软件漏洞对网络空间安全构成了巨大的威胁,因此对能够自动检测漏洞的系统的需求日益强烈。近年来,学者们提出了基于深度学习的漏洞检测系统,以实现从源代码中自动化提取漏洞特征,用于漏洞检测。尽管这些方法在人工合成的数据集上可以达到理想的检测表现,但对于真实生产环境中的漏洞数据集,其准确率仍然不甚理想。此外,这些方法将其范围限制在单个函数内,忽略了函数之间的联系。因此,我们提出一种新的方法,通过提取函数的抽象行为来弄清函数之间的关系,并利用这些全局信息来帮助基于深度学习的漏洞检测系统实现更好的检测效果。为此,我们设计了一个行为图模型,并基于其开发了一个可以增强其他漏洞检测系统的框架VulBG。为了检验VulBG的效果,我们选择了几个具有代表性的基于深度学习的漏洞检测模型(如TextCNN、ASTGRU、CodeBERT、Devign和VulCNN)作为基准模型,并在两个真实世界的数据集上进行评估:平衡的FFMpeg+Qemu数据集和不平衡的Chrome+Debian数据集。实验结果表明,VulBG使所有基准模型能够检测到更多的真实漏洞,从而提高了整体的检测性能。
该成果“Enhancing Deep Learning-based Vulnerability Detection by Building Behavior Graph Model”发表在国际会议ICSE"23上。ICSE是CCF A类会议,也是软件工程领域最重要的国际会议之一。ICSE 2023共收到投稿796篇,录用209篇,接收率为26%。会议于2023年5月14日-5月20日在澳大利亚墨尔本举办。

论文链接:https://ieeexplore.ieee.org/document/10172844
背景与动机
随着软件系统的快速发展,出现了越来越多的由软件漏洞导致的安全威胁,如黑客攻击、僵尸网络攻击以及用户信息泄露。因此,我们急需一种快速、精准的大规模漏洞检测系统以维持软件系统和软件供应链的安全。由于深度学习技术在提取自动化提取图像以及文本中的特征的优异表现,人们提出了很多基于深度学习的漏洞检测系统。最先出现的是基于文本分析的检测系统,这类系统往往将代码文件视作一段文本,之后使用循环神经网络(RNN)进行特征提取和漏洞检测。由于源代码相较于普通的文本而言,具有更强的结构性,存在语义和结构特征,人们提出了基于抽象语法树(AST)以及程序依赖图(PDG)的漏洞检测系统,以更好地提取语义和结构特征。这类系统通常将函数源代码转换成具有一定结构信息的AST和PDG,之后使用图神经网络(GNN)来实现特征提取和漏洞检测。相比较于第一类系统,第二类系统取得了更好的检测效果,但是由于需要提取AST和PDG,使得其兼容性不如第一类系统。
