作者简介
张政
浪潮电子信息产业股份有限公司产品总监,计算机科学与技术博士后,主要从事计算机体系结构、异构计算等方面技术研究和产业化工作。
冯少飞
浪潮电子信息产业股份有限公司高级产品经理,计算机科学与技术博士后,主要从事计算机体系结构、绿色计算方面技术研究和产业化工作。
论文引用格式:
张政, 冯少飞. 大模型算力基础设施技术趋势、关键挑战与发展路径[J]. 信息通信技术与政策, 2024, 50(6): 2-9.
大模型算力基础设施技术趋势、关键挑战与发展路径
张政 冯少飞
(浪潮电子信息产业股份有限公司,北京 100089)
摘要:从大模型技术发展趋势出发,分析了多模态、长序列和混合专家模型的架构特征和算力需求特点。围绕大模型对巨量算力规模与复杂通信模式的需求,重点从算力利用效率、集群互联技术两方面量化分析了当前大模型算力基础设施存在的发展问题和面临的技术挑战,并提出了以应用为导向、以系统为核心、以效率为目标的高质量算力基础设施发展路径。
关键词:多模态模型;长序列模型;混合专家模型;算力利用效率;集群互联;高质量算力
0 引言
近年来,生成式人工智能技术,尤其是大语言模型(Large Language Model,LLM)的快速发展,标志着人工智能进入了一个前所未有的新时代。模型能力的提升和架构的演进催生了新的算力应用范式,对所需的算力基础设施提出了全新的挑战。
1 大模型技术发展趋势
1.1 大语言模型
最初的语言模型主要基于简单的统计方法,随着深度学习技术的进步,模型架构逐步从循环神经网络(Recurrent Neural Network,RNN)到长短期记忆(Long Short Term Memory,LSTM)再到Transformer演进,模型的复杂性和能力相继提升。2017年,Ashish Vaswani等[1]首先提出了Transformer架构,这一架构很快成为了大语言模型开发的基石。2018年,BERT[2]通过预训练加微调的方式,在多项自然语言处理任务上取得了前所未有的成效,极大地推动了下游任务的发展和应用。2018—2020年,OpenAI相继发布了GPT-1、GPT-2和GPT-3,模型的参数量从1 亿级别增长到1 000 亿级别,在多项自然语言处理任务上的性能呈现近似指数级的提升,论证了尺度定律(Scaling Law)在实际应用中的效果[3]。2022年底,ChatGPT发布之后,引发了一轮LLM热潮,全球诸多企业、研究机构短时间内开发出LLaMA、文心一言、通义千问等上百种大语言模型。这一时期的模型大都基于Transformer基础架构,利用大量的文本数据进行训练,通过学习大规模数据集中的模式和关系,能够执行多种语言任务。但是,LLM的发展很快遇到了两个显著的问题,一是模型的能力局限于对文本信息的理解和生成,实际的落地应用场景受限;二是稠密模型架构特征将会使得模型能力提升必然伴随着算力需求的指数级增加,在算力资源受限的大背景下模型能力进化的速度受限。
1.2 多模态模型
