工作来源
CoNEXT 2022
工作背景
单独看 Netflow 数据无法了解对应的服务,单独看 DNS 数据无法了解流量大小,那么将二者结合起来看呢?
工作设计
整体架构如下所示。由于 Worker 的多个实例会同时访问保存 DNS 数据的共享数据结构,需要将 DNS 数据拆分并分发到不同的分片,尽可能让分片间隔离。设计只关心来源 IP 地址,但修改为目的 IP 或者源 IP 与目的 IP 也是简单的。
99% 的 A/AAAA 与 CNAME 记录的 TTL 都小于 3600 秒与 7200 秒。以此作为记录的过期时间,达到阈值即全部清除。保存 DNS 记录的数据机构为 Hashmap,响应值为 Key、请求值为 Value。
设计了三级 Hashmap 结构,新数据都存在活跃 Hashmap 中,达到阈值后将活跃 Hashmap 的数据更新到非活跃 Hashmap 中,并清活跃 Hashmap。如果 TTL 比阈值还大,会被放入持久 Hashmap 中。
DNS 数据处理

首先要检查是不是有效的 DNS 响应数据,符合要求的放入 FillUp 队列。每个 FillUp Worker 从 FillUp 队列中拉取数据,如果是 A/AAAA/CNAME 记录就存入 Hashmap:
