工作来源
NDSS 2023
工作背景
互联网上加密恶意流量的占比在显著增长,超过所有恶意流量的七成。已知的检测方法无法同时检测加密恶意流量和非加密恶意流量,二者的特征存在显著差异。
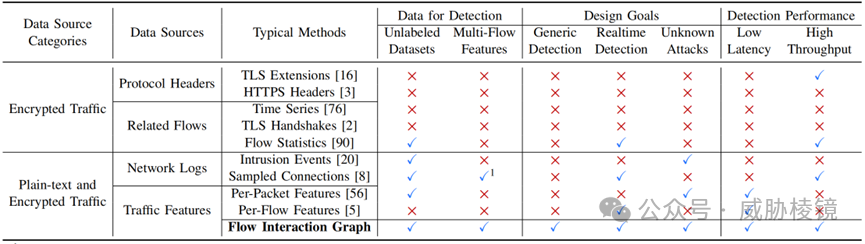
使用 IP 地址作为顶点,传统的四元组作为边构建的稠密图不能反映流的交互模式。并且互联网上的大多数流都很短,而大量的包与超长流有关。
工作设计
实时加密恶意流量检测系统 HyperVision,能够检测加密恶意流量与非加密恶意流量的攻击。由于单流的加密恶意流量与良性流量十分相似,但攻击者与受害者间交互模式的差异则更为明显。
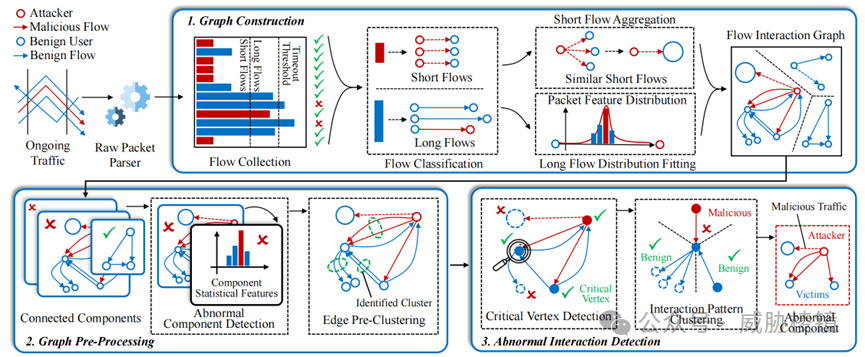
图构建
HyperVision 首先将流量分为短流和长流。通过聚合海量相似短流来降低图的密度,再对长流的包特征分布进行拟合,尽可能地保留流交互信息。最终构建点边通联的流交互图。借此方法解决传统方法中流特征粒度过粗,存在信息密度下降的问题。
流量分类
获取每个数据包的源 IP、目的 IP、端口号、协议、包长与到达间隔等数据包特征。长短流分类算法如下所示,核心是维护一个 HASH(SRC, DST, SRC PORT, DST PORT) 为Key、以数据包特征为 Value 的哈希表。其中,用于判断流完成时间的 PKT_TIMEOUT 被设置为 10 秒、流内包数 FLOW_LINE 阈值被设置为 15。