为了进一步提升大模型的通用能力,研究者开始探索模型在非文本数据(如图像、视频、音频等领域)中的应用,进而发展出了多模态模型。这类模型能够处理和理解多种类型的输入数据,实现跨模态的信息理解和生成。例如,OpenAI的GPT-4V模型可以理解图片信息[3],而Google的BERT模型则被扩展到VideoBERT用于理解视频内容[4]。多模态模型的出现大大扩展了人工智能的感知能力和应用范围,从简单的文本处理到复杂的视觉和声音处理。多模态模型在基础模型架构上跟LLM一样大都采用Transformer,但是通常需要设计特定的架构来处理不同类型的输入数据。例如,它们可能结合了专门处理图像数据的卷积神经网络(Convolutional Neural Networks,CNN)组件,需要使用跨模态的注意力机制、联合嵌入空间或特殊的融合层来实现对来自不同模态信息的有效融合。
1.3 长序列模型
研究者们发现通过扩展上下文窗口可以让大模型能够更好地捕捉全局信息,有助于更准确地保留原文的语义、降低幻觉的发生、提高新任务的泛化能力,这就是提升大模型能力的另外一条有效的路径——长序列(Long Sequence)。2023年以来,主流大模型都在不断提高长序列的处理能力(见图1),比如GPT-4 Turbo可以处理长达128 K的上下文,相比较GPT-3.5的4K处理能力已经增长了32倍,Anthropic的Claude2具备支持200 K上下文的潜力,Moonshot AI的Kimi Chat更是将中文文本处理能力提高到了2 000 K[5]。从模型架构上来看,传统的LLM训练主要对Transformer中耗时最多的两个核心单元——多头注意力层(Multi-Head Attention,MHA)和前馈神经网络层(Feedforward Neural Network,FNN)进行张量并行,但保留了归一化层和丢弃层,这部分元素不需要大量的计算但随着序列的长度增加会产生大量的激活值内存。由于这部分非张量并行的操作沿着序列维度是相互独立的,可以通过沿序列维度切分实现激活值内存的减少。然而,序列并行(Sequence Parallelism,SP)的增加会引入额外的全聚集(All Gather)通信操作。因此,长序列的训练和推理会使得计算复杂度和难度提升,计算复杂度随序列长度n呈平方增加O(n2),模型需要引入新的并行层次和集合通信操作,从而导致端到端通信耗时占比增加,将会对模型算力利用率(Model FLOPS Utilization,MFU)产生影响。
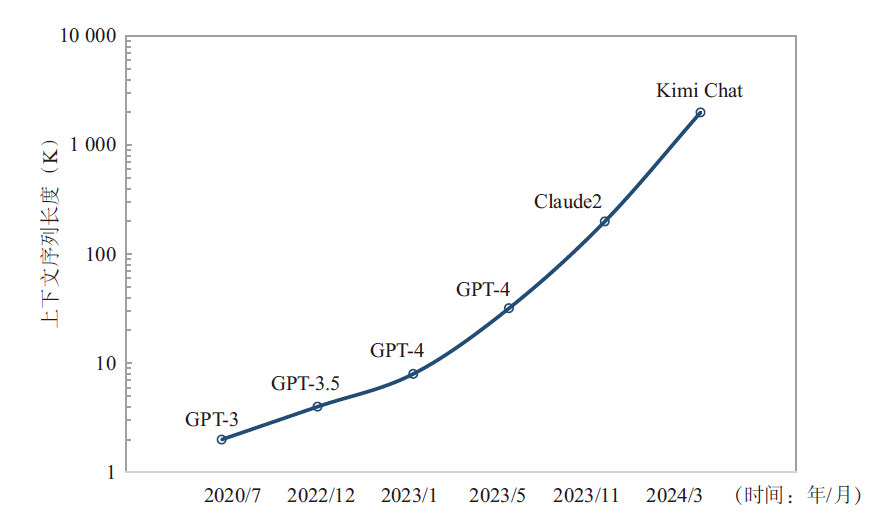
图1 大模型上下文序列长度发展趋势
1.4 混合专家模型
为了在提高模型能力的同时能够优化算力开销,研究者们选择引入条件计算机制,即根据输入有选择地激活部分参数来进行训练,这样就使得整体计算开销随模型参数量的增长趋势相对变缓,这就是混合专家(Mixture of Experts,MoE)模型的核心思想。MoE模型实际构建了一种稀疏型的模型组件,将大型网络分解为若干个“专家”子网络,每个专家擅长处理特定类型的信息或任务,通过一个门控网络,在给定输入时动态选拔最适合的专家参与计算,这样既可以减少不必要的计算量,也能提高模型的专业性和效率。Google早在2022年就发布了具有1.6 亿参数的MoE模型Switch Transformer,包含2 048个专家,在同样的FLOPS/Token的计算量下,Switch Transformer模型相比稠密型的T5-Base模型训练性能有7倍的提升[6]。