IP-NAME Hashmap:IP 与域名的对应关系
NAME-CNAME Hashmap:域名与 CNAME 域名的对应关系
Netflow 数据处理

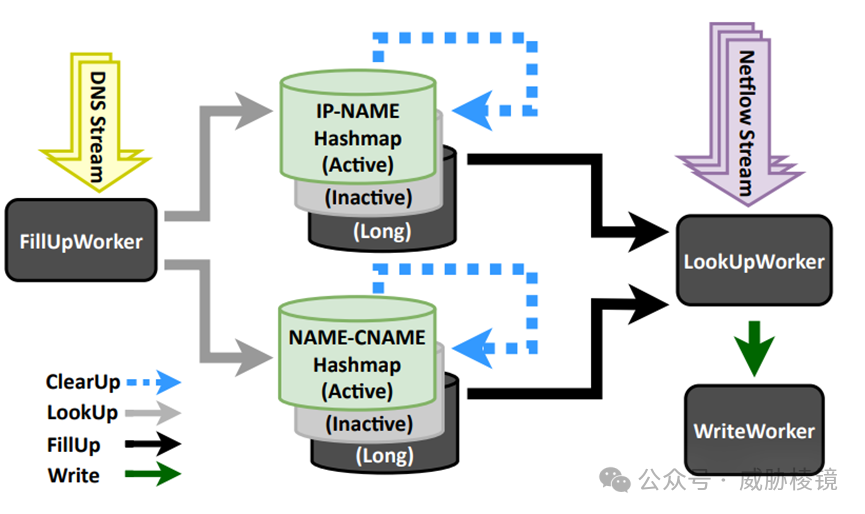
和 DNS 数据差不多的处理流程,只是要在 Hashmap 查 IP 与域名的对应关系。值得注意的是,CNAME 的关系最多嵌套查六次(只有不到 1% 的 CNAME 链会超过 6 次)。
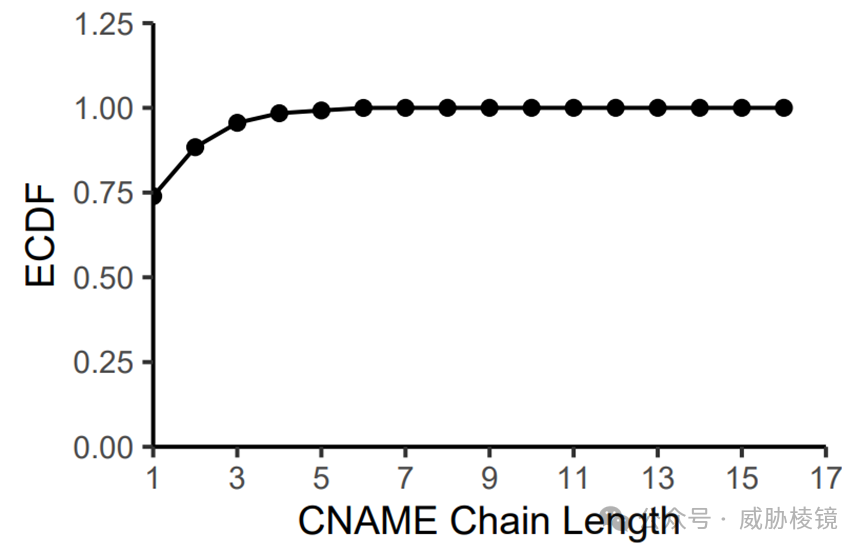
经过测试发现这些设计都是必要的,要么是可以提高关联率、要么是可以降低资源使用率。
No Split:Hashmap 不被切分成多片
No Clear-Up:Hashmap永远在内存中不清除
No Rotation:Hashmap 清除但取消非活跃 Hashmap
No Long Hashmaps:取消持久 Hashmap
工作准备
数据来自欧洲大型 ISP:
① DNS 数据:拆分成 2 条流,平均每秒 7.5 万条 DNS 记录
② Netflow 数据:拆分成 26 条流,平均每秒 1 百万 Netflow 记录
