在现代军事行动中,实时快速处理和分析大量传感器数据的能力至关重要。对于严重依赖复杂算法进行信号分析的电子战 (EW) 系统来说,尤其如此。实现实时数据处理和分析是一项重大挑战,因为传感器数据的复杂性和数量不断增加,往往会造成瓶颈,阻碍及时决策,影响任务成功。
传统的数据处理方法在吞吐量、延迟和资源利用率方面都存在问题,难以满足EW系统的需求。
然而,更令人担忧的是,算法本身也变得越来越庞大和复杂。许多工程团队不具备处理这种复杂性的专业知识,这就推动了对专注于算法加速/优化的专家的需求。
本白皮书探讨了算法优化的关键作用,通过为国防客户加速 EW 算法,实时将原始数据转化为可操作的洞察力,以更少的资源利用率提供更好的性能。白皮书还介绍了如何通过成熟代码、提高性能和降低功耗来提高这些算法的技术成熟度(TRL),从而使其能够在更真实的EW硬件上运行,而不是在实验室环境中运行。
在本白皮书中,系统架构师和设计工程师将了解到:
● 军方对实时数据处理和传感器融合的要求如何推动创新。
● 军事网络中数据过载的挑战以及确定性数据传输对关键任务应用的重要性。
● 通过优化人工智能(AI)算法和先进处理技术增强EW系统的实用解决方案。
● 演示性能和资源利用率显著提高的算法优化实际案例。
● 算法优化的好处,包括增加吞吐量、减少延迟和提高效率。
● 将研究算法转化为高性能实时应用的过程。
算法和处理挑战
传统的数据处理方法和算法在处理电子战系统的吞吐量、延迟和资源利用率需求时面临很大的限制。这些限制会严重影响任务的成功。传感器数据的复杂性和数量不断增加,加剧了这些挑战,使传统算法难以跟上步伐。
传统的数据处理挑战包括:
● 吞吐量:快速处理大量数据的能力往往不足,从而导致延迟。
● 延迟:处理和分析数据所需的时间可能过长,妨碍实时决策。
● 资源利用率:计算资源的低效利用会导致更高的能耗和有限的处理能力。
然而,最大的挑战在于算法开发。实时将原始数据转化为现实可行的算法,其计算复杂越来越高,还有许多有前途的算法尚未实现实时吞吐量和延迟。
这些算法涉及从神经网络到统计建模的方方面面,需要耗费大量的时间和资源。许多仅作为研究项目存在的算法已经过优化,可以很好地实现其功能,而速度和资源要求仍是次要考虑因素。
开发这些算法的人员可能不具备充分发挥这些流程潜力所需的工程专业知识,他们的时间可能更适合用于进一步的算法改进。
工程师团队可以优化这些算法的软件实现,并将其移植到图形处理器 (GPU) 或现场可编程门阵列 (FPGA),从而提高吞吐量和延迟,使其能够用于实时应用。
要解决这些问题,迫切需要改进能够实时处理数据的人工智能算法。优化这些算法可以显著提高吞吐量、减少延迟并提高资源利用率。
算法分析与优化
第一步是了解算法。为此,DornerWorks 团队与算法开发人员合作,收集算法的基准性能数据,评估其当前的吞吐量、延迟和资源利用率。
然后,测试数据将用于验证算法在任何更改后的功能。将确定实时实施的吞吐量和延迟要求,并了解目标硬件的规格,以确定资源利用率要求。见图 1。
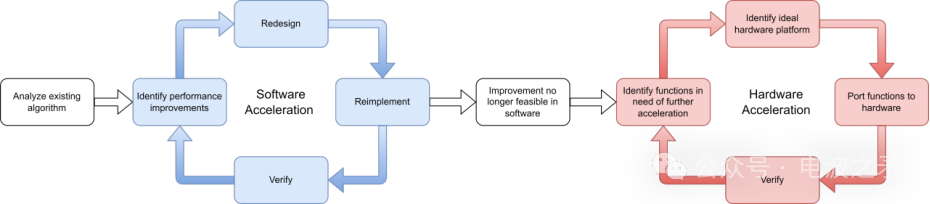
图 1:DornerWorks 算法加速流程。
优化软件和硬件加速可完善代码、提高性能并降低功耗。
软件加速
这是一个迭代过程,DornerWorks 工程师将尽可能在 CPU 上运行的软件中优化算法,然后再尝试移植到不同的硬件平台。可能只有部分算法需要进行硬件加速,因此算法的其余部分必须尽可能在软件中实现高性能。
如果算法尚未使用 C 或 C++ 语言,则应将其翻译为 C++。这不仅是因为 C/C++ 比其他语言(如 python 或 MATLAB)更快,还因为它能更透明地表示内存中发生的事情,使加速更容易。C/C++ 代码也更容易移植到 HLS(高级合成)工具,从而缩短 FPGA 开发时间。
迭代过程的第一步是确定算法中可能存在的性能改进。然后,团队将重新设计算法架构,以利用这些改进性能。一旦制定了计划,就会根据新的架构重新实施算法。最后一个阶段是验证性能的提高,并与算法开发人员一起验证算法的功能。
