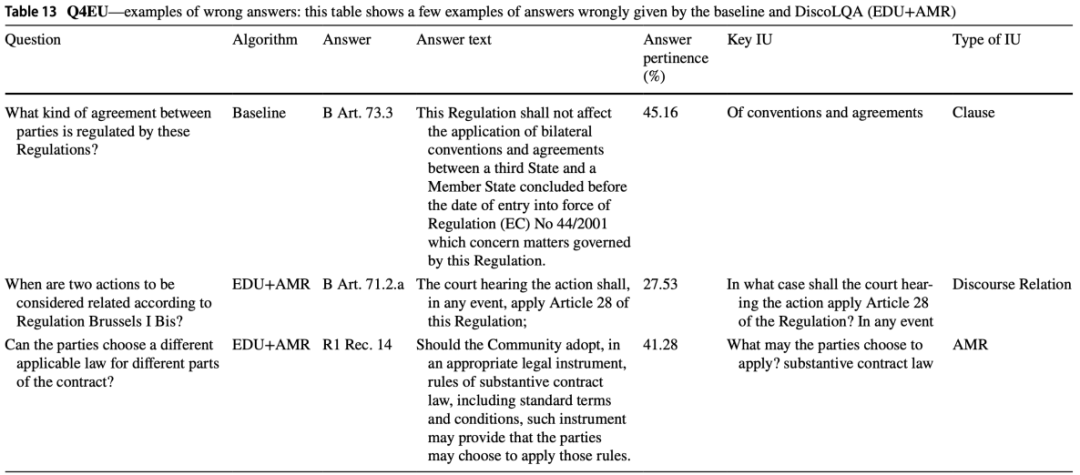
表12 基线和DiscoLQA(EDU+AMR)给出错误答案
研究中还对上下文直接相关性变化时的top-10精确度分数如何变化进行了研究,通过实验可以看到平均top-10精确度随上下文直接相关性成比例增加。这在除AMR之外的所有DiscoLQA实例中都很明显。如表13所示,AMRs只有在具有低和正常直接相关性的问题上才有助于更好地回答问题。此外,研究还在表14中展示了DiscoLQA与基线相比,在top-10精确度方面产生正/负差异的百分比,并按上下文的直接相关性分组。
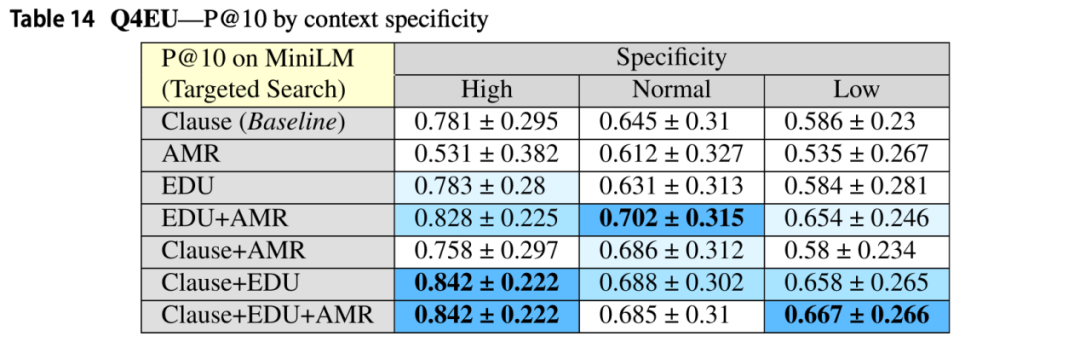
表13采用“目标规范搜索”的MiniLM按上下文直接相关性分组的top-10平均精确度得分
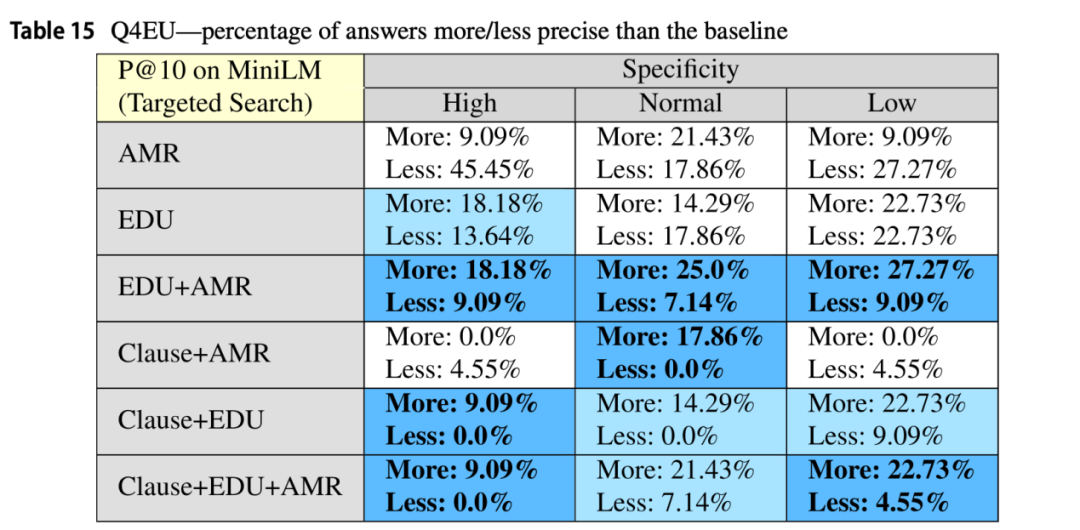
表14 DiscoLQA与基线相比top-10精确度的正/负差异百分比
8
结论
该研究通过实验证明了法律语言中话语结构的重要性,并尝试理解其在法律文档含义编码中的作用,这是首次尝试将PDTB等复杂语言理论应用于探索法律问题回答中的基本信息单元——EDUs和AMRs。实验结果揭示,EDUs和AMRs在捕捉信息单元之间的长距离关系方面极为有效,从而显著提升了DiscoLQA系统相比于基线模型在top-k精度、F1分数、NDCG和MRR等评价指标上的表现。尤其在使用MiniLM模型进行“目标规范搜索”时,采用EDUs和AMRs的DiscoLQA版本实现了比基线模型高出23.61%的top-10精确度回答,对于直接相关性中等和较低的问题,这一提升分别达到了25%和27.27%。
该研究结果不仅具有理论意义,也具有实际应用价值。通过深入了解法律语言与自然语言的区别,有助于解决法律语言处理中的数据稀缺问题,使研究人员能够直接使用未经特定法律文档训练的通用语言模型。研究中有许多针对法律领域的训练数据示例可以通过迁移学习范式加以利用,尽管在迁移学习时不同法律领域或文档可能需要不同的话语结构和语言模型。虽然DiscoLQA在特定的欧洲法律规范和较小的数据集上进行了测试和评估,但未与在法律语料库上预训练的深度语言模型进行比较。尽管如此,DiscoLQA在处理国际私法、欧洲逮捕令、数据保护和电子签名等不同法律子领域时展现出了良好的泛化能力,这表明DiscoLQA能够在数据稀缺的多个领域中发挥作用,而无需手动创建耗时的新数据集。
[1] Sovrano F, Palmirani M, Vitali F. Combining shallow and deep learning approaches against data scarcity in legal domains. Government Information Quarterly. 2022 Jul 1;39(3):101715.
[2] Prasad R, Bunt H (2015) Semantic relations in discourse: the current state of ISO 24617-8. In: Proceed- ings of the 11th joint ACL-ISO workshop on interoperable semantic annotation (ISA-11). Associa- tion for Computational Linguistics, London, UK.
[3] Banarescu L, Bonial C, Cai S, Georgescu M, Griffitt K, Hermjakob U, Schneider N (2013) Abstract meaning representation for sembanking. In: Dipper S, Liakata M, Pareja-Lora A (eds), Proceed- ings of the 7th linguistic annotation workshop and interoperability with discourse, law-id@acl 2013, August 8–9, 2013, Sofia, Bulgaria, pp 178–186. The Association for Computer Linguistics.