在欧洲小型 ISP 也进行了测试,每秒11.5 万条DNS 记录、每秒 13.8 万条NetFlow 记录。
设备为 128 核 CPU、756 GB 内存的 Ubuntu 18.04.5 TLS 服务器
工作评估
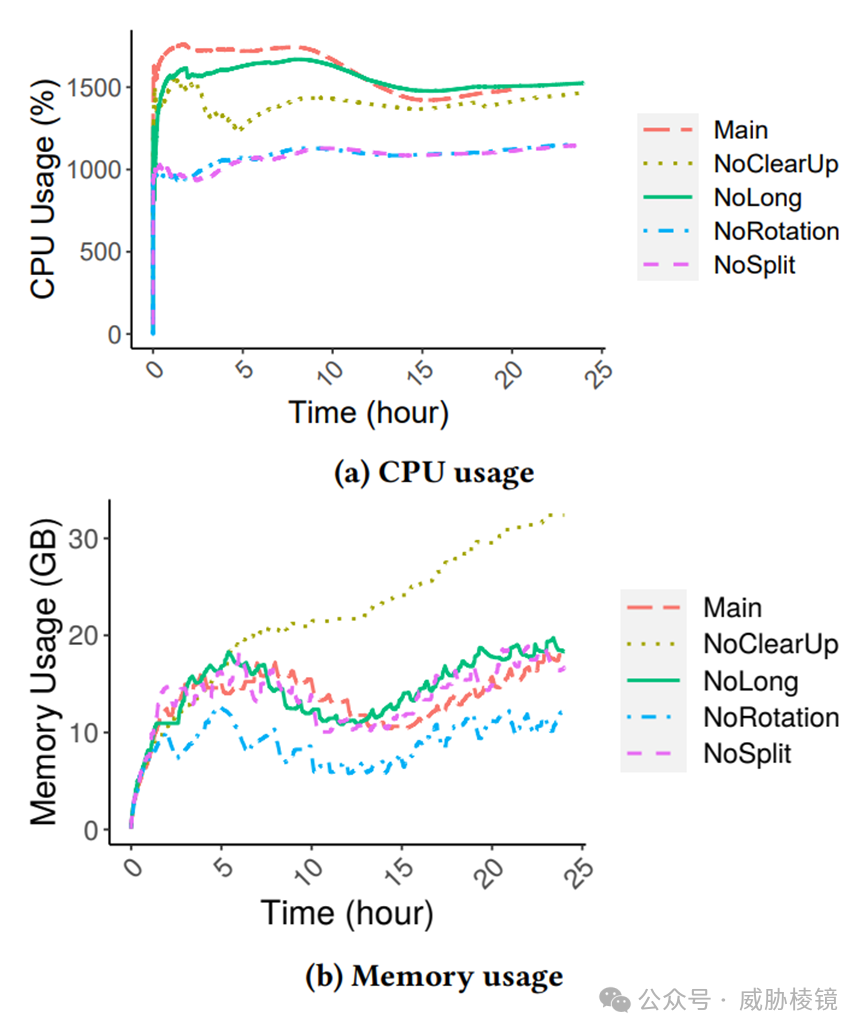
大型 ISP 场景下使用 25 核、15-30 GB 内存,小型 ISP 场景下使用 3 核、6 GB 内存。
只有 81.7% 的流量可以关联上,18.3% 的流量无法进行关联。毕竟这种方式不能百分比覆盖所有的 DNS 请求,并且不是所有网络行为都必须要走 DNS 请求。分析数据可以发现,每 20 个 DNS 数据包(53/DNS、853/DoT)就有 1 个是请求公共 DNS 服务器的,也就是说 DNS 数据的覆盖率约为95%。
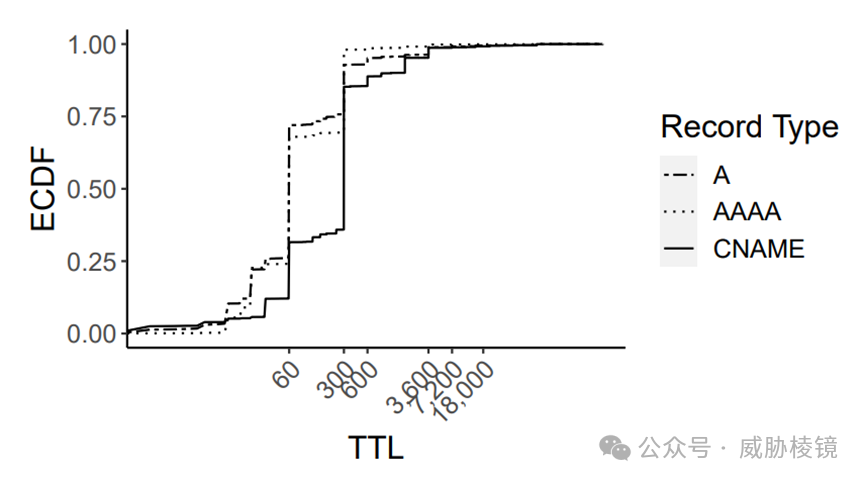
这样的关联方式,如果不同域名拥有相同的 IP 的话,所有流量都会关联到第二个域名。统计数据发现 70% 的 DNS 记录的 TTL 小于三百秒:
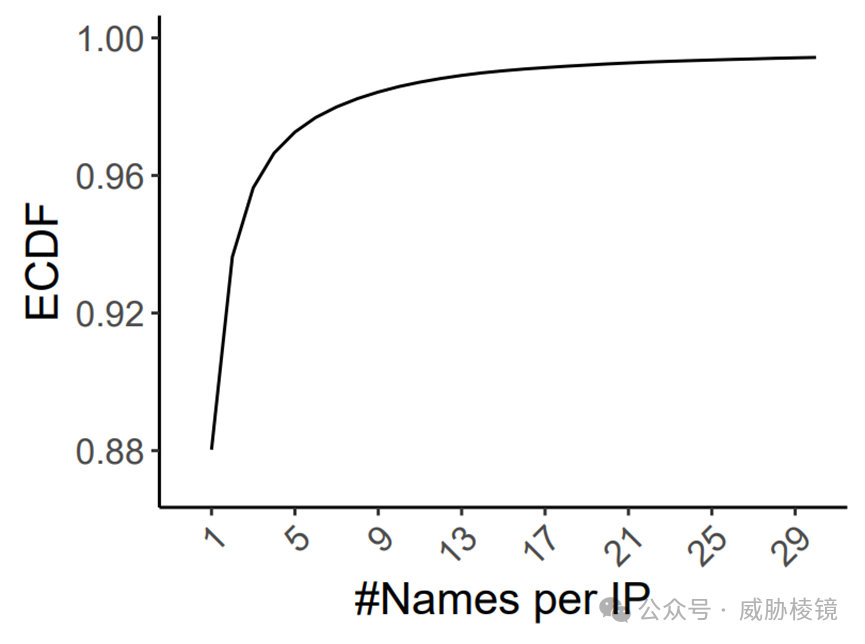
