编者按
小编好像是沉寂得有短时间了大家久等了,但是都有在干活儿啦,接下来会推出来一系列在数据流通环节中需要匹配的技术基础设施以及从合规视角的认知和评价,宗旨还是希望我们的行业能够活力满满蒸蒸日上,这也是我们殚精竭虑夜以继日之所在。本期推送数据合规技术大佬张吉的思考与沉淀,谨供行业批评指正。
一、问题的缘起
PSI (Private Set Intersection)技术属于隐私保护计算技术,目前在众多业务领域中得到了广泛应用,即双方通过各自上传一个ID集合,经过PSI协议之后,得到双方交集的ID数据,非交际ID数据在密码学协议保护之下,双方均无法获取。
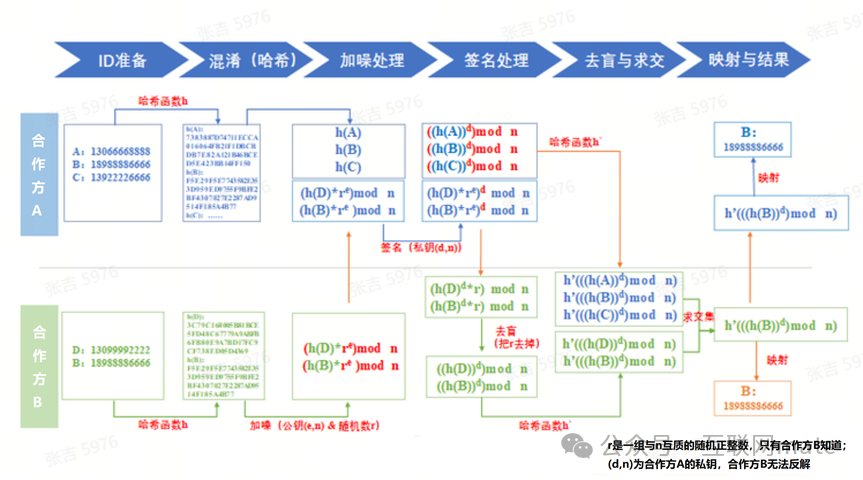
图1-传统PSI的技术原理
虽然传统PSI技术可以确保数据求交的双方无法获得各自的非交集数据,但求交并非数据处理终点,双方会在获得交集ID的情况下进一步对这些ID所匹配的其他数据(下文称“附属数据”)进行处理,传统PSI技术对这些附属数据的处理行为较难有正向合规和安全增益,同时传统PSI技术在合规维度依然存在未决顾虑,具体如下:
1.【暴露渠道来源信息】:交集ID数据本身会天然携带相关信息(至少包含交集用户渠道来源信息,这个信息的敏感程度,取决于这个渠道的性质),例如如果渠道信息仅仅只是“该用户是电商平台用户”,那么信息的敏感度相对不高,但如果渠道信息为“该用户是某个医院具体科室的病患”或者“该用户是某些敏感商品服务的购买者”,对于此类信息,即使不携带渠道信息以外的任何其他信息,也可能构成隐私侵入较强的个人信息。
2.【未保护附属数据】:通常在进行数据求交时不会仅仅只完成ID对齐,通常会附随ID数据携带其他数据(例如某个用户的商品交易信息等),也即附属数据,这些附属数据也可能会构成较为敏感的个人信息。
3.【交集数据原值暴露】:对于交集部分的数据,联合进行数据处理的双方均可以获取原值,较难证明数据在处理过程中实现了相对匿名化的效果。因此对于此类数据,在共享以及后续的数据处理阶段依然需要寻找个人信息处理的合法性基础。
二、基于新技术的合规与安全路径
针对上述传统PSI技术所存在的顾虑,解决思路如下:

如果有一项技术,能够实现上述解决思路设想的效果,那么无论对数据的相对匿名化认定还是数据处理的安全性保障来说,都会起到更为积极的效果。
2.PJC技术(Private Join and Compute)
为了解决上述PSI所存在的问题,一项新的隐私求交计算技术(PJC)似乎可以提供解决思路。一句话总结PJC技术即:通过综合运用确定性加密技术以及其他隐私保护计算技术(通常包含同态加密、差分隐私以及多方安全计算中的秘密分享思路),达到保护联合计算各方的交集数据、其他附属数据以及数据分析结果的隐私增强技术。
Google、Facebook 先后在2019、2020提出了类似的解决方案,来保障离线聚合广告归因、多方安全广告度量等场景中隐私。结合多方安全计算(MPC)、同态加密(HE)等技术来实现广告归因,已经成为国外技术方案的主流技术。
2.1 PJC技术原理
2.1.1 Google简单版本



2.1.2 Meta改进版本