[4] Zheng L, Guha N, Anderson BR, Henderson P, Ho DE (2021) When does pretraining help?: assessing self-supervised learning for law and the casehold dataset of 53, 000+ legal holdings. In: Maranhão J, Wyner AZ (eds), ICAIL ’21: Eighteenth International Conference for Artificial Intelligence and Law, São Paulo Brazil, Jun 21–25, 2021. ACM, pp 159–168.
[5] Sovrano F, Palmirani M, Vitali F (2020) Legal knowledge extraction for knowledge graph based ques- tion-answering. In: Villata S, Harasta J, Kremen P (eds) Legal Knowledge and Information Sys- tems—JURIX 2020: The Thirty-Third Annual Conference, Brno, Czech Republic, Dec 9–11, 2020, vol 334. IOS Press, pp 143–153.
[6] Vold A, Conrad JG (2021) Using transformers to improve answer retrieval for legal questions. In: Mara- nhão J, Wyner AZ (eds) ICAIL ’21: Eighteenth International Conference for Artificial Intelligence and Law, São Paulo Brazil, Jun 21–25, 2021. ACM, pp 245–249.
[7] Bommarito II MJ, Katz DM, Detterman EM. LexNLP: Natural language processing and information extraction for legal and regulatory texts. InResearch handbook on big data law 2021 May 14 (pp.
216-227). Edward Elgar Publishing.
[8] Chalkidis I, Kampas D (2019) Deep learning in law: early adaptation and legal word embeddings trained on large corpora. Artif Intell Law 27(2):171–198
[9] Sovrano F, Palmirani M, Vitali F (2020) Legal knowledge extraction for knowledge graph based ques- tion-answering. In: Villata S, Harasta J, Kremen P (eds) Legal Knowledge and Information Sys- tems—JURIX 2020: The Thirty-Third Annual Conference, Brno, Czech Republic, Dec 9–11, 2020, vol 334. IOS Press, pp 143–153.
[10] Raffel C, Shazeer N, Roberts A, Lee K, Narang S, Matena M, Liu PJ (2020) Exploring the limits of trans- fer learning with a unified text-totext transformer. J Mach Learn Res 21:1401–14067
[11] Sovrano F, Palmirani M, Vitali F (2020) Legal knowledge extraction for knowledge graph based ques- tion-answering. In: Villata S, Harasta J, Kremen P (eds) Legal Knowledge and Information Sys- tems—JURIX 2020: The Thirty-Third Annual Conference, Brno, Czech Republic, Dec 9–11, 2020, vol 334. IOS Press, pp 143–153.
[12] Top-k精度(P@k),衡量预期答案在前k个检索结果中出现的比例,反映了系统在最前面的几个答案中准确性的高低;F1@k分数,结合了精确度(P@k)和召回率(R@k)的调和平均,其中R@k是指在前k个实例中检索到的正确答案的比例,F1分数平衡了精确度和召回率,为系统整体性能提供了评价;NDCG,一个归一化的排名质量度量,在[0, 1]范围内,根据答案在结果列表中的排名来衡量其相关性或增益,更高的NDCG值表明答案的排序更接近理想状态;MRR,关注于最高排名的相关项,衡量系统在将相关文档或段落排在最前的能力。
[13] Woolson RF (2007) Wilcoxon Signed-Rank Test. Wiley Encyclopedia of Clinical Trials, 1–3
撰稿 | 赵飞飞,清华大学智能法治研究院实习生
修改、指导 | 刘云
编辑 | 朱正熙
注:本公众号原创文章的著作权均归属于清华大学智能法治研究院,需转载者请在本公众号后台留言或者发送申请至computational_law@tsinghua.edu.cn,申请需注明拟转载公众号/网站名称、主理者基本信息、拟转载的文章标题等基本信息。
声明:本文来自清华大学智能法治研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