88% 的 IP 地址仅映射到单个域名,因此一个 IP 对应多个域名的情况影响并不大。
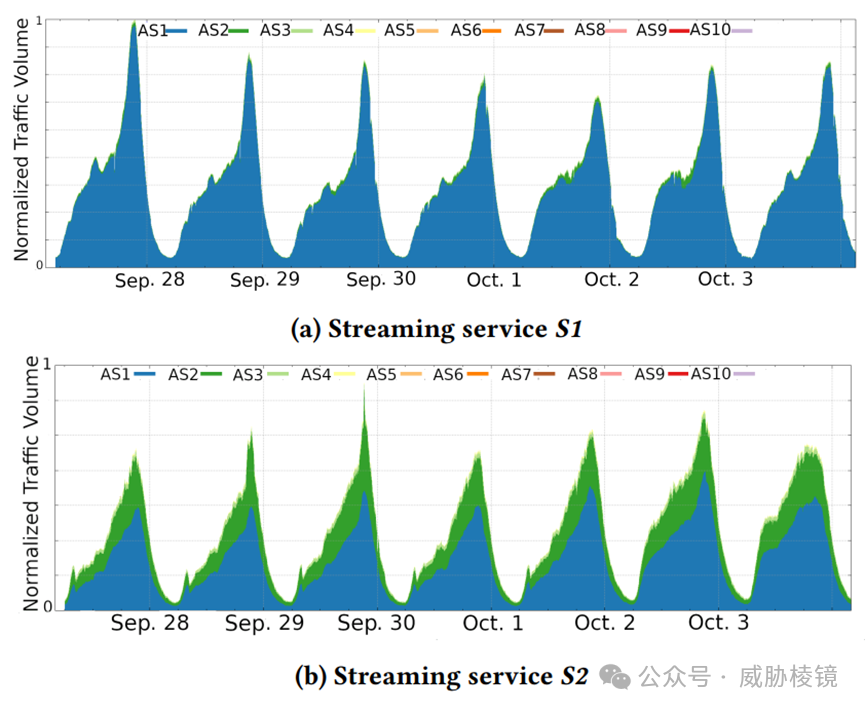
流媒体服务 S1 的流量主要来自一个自治系统,流媒体服务 S2 的流量主要来自两个自治系统。
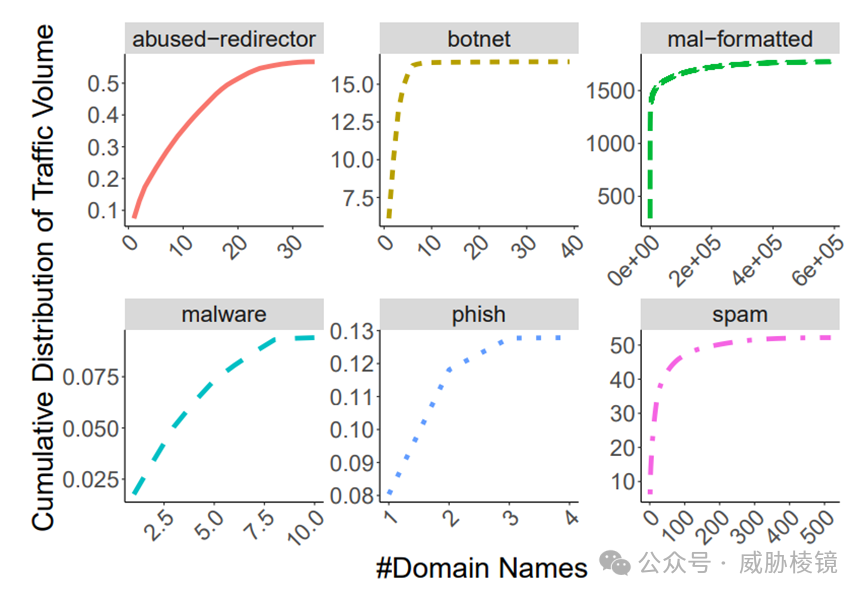
垃圾邮件域名
每小时的一百万个域名中,有 612 个域名被Spamhaus DBL 认为是可疑域名。这些域名产生了数 TB 的流量,大量的流量来自垃圾邮件与僵尸网络,极少的域名就产生的很大的流量。
无效域名
不严格(RFC 1035)地验证 DNS 是否无效,只靠以下约束:
(1)域名总长度不超过 255 字节
(2)域名每部分最长 63 字节
(3)每部分以字母开头,以字母或者数字结尾,其中可以存在连字符
一天的流量中可以发现 66.6 万个无效域名。
工作思考
作者将 Go 的代码开源了,感兴趣的可以下载翻看。
https://github.com/maganiss/FlowDNS声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