Meta版本的方案主要基于ECDH盲化、Paillier同态加密以及secret-sharing技术,参考Meta的PS3I算法实现。需要达到的效果如下:
•技术处理后的主键ID数据对任何一方保持匿名性,即不能与原始用户产生关联。
•技术处理后的事件内容(即附属数据)对任何一方保持匿名性,即不能推断出附属数据与原始用户的关联性。
•具有相同主键ID的事件仍能够进行正确关联。
2.1.3 PJC技术原理
一方面,需要进行联合计算的双方,各自用各自私钥对各自的主键ID进行加密(A先对ID进行KeyA加密,进行打散混序后发送B,B对【KeyA(ID)】再进行加密,得到【KeyB(KeyA(ID))】;另一方面,对附属数据(例如购买信息),用另一个特殊密钥(例如同态密钥)进行加密,方便后续在密文维度进行同态计算;最后,对数据分析结果进行差分隐私保护(DP)。具体而言:
•【主键ID】:对于上述双重私钥加密数据【KeyB(KeyA(ID))】而言,在打散混序的效果影响下,任何一方(包括原始数据持有方)都无法仅凭借自己的密钥进行解密,也即一旦进行了上述技术处理,无论数据是否完成了求交,对于交集与非交集的数据,任何一方已经无法知悉数据原值。由于所采取的加密技术性质为确定性加密,所以可以直接在密文状态下进行密文相似度的比对,完全一致的密文即为交集密文,达到的效果为:联合计算的双方无法知悉哪些具体主键ID为交集数据,只能知悉交集数据的量级(关键节点即为:双重加密+打散混序)。
【笔者注】:对主键ID进行双重加密,可以基于合规目的进行适当改进(如何实现合规目的将在下文详细论述),思路如下:目前的技术步骤是A加密后打散发送给B,B再进行加密;改进后:各方事先约定/计算一个双重/多重密钥,在ID数据发生任何共享之前,在原先数据持有方各自域内先进行加密,完成之后再执行打散混序、共享与求交的步骤。
•【附属数据】:
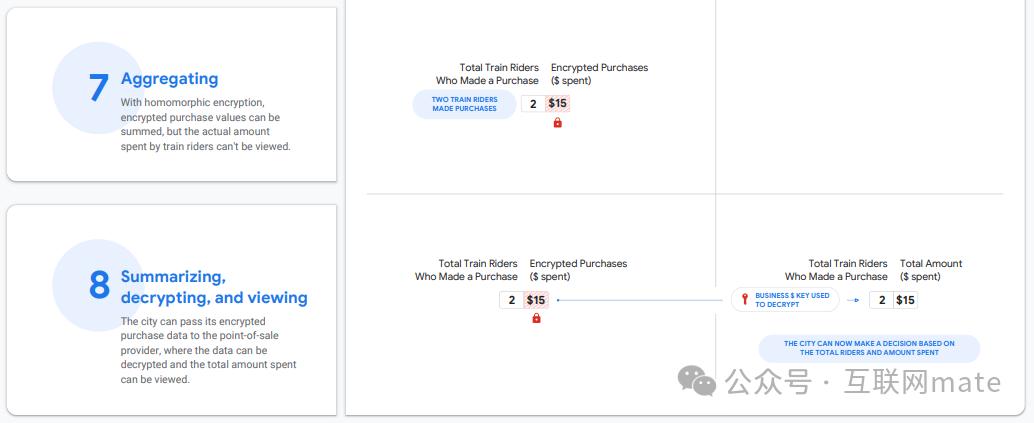
(1)同态加密(HE):主要是对需要进行加减乘除、排序或其他计算逻辑的附属数据(例如金额)进行应用。采取HE后,可以在密文上进行购买金额加总,同时又能确保购买者用户的个体粒度购买数据不被泄露。最后再配合交集人群,即可得到此类目标人群总体的购买金额分析数据。
(2)秘密分享(SS):主要是对需要进行加减乘除、排序或其他计算逻辑的附属数据(例如金额)进行应用,逻辑同HE,但是计算算子可以比HE更丰富。
3.【数据分析结果】:为了防止统计级别的分析报告遭受差分攻击,需要在最后对统计级别的分析结果进行差分隐私保护(DP)。
2.2 PJC用于解决传统PSI顾虑的效果
【特别注意】:PJC是否能够达到相对匿名化的效果,取决于应用该技术之后的数据处理目的是否限于输出统计级别的融合数据分析,若此类最终的数据处理目的并不指向个人信息,并且最终的数据分析结果也并不包含个人信息,那么可以认为PJC技术在整体上实现了相对匿名化的效果。

3.PJC技术合规分析
3.1 匿名化