MoE模型通过这种方式,在保持模型性能的同时,相比同等规模的稠密模型显著降低了计算资源的需求,在处理大规模数据和任务时表现出了更高的效率和可扩展性。如今MoE模型已经成为了业界大模型的发展趋势,2024年3月以来,已经先后出现了GPT4、Mixtral-8×7B、LLaMA-MoE、Grok-1、Qwen1.5-MoE、Jamba等10余种MoE模型[3,7-8]。但是,MoE模型层的引入同时也带来了额外的通信开销,相比较LLM训练过程常用的张量并行、流水线并行和数据并行之外,MoE模型的训练引入了一种新的并行策略——专家并行(Expert Parallelism,EP),需要在MoE模型层前后分别增加一次多对多(All-to-All)通信操作[9],由此带来了对硬件互联拓扑和通信带宽的更高要求。
根据上述分析,多模态、长序列、MoE模型已经成为大模型架构演进的确定性趋势,其中多模态、长序列模型侧重在模型能力侧的提升,MoE模型兼顾模型能力的提升和算力利用效率的优化。这种发展不仅提升了人工智能在内容理解和内容生成方面的能力,而且提高了模型的泛化能力和任务适应性。然而,模型架构的演进同时带来了更巨量的算力需求以及更复杂的集合通信需求,对现有算力基础设施带来了更大挑战。
2 大模型算力基础设施发展问题与挑战
2.1 可用算力规模亟需算力利用效率提升
业界先进的(State-Of-The-Art,SOTA)模型参数规模和数据规模仍在持续增长,巨头之争已经从千亿模型向万亿模型发展(见图2),GPT-4模型具有1.8万亿参数,在约 13万亿个Token上进行了训练,算力需求大约为2.15e25 FLOPS,相当于在大约2.5万张A100加速卡上运行90~100天[10]。为此,领先的科技公司正在加速算力基础设施建设,Meta在原有1.6万张A100卡集群基础上又建设两个具有约2.5万张H100加速卡集群,用来加速LLaMA3的训练;Google建设了具有2.6万张H100加速卡的A3人工智能超级计算机,可以提供26 ExaFLOPS的人工智能性能,Microsoft和OpenAI正在为GPT-6训练构建具有10万张H100加速卡集群,并规划具有数百万张卡的“星际之门”人工智能超算[11]。由此可见,万卡已经成为未来先进大模型训练的新起点。

图2 大模型算力需求发展趋势
随着算力需求持续增加、算力规模持续扩大,算力利用效率问题日益凸显。据公开报道[10],GPT-4训练的MFU在32%~36%之间,其根本原因是显存带宽限制了芯片算力的发挥,即“内存墙”(Memory Wall)问题。在LLM模型的训练过程中,模型参数、梯度、中间状态、激活值都需要存放在显存当中,并且需要频繁地传输参数和梯度信息以进行参数的更新。高显存带宽可以加快参数和梯度数据的传输速度,从而提高参数更新的效率,加速模型收敛的速度。因此,用于人工智能训练的高端加速卡会选用最先进的高带宽内存(High Bandwidth Memory,HBM)作为显存,以求最大化数据传输速度,增加计算时间占比,从而获得更高的算力利用效率。