然而这两种系统都存在以下问题:首先,需要将整个函数源码作为模型的输入,以进行特征提取及最后的漏洞检测。但是,在现实情况中,一个函数中存在的漏洞逻辑往往只占函数的很小一部分,将整个函数逻辑作为模型的输入会让模型被其中大量无用信息所误导,进而导致漏报和误报。其次,现有的漏洞检测系统将漏洞检测局限于每一个函数中,忽视了存在漏洞函数中的内在联系。我们发现,一部分存在漏洞的函数之间是存在一定联系的,虽然其实现的功能和逻辑完全不同,但是其存在漏洞的片段却是高度一致的。为了解决上述问题,我们提出了“行为”的概念。“行为”指的是具有一定功能的程序片段,它可能是一种算法的实现、一段控制逻辑的实现或是一段实现某个子任务的几行代码。一个函数可以看作是一系列行为的组合,不同的函数之间可能共享相同的行为,而漏洞往往存在某个行为或者某几个行为的组合中。为了能够更好地描述和利用函数之间的联系,我们提出了“行为图”的概念。
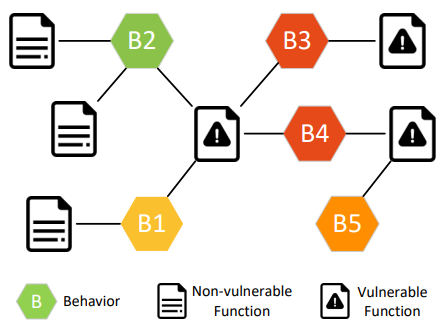
图1 利用行为图来判断漏洞
图1是一个行为图的实例,函数与函数之间通过它们的公共行为建立联系。与漏洞函数相连的行为,我们认为其更有可能存在漏洞逻辑,而与不存在漏洞的函数相连的行为,我们认为其更有可能是无害的;与越多有害行为相连的样本,我们认为其含有漏洞的概率越高。通过行为图,可以自动判断哪些行为可能是有害的;并通过行为图上的联系关系轻松检测出具有相似漏洞的函数样本。
设计与实现
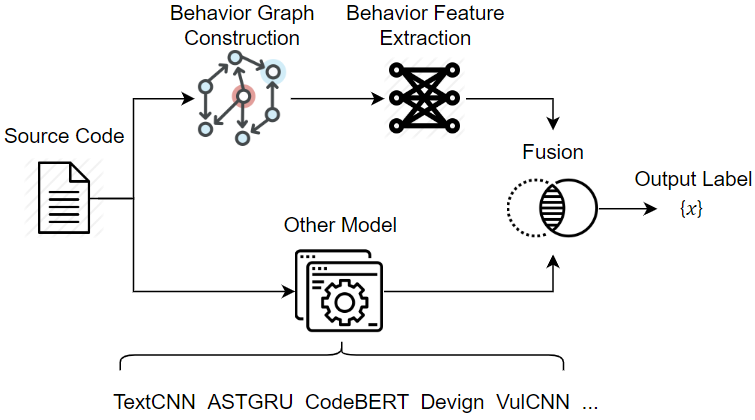
图2 VulBG示意图
基于行为图,我们开发了VulBG框架(如图2所示),利用从行为图中提取的函数与函数之间存在的联系来增强目前已有的基于深度学习的漏洞检测系统。VulBG由三部分组成:行为图构建、行为特征提取以及模型融合。
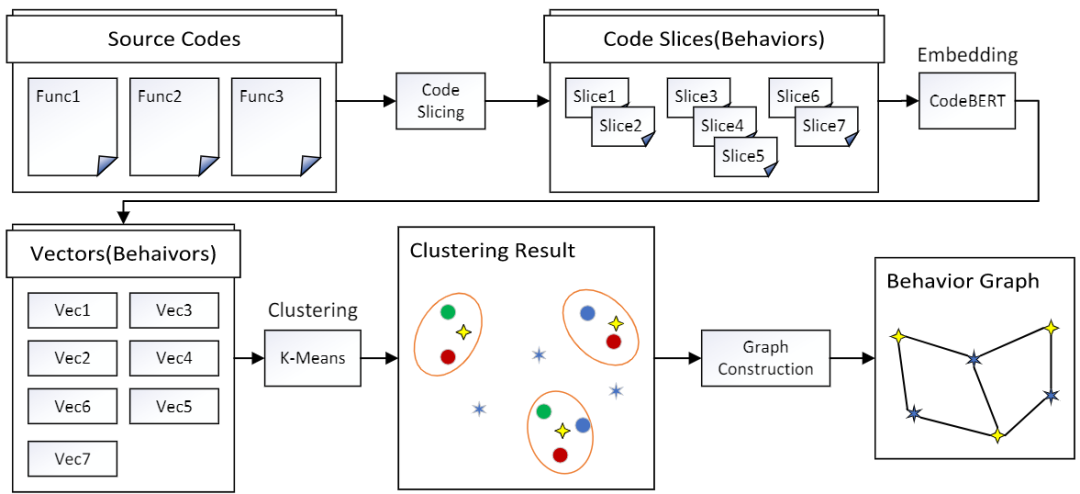
图3 行为图构建流程
如图3所示,行为图的构建由以下四个阶段构成:代码切片、切片嵌入、聚类以及构图。需要注意的是,VulBG中使用的行为图与上文中的行为图并不一致,使用类中心结点代替了具体的行为。这是由于当函数数量非常大时,其行为数目也会巨大,如果将所有函数以及行为都编入一张行为图中,该图会非常稠密,存储时会有巨大的内存开销,在对图进行操作时也会有巨大的时间开销。在实验中我们发现,其实很多行为(切片)都是非常类似的,实现的功能也非常相似,因此我们决定将行为进行聚类,用类的中心行为来代表这一类行为,从而大幅度减少行为图中的结点数目,进而减少内存和时间开销。
在VulBG中我们使用代码切片技术来提取切片并作为行为。与传统的将整个漏洞切入一个切片为目标的切片方式不同,我们使用了基于API调用和内存操作的切片技术。我们提取的切片代表着函数功能中的一个基础步骤的代码实现,因此我们的切片相较于传统的切片而言更小,且提取速度更快。
由于聚类算法是根据样本与样本之间的相似性,由上一小节中介绍的切片算法可知,行为本质上就是一段代码也就是一段文本。可以考虑使用模式匹配算法(例如K.M.P算法)来度量它们之间的相似性,但这种方法时间复杂度过高,在聚类算法中不具备可行性。而且,模式匹配算法将行为看作为一串字符片段,忽视了作为代码的行为中其实包含了一些语法和语义信息。为了让后续的处理过程更加高效和灵活,VulBG采用了文本嵌入算法将行为转换为向量形式,特别地我们选择了在代码嵌入中表现优异的预训练代码嵌入模型CodeBERT进行代码嵌入。在完成代码嵌入之后,我们使用了MiniBatchKMeans算法(一种内存友好的KMeans算法变种)进行了聚类,从而得到类中心行为。