短流聚合
如果通过传统方式用四元组构造边,就没法进行分析了。由于大多数短流的数据包特征几乎相同,可以进行聚合来降低图密度。

聚合算法如下所示。满足以下条件时,短流会被聚合:
源IP相同或者目的IP相同
协议相同
流的条数超过 AGG_LINE(被设置为 20)
聚合成一条边后,为所有流及其四元组保留一个特征序列(协议、包长和到达间隔)。短流会有四种边,源 IP 地址聚合边、目的 IP 地址聚合边、双端 IP 地址聚合边与非聚合边。值得注意的是,点可能是一个 IP 地址也可能是一组 IP 地址。

通过聚合可以减少 93.94% 的点与 94.04% 的边。聚合使存储开销大幅度降低,才能够将图结构保存在内存中。
长流特征拟合
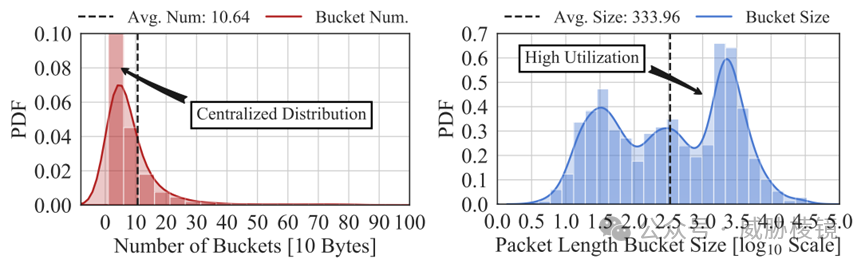
此前有研究使用直方图拟合反映 P4 交换机上的硬件流表,此处用类似的方法来拟合长流。此前研究也发现粗粒度的流统计数据不足以进行加密恶意流量监测,还会丢失流交互信息。
使用包长为 10 字节、到达间隔为 1 毫秒构建直方图。可以看出,长流中的绝大多数数据包都有相似的包长和到达间隔。
图预处理
基于流交互图提取连通分量,再利用统计数据对连通分量进行聚类。通过聚类检测出仅具有良性交互模式的连通分量,过滤掉这些连通分量可以进一步降低图的规模。