这一过程不断重复,直到进一步确定软件算法加速不可行为止。
硬件加速
硬件加速过程也是反复进行的。硬件加速过程的第一步是对算法进行剖析,找出在中央处理器(CPU)上性能较差的功能。团队会检查性能不佳的代码,并确定最适合进一步加速的硬件平台(FPGA 或 GPU)。
将代码的相关部分移植到选定的硬件平台后,再次与原始算法开发人员验证算法的功能,然后对算法进行评估,以确定其是否满足吞吐量和延迟要求。如果算法尚未实时运行,则重复上述过程,直到算法运行速度足够快为止。
通过这一加速/优化过程,可以提高这些算法的 TRL,使其适合部署在实际的 EW 硬件上,而不仅仅是实验室环境。
实际应用
以下三个案例研究重点介绍了 DornerWorks 应用其优化流程的实例。
案例研究 1:实时处理的算法加速
● 原始实施:要处理 10 秒钟的数据,原始算法需要 26 分钟,使用了 24 个 CPU 内核中的 15.4 个,运行了 145.2 万亿条指令。
● 优化执行:加速实现将处理时间缩短至 7 秒,仅使用了 24 个 CPU 内核中的 7.2 个,运行了 5040 亿条指令。这一优化大大提高了性能,同时降低了资源利用率。
案例研究 2:CPU 和 GPU 优化
● 原始实施:仅 CPU 的原始实施需要 33 分钟才能处理 10 秒钟的数据。
● 优化后的实施:通过同时利用 CPU 和 GPU,将处理时间缩短到了 9 秒。这种混合方法证明了软件和硬件优化技术相结合的有效性。
案例研究 3:利用现场可编程门阵列(FPGA)提高能效
● 人工智能图像分类器:在 Nvidia RTX 3090 GPU 上运行人工智能图像分类器算法的功耗为 332 瓦。而在 AMD ZCU208 FPGA 上运行相同的算法仅消耗 15.5 瓦,却能实现类似的 FPS 性能。这表明,通过 FPGA 优化,可以大大节省功耗并提高效率。
利用 FPGA
对于优化工作而言,FPGA 已成为 CPU 的有力替代品。与 GPU 相比,它们的功耗要低得多,因此非常适合电力资源有限的边缘计算。
较低的功耗可减少发热量,这对保持 EW 系统的可靠性和使用寿命至关重要。
未来方向与创新
算法优化为 EW 系统设计人员提供了巨大优势,但 还有许多利用这种方法的机会。以下是几个例子:
● 先进的人工智能和机器学习 (ML):先进人工智能和 ML 技术的整合将彻底改变EW系统。这些技术可以增强信号处理、威胁检测和决策能力,为不断变化的威胁提供更强大的适应性响应。可以通过探索这些创新技术,以进一步优化EW算法。
● 边缘计算:边缘计算在军事应用中的重要性与日俱增,它能在更靠近源头的地方处理数据,从而减少延迟并改进实时决策。FPGA 功耗低、发热少,是边缘计算的理想选择。利用 FPGA 实现边缘应用,提高EW系统的性能和可靠性。
● 量子计算:量子计算虽然仍处于萌芽阶段,但具有显著加快复杂计算和数据处理任务的潜力。关注量子计算的发展,以评估其在EW系统和算法优化中的适用性。
● 跨领域应用:为EW系统开发的技术和科技可应用于其他军事领域,如网络安全、通信和自主系统。探索这些跨领域应用,以便在各种军事行动中扩大优化算法的优势。
● 持续研究与合作:与学术机构、行业合作伙伴和国防组织的持续研究与合作对于保持技术进步的领先地位至关重要。持续的研究工作和合作伙伴关系,以推动创新并提高EW系统的能力。
结论
DornerWorks 凭借其在 FPGA 开发和算法优化方面的专业知识,在将研究级算法转化为高性能、实时应用以部署到关键任务环境中方面发挥着至关重要的作用。
要成功加速复杂算法,需要在实时系统上实施算法的工程师与设计算法的专家通力合作。
PS:回复240807可获得原文
声明:本文来自电波之矛,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