《个人信息保护法》对匿名化定义如下:指个人信息经过处理无法识别特定自然人且不能复原的过程。该定义包含匿名化的两个维度的效果:(1)个人信息主体无法被识别或关联;(2)处理后的信息不能被复原。同时,前述(1)中,隐含另外一个争议问题:“无法被识别”是无法被谁识别?是否包含个人信息处理者在内?

从上表可知,要认定经某种技术手段处理之后个人信息是否达到匿名化效果,需要解决两个问题:(1)该技术是否对处理者本身有匿名化的效果;(2)该技术所达到的阻却识别以及无法复原的技术效果如何。
3.1.1 该技术是否对处理者本身有匿名化的效果
1.【主键ID数据】:根据上述对PJC技术特征的描述,尤其采取了在【主键ID共享出域前】就完成密钥设置与应用的技术方案下,相关主键ID可以实现对处理者本身达到匿名化的效果,即在经过【双重/多重加密+打散混序】的技术处理之后,处理者自身对于【KeyB(KeyA(ID))】这个数据亦丧失了与原始ID的关联关系,处理者自身无法获知该技术处理后的数据字段所映射的原始数据,亦无法逆向其原本所映射的用户身份,从技术效果来看可以达到对处理者本身的匿名化效果。
2.【附属数据】:在经过同态加密(HE)或者秘密分享(SS)技术处理后的事件内容(即附属数据)对任何一方保持匿名性,即任何一方均不能推断出处理后的数据与原始用户的关联性。此外,从数据的联合计算逻辑来说,相关附属数据需要依附在主键ID上进行联合计算,若主键ID已经对包含处理者在内的主体达到匿名化的效果,那么相关附属数据也应当具有类似效果。因此对于附属数据而言,从总体技术效果来看亦可以达到对处理者本身具有匿名化的效果。
3.【数据分析结果】:在使用了PJC技术之后对数据进行分析,其分析结果是纯统计级别的聚合数据,这部分数据从性质上已经不是个人信息。但为了防止可能的差分攻击,依然需要对聚合数据进行差分隐私保护。
4.【结论】:综合上述,在使用了PJC技术,且仅用于输出统计级别的聚合分析数据场景,无论对于主键ID、附属数据还是数据分析结果,均能够使得相关个人信息达到相对匿名化的效果。
3.1.2 该技术所达到的阻却识别和复原的效果如何
3.1.2.1 匿名化路径的选择
该问题涉及对个人信息匿名化认定的基本方向的问题。目前在认定匿名化时具有两种路径:绝对匿名化与相对匿名化。分别如下:
1.【绝对匿名化】
•若处理者或任何第三方能够通过其他手段重新识别到特定个人,那么无法达到匿名化效果。更进一步,之所以被称之为绝对匿名化,在于该观点认为:考虑到处理者或任何第三方可用来识别个人的【所有手段的可能性】,它主张无论可识别的可能性有多么渺小、技术上是否有现实可能性或是否需要耗费不成比例的成本实现这种识别,均应无条件适用数据保护法。
•本质上,这一理论意味着任何一个主体,只要拥有额外的重识别信息,那么个人信息就不可能完成匿名化处理。这种方法并不认为法律、强有力的合同在禁止重识别方面的规定/约定足以构成对重识别、非法处理个人信息行为的震慑,那么这就导致了一种完全不可行且不合常理的结论:个人数据匿名化的唯一途径等同于原始数据被彻底删除并且不再以任何形式存在的效果。该理论将严重限制数据的流通和使用。
2.【相对匿名化】
•该方法基于对处理者可用于重新识别到特定个人的【现实、可能的机会】展开评估与认定。与绝对方法的区别在于:只有存在那些可以由处理者或第三方实际用于重识别的技术手段才应被作为阻却匿名化的要素,可用于重识别的假设的、渺茫的可能性将不予考虑。