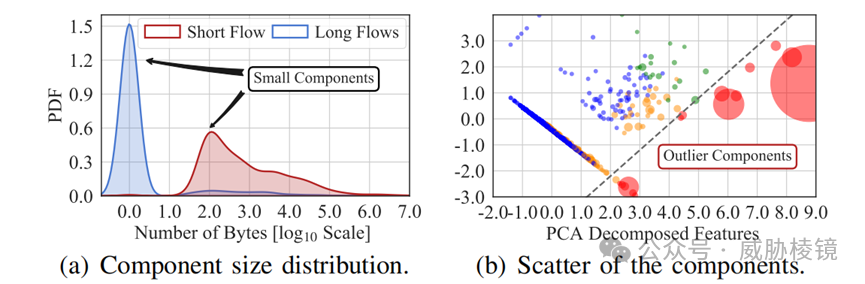
连通性分析
通过深度优先搜索获取连通分量,可以发现大部分连通簇包含具有相似交互模式的边。提取连通簇的五个特征(长流数量、短流数量、短流边数量、长流字节数、短流字节数)后,使用基于密度的聚类(DBSCAN)计算到中心的距离。距离超过 99 百分位时,即为异常情况。
边预聚类
大多数边其实都与特征空间中相似边相邻,使用 DBSCAN 进行预聚类、KD-Tree 进行局部搜索,选择已识别簇的中心代表簇中的所有边,进一步降低图的规模。
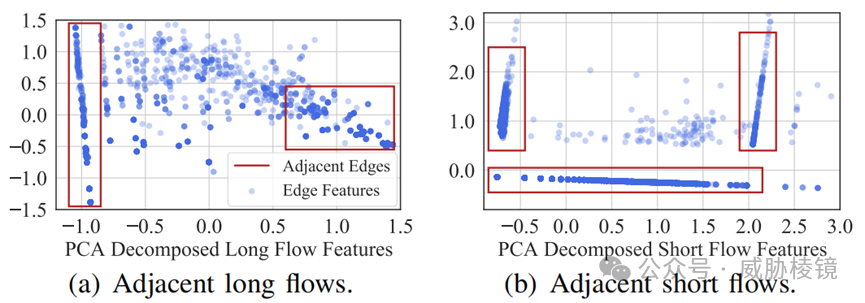
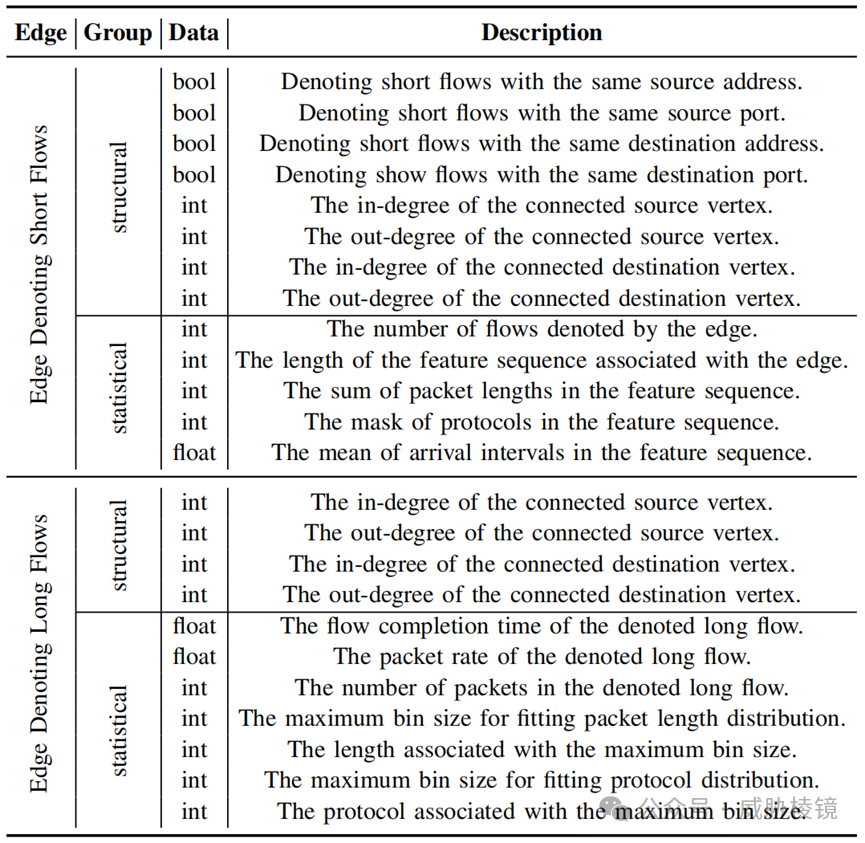
为长短流提取了 24 个特征,包括出度与入度。
异常检测
首先识别图中的关键点,后续根据流特征和反映流交互模式的结构特征对所有边进行聚类,实现无监督检测。最后通过计算聚类的损失函数来实时识别异常边。
识别关键点
满足以下条件的即为关键点:
每条边的源 IP 或目的 IP 都在子集中,确保所有边都连接到一个以上的关键点并至少聚类一次
子集中选定的顶点数最少,确保最小化聚类次数
利用 Z3 进行求解,发现关键点。
边特征聚类