在得到类中心行为之后,每个函数样本与其行为所属的类中心行为进行连接,从而构成行为图。与前文的行为图不同的是,在该行为图中是通过是否含有相同的类中心行为来确定函数之间的关系,而非具体的行为。由于行为之间存在差异,同一类的行为不可能与类中心行为完全一样,为了保留这一差异信息。VulBG将边的权重设置为行为的相似度。两个行为的相似度越高,它们的嵌入结果就越接近,因此,VulBG用一个行为和其对应的中心点行为之间的距离来表达它们的相似性。特别地,在VulBG中,使用欧氏距离(Euclidean Distance )来描述行为和类中心行为的相似性。在得到行为图之后,为了充分地利用函数的行为特征和行为图中函数之间的联系,我们选择使用图嵌入的方法将图中的节点转换为向量形式。在此我们采用了一个广泛使用的结点嵌入工具Node2Vec进行图嵌入,得到每一个函数样本所对应结点的图向量。
随后,如图4所示,我们使用了一个三层的全连接神经网络对图向量进行了行为特征提取;在得到行为特征之后,我们将其与其他模型的最后一层隐藏层的输出相融合,使用融合后的特征进行漏洞检测。这种融合方法非常简单,使得它对保持其他模型具有非常小的侵入性影响,因此VulBG具有很好的可扩展性和兼容性。
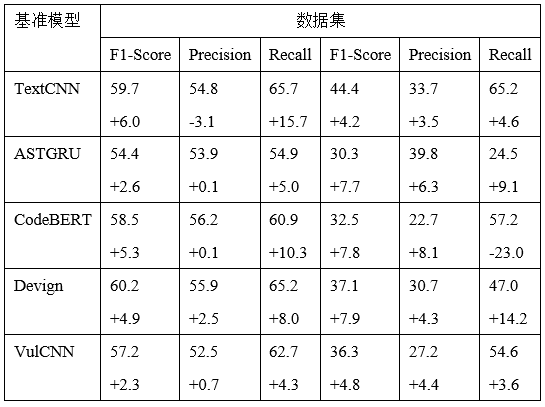
最后,我们在两种从真实生产环境中提取的平衡数据集FFMpeg+QEMU以及非平衡数据集Chrome+Debian中,选择了5种最具有代表性的基准模型(TextCNN、ASTGRU、CodeBERT、Devign以及VulCNN)进行了实验,结果如表1所示。实验结果表明,使用VulBG增强过后的基准模型,在检测准确度上有了明显的提升。
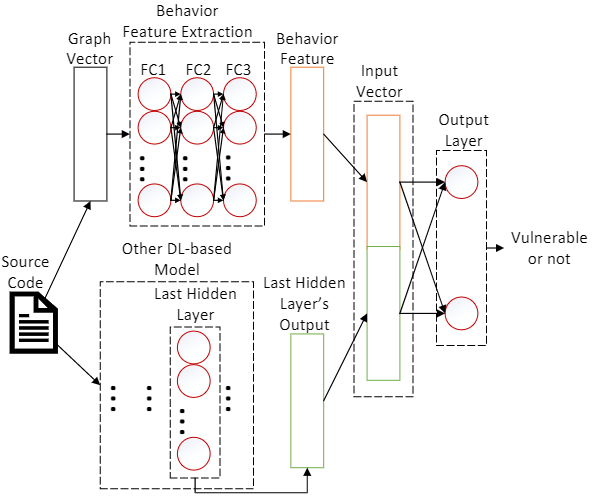
图4 行为特征提取与模型融合
表1 VulBG与基准模型的性能对比
详细内容请参见:
Bin Yuan, Yifan Lu, Yilin Fang, Yueming Wu, Deqing Zou, Zhen Li, Zhi Li, Hai Jin, "Enhancing Deep Learning-based Vulnerability Detection by Building Behavior Graph Model", In Proceedings of the 45th International Conference on Software Engineering (ICSE 2023), May 14-20, 2023, Melbourne, Australia, pp.2262-2274.
https://ieeexplore.ieee.org/document/10172844
声明:本文来自穿过丛林,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