•该方法承认具备重识别可能性但发生风险较小的客观情况存在,但在评估匿名化时,需要将这些潜在的低概率风险排除在外。本质上,相对匿名化路径强调了需要考虑处理者和第三方进行重识别的【现实可能性】,包括主观意愿、技术、经济、人力和法律等层面的现实可行性。该理论为在保障数据安全的前提下释放数据价值提供了空间。
从上面对两个理论的描述来看,判定一项隐私保护计算技术所达到的阻却识别和复原的技术效果如何,需要考量采取何种路径,若采取【绝对匿名化】的路径,则无论采取何种技术都难以实现前述目标;只有采取【相对匿名化】路径才可能继续在综合要素的判断维度衡量与评估某项技术所达到的阻却识别和复原的效果如何,并基于可证实的效果,结合当下的数据处理目的验证技术的匿名化效果。
综合上述,我们在评价PJC技术所达到的阻却识别和复原的效果时,也应当基于相对匿名化的路径进行判断。
【笔者注】:匿名化认定的问题相对复杂,后续笔者将会开通匿名化系列,结合笔者的实务经验与理论研究进行进一步的探讨。
3.1.2.2 阻却识别和复原的效果
评价某项技术是否能够实现相对匿名化,也即是否能够阻却对个人信息的识别和复原效果,主要需要对下述的三个指标进行评估,如果经过某项技术处理后的个人信息,能够分别抵御下述三个指标中描述的识别、复原的风险,那么就可以称这项技术具备相对匿名化的效果。

由于本文篇幅所限,并且该项评估更偏向技术评估,因此本文暂不做深入讨论,未来笔者会针对各类技术对上述关键指标的抵御能力另开分析板块进行讨论。由于PCJ技术采用同态加密和多方安全计算技术,这两类技术目前在抵御个人信息识别和复原维度已有诸多技术验证,并且欧盟的相关研究计划和所发布的官方指引已经在逐步认可此类技术的不可识别、复原效果,因此本文将对此类技术的抵御识别、复原效果予以认可。
综合上述,笔者个人倾向于认为,在采取了PJC技术对主键ID和附属数据进行处理后,可以达到相对匿名化的效果。
3.2 使用PJC技术对个人信息进行处理时不同阶段的数据保护法适用
【前提】:采取了在主键ID【共享出域前】就完成密钥设置与应用的技术方案。




四、结语
数据要素的流通是新时代数字经济、科技产业的重要驱动力。个人信息作为数据要素的重要组成部分,在流通过程中的核心是确保其处理的合法性与安全性,隐私保护计算技术在这个过程中应当起到关键作用。隐私保护计算技术目前在研发层面已经具备一定深度,在产业应用维度也具备一定规模,虽然该项技术在大规模商业应用场景下依然存在诸多待突破的节点,例如算力问题、性能问题等,但其对合法、安全处理个人信息、促进数据要素流通依然具有不可忽视的潜力。当然,隐私保护计算技术要能够真正发挥作用,更核心的问题是个人信息匿名化的认定需要有立法、执法层面的支持。笔者非常关注个人信息匿名化的认定,也对欧盟的立法、实践进行了研究,后续笔者将会开通匿名化系列,结合笔者的实务经验与理论研究进行进一步的探讨。
声明:本文来自互联网mate,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
