本文作者 | 邱雪涛、费志军
01 引言
在人工智能领域,大语言模型的广泛应用正引领着一场深刻的技术变革。随着这些模型在各行各业中的深入渗透,其性能与效果的准确评测变得愈发关键。评测技术的重要性在此背景下凸显无疑,主要体现在以下四个方面:
(一)评测技术是大语言模型技术选型的重要标准。
(二)评测技术是模型优化与改进的依据。
(三)评测技术能够指导资源进行高效配置,避免浪费。
(四)评测技术的发展还能够促进模型间的竞争与合作,加速技术迭代。
02 大语言模型评测体系
(一)大语言模型评测体系构建原则
大语言模型评测体系构建需解决任务多样性与评测标准问题,主要分为以任务为核心和以人为核心两大原则。
以任务为核心的评测体系尝试从传统的自然语言任务为基础推导和制定大语言模型的评测体系,选择评测任务场景的原则包括:覆盖率;最小化所选场景集合;优先选择与用户任务相对应的场景。
以人为核心的评测体系关注模型解决人类任务的普适能力,通常采用标准化考试如高校入学考试等来衡量大语言模型的认知能力,选择评测任务场景的原则包括:强调人类水平的认知任务;与现实世界场景相关。
(二)大语言模型评测任务
通过大语言模型评测体系的分析研究,整体上可以将大语言模型评测任务分为五个方面:通用能力、复杂推理、垂直领域、智能体交互以及伦理与安全。
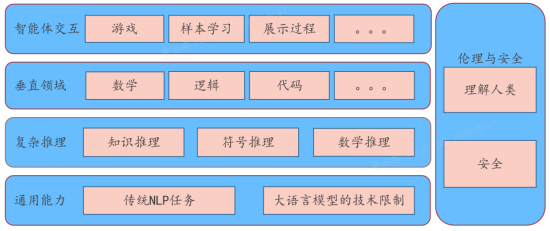
图: 大语言模型评测任务
(三)大语言模型评测方法
在大语言模型评测体系中,评测方法是需要研究的核心要点,评测方法的目标是解决如何对大语言模型生成结果进行评估的问题。
1.自动评测
自动评测通常包括文本质量评估、语义准确性评估、语言模型性能评估等。自动评测中有些指标可以通过比较正确答案或参考答案与系统生成结果来直接计算得出,例如准确率、召回率等。
2.人工评测
人工评测是一种广泛应用于评估模型生成结果质量和准确性的方法。在大语言模型的评测中,对于文章的流畅性、逻辑性、观点表达等方面的评估需要人工阅读并进行分项打分。
3.大语言模型辅助评测
利用能力较强的语言模型(如 GPT-4)构建合适的指令来评估系统能力,这类方法被称为大语言模型辅助评测。评测人员将任务说明、待评测样本以及对大语言模型的指令输入到提供评估辅助的大语言模型中,随后大语言模型会评估结果输出。
(四)评测数据集
大语言模型的应用越来越广泛,为了更好地评估大语言模型的性能,评测数据集的梳理变得尤为重要,因此国内外出现了SuperGLUE、HELM、BIG-bench、OpenCompass等知名大语言模型评测数据集。当前大语言模型评测存在不足:
1.评测方法僵化,类似应试题刷榜,仅依赖特定任务和数据集,无法全面反映模型在复杂场景中的真实表现。
2.在数据基准上评测内容与具体业务脱节,忽视实际应用价值,且可能存在数据偏见,影响评估公正性。
3.现有评测体系在安全性评估上不足,无法满足金融行业对高安全标准的需求,这可能对企业声誉和客户信任造成重大影响。
03 结语
随着大语言模型评测技术的不断发展,多样化的评测体系如雨后春笋般涌现,这些体系从多个维度全面审视模型能力。然而,以刷榜为目的的评测已逐渐失去其实际意义,真正重要的是结合具体应用场景进行精准评测。未来,我们期待评测技术能更加贴近实际,为模型的优化与落地应用提供有力支撑。
|| 本文作者:中国银联金融科技研究院 邱雪涛、费志军
|| 声明:本文所涉及言论仅代表作者个人观点,仅供参考、交流之目的
声明:本文来自电子商务与支付国家工程研究中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