使用的特征如前所述,此处使用 K-Means 算法对长短流相关的边进行分别聚类。根据聚类损失衡量恶意程度,losscenter 表示与连接到关键点的其他边的差异、losscluster 表示预聚类涵盖的时间范围(越持久的交互越可能是良性的)、losscount 是流的数量(流数的爆发往往是恶意的)。
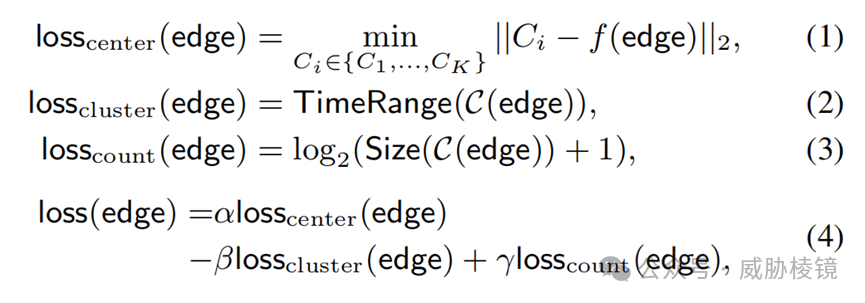
工作准备
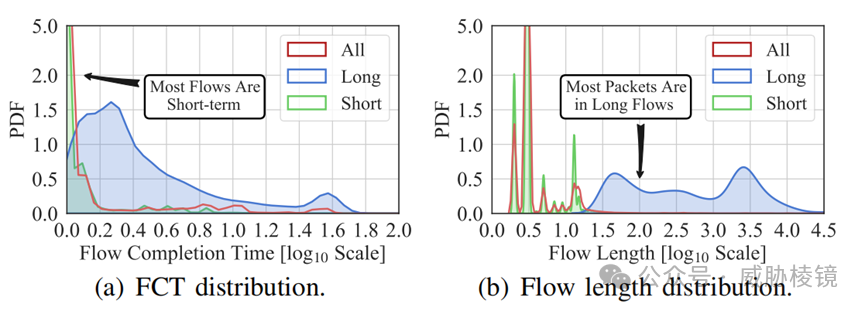
2020 年 1 月 MAWI 互联网流量显示,流完成时间(FCT)与流长度分布如下所示。只有 5.5% 的流的 FCT 大于两秒。尽管长流在个数上只占 2.36%,但却占了 93.7% 的数据包数。
近万行代码实现了 HyperVision 的原型,通过 GCC 9.3.0 与 CMAKE 3.16.3 编译。
Mlpack(3.4.2)提供的 DBSCAN 与 K-Means 算法与 Z3 SMT Solver(4.8)。
硬件环境为 Intel Xeon E5645+24GB内存+Intel 82599ES 10 Gb/s 网卡+Intel 850nm SFP+光口。
背景流量还混杂了四大类恶意流量:恶意软件相关加密流量、加密的 Web 攻击、加密的洪水攻击与传统的爆破攻击。
工作评估
通过三个指标来进行评估:
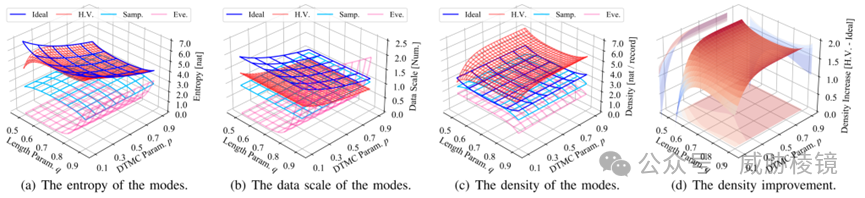
信息量,数据包平均香农熵
数据规模,存储信息所需空间
信息密度,单位存储信息量
与三种流记录方式进行比较:
记录整个数据包特征序列的理想模式
记录特定事件的事件模式(Zeek)
记录粗粒度流信息采样模式(Netflow)
作者确认 HyperVision 的方法保留了更多信息,保持的信息量几乎与理论最优值相当。比传统流采样和基于事件的流日志多保留了 2.37 倍与 1.34 倍信息熵。在信息密度上,HyperVision 提升了 1.46 倍、1.54 倍与 2.39 倍。
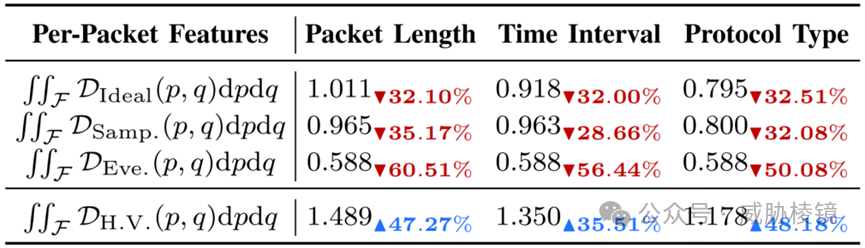
与单包特征对比,HyperVision 可以将信息密度提升 35.51% 到 47.27%。
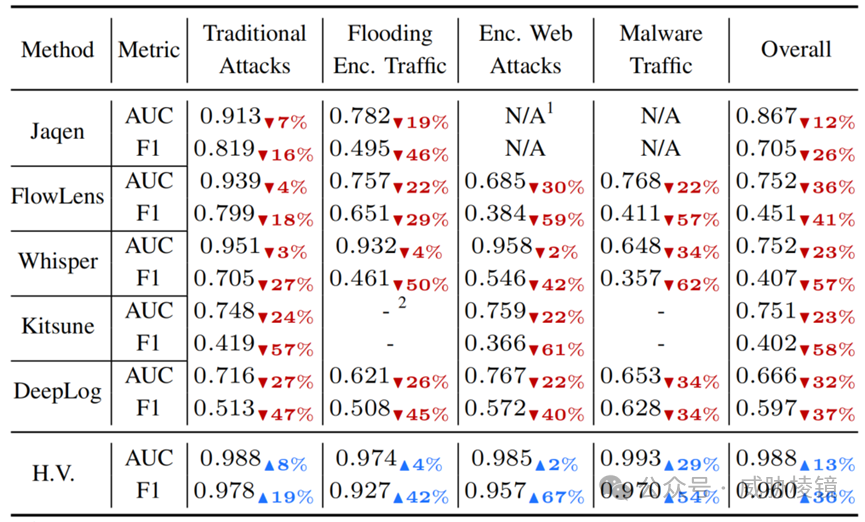
恶意攻击的检测效果不错:
恶意流量的子图模式如下所示:
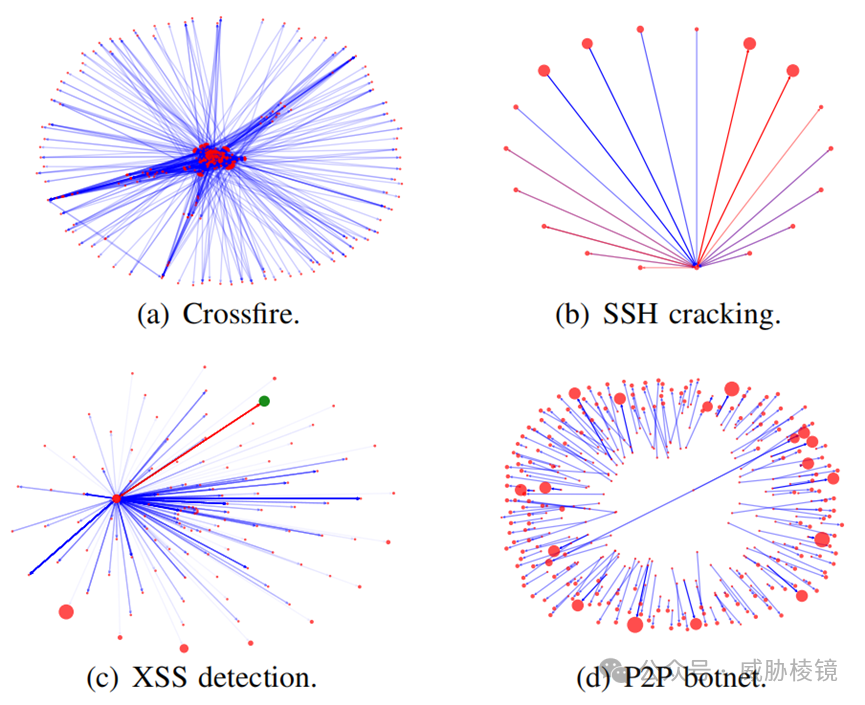
各类恶意软件的加密流量也能检测:

工作思考
海量数据处理时,如何在少丢失信息的情况下尽量压缩数据的规模是十分关键的。本文给出了可以尝试的思路,并且作者在实时场景下性能如此高,也是让人眼前一亮的。
声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