从宏观技术发展趋势上看,在过去20年间芯片的算力峰值以每2年3倍的速度增长,但是内存的带宽增长速度只有1.6倍[11]。内存的性能提升速度远低于处理器的性能提升速度,这就使得芯片计算力和运载力之间的剪刀差越来越大,仅通过增加处理器数量和核心数,也无法有效提高整体的计算能力。为此,NVIDIA从V100开始,在每一代芯片中间都会有一次显存升级,以A100为例,首发版本采用40 G HBM2显存,带宽最高1 555 GB/s,升级版本采用80 G HBM2,带宽提升至2 039 GB/s,但这带来的算力利用效率和应用性能提升效果有限,A100 80 G在Bert-Large微调场景下性能提升仅14%(见图3)。
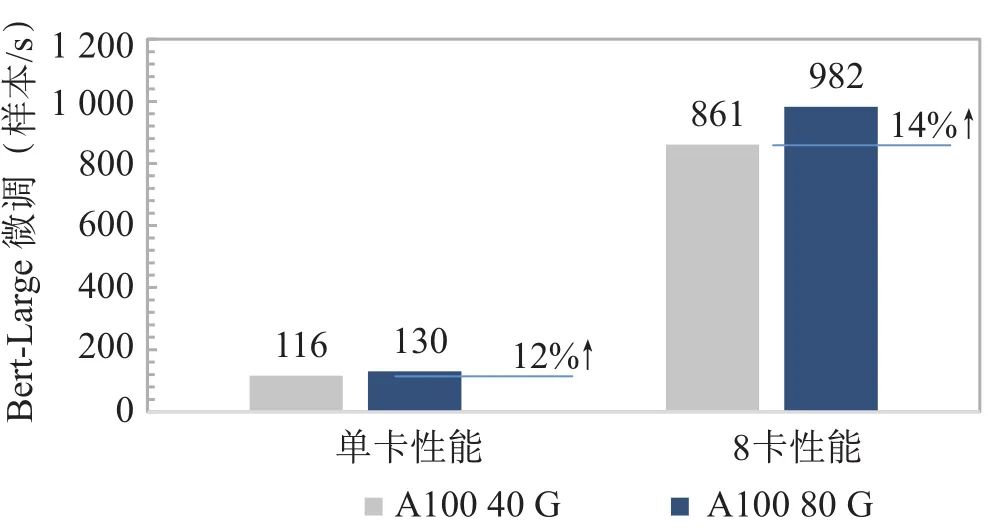
图3 相同算力下不同显存带宽A100模型性能对比
为了能够量化显存带宽对芯片算力利用效率的影响,采用具有相同显存(容量96 G、带宽2.45 TB/s)、不同算力的人工智能加速卡,在具有不同参数规模大小的LLM模型预训练场景中进行了算力效率的实测。如图4(a)所示,在使用BF16算力精度训练LLaMA-7B模型的过程中,BF16算力利用率随芯片算力的降低而显著增加,对于具有443 TFLOPS算力值的芯片而言,其算力利用率只有54%,而具有148 TFLOPS算力的芯片,算力利用率达到了71.3%,这意味着显存带宽限制了高算力芯片的算力利用效率。同样的规律也反映在了LLaMA-13B和GPT-22B等更大参数规模的模型预训练实测结果中。如图4(b)所示,当标称BF16性能从148 TFLOPS增加到298 TFLOPS,即标称算力增加2倍的情况下,可用算力增加仅1.8倍,或者说算力损失29.6%;当BF16性能进一步从298 TFLOPS继续增加到443 TFLOPS,即标称算力增加48.8%的情况下,可用算力性能仅增加22.4%,算力损失高达42.1%。由此可以推断,算力性能进一步提高所带来的可用算力收益会由于显存带宽的限制呈现边际递减,即GPT-4训练的MFU只有不到40%的原因。可以看出,“内存墙”是限制当前可用AI算力扩展的最大瓶颈。
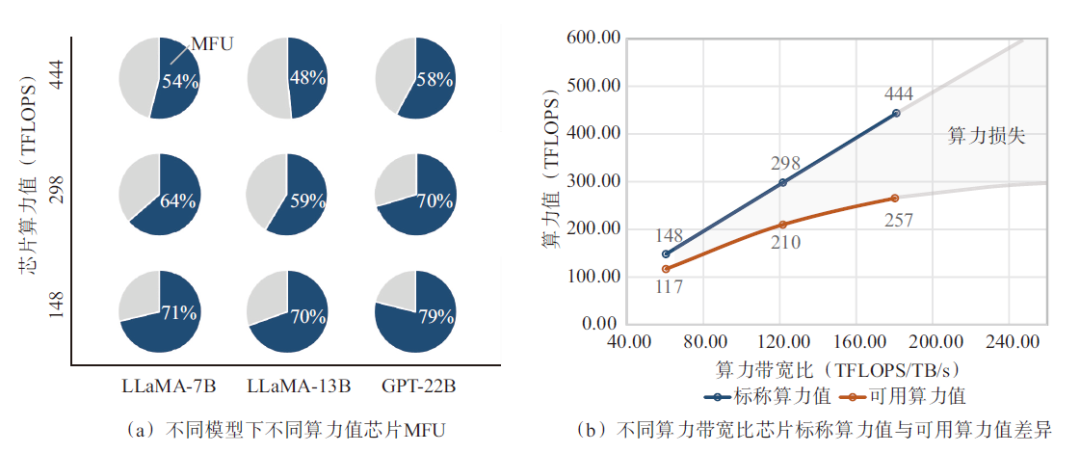
图4 显存带宽对算力利用效率影响
2.2 集群性能提升依赖跨尺度、多层次互联
在尺度定律的驱动下,SOTA模型的参数量以每2年410倍的速度增长、算力需求以每2年750倍的速度增长[12],遵循“摩尔定律”的硬件算力增长速度和显存容量增长速度远远无法满足模型训练的需求。因此,构建多芯互联集群成为大模型技术发展的必经之路,能够支持SOTA模型训练集群的规模也在短时间内从千卡向万卡发展,集群性能的实现将会受到显存带宽、卡间互联带宽、节点间互联带宽、互联拓扑、网络架构、通信库设计、软件和算法等多重因素影响,大规模加速计算集群的构建已经演变成为跨尺度、多层次的复杂系统工程问题。
从应用层面来看,大模型训练往往需要通过有机的组合多种分布式策略,来有效地缓解LLM训练过程中的硬件限制。对于基于Transformer架构的模型来说,常用的分布式策略包括数据并行、张量并行和流水线并行,各自的实现方式和所引入的集合通信操作有所不同。其中,数据并行和流水线并行的通信计算比不高,通常发生在计算节点之间。张量并行的核心思想是对Transformer Block中的两个核心单元——多头自注意力层和前馈神经网络层进行拆分,其中多头自注意力层按照不同的头进行并行拆分,而前馈神经网络层按照权重进行并行拆分。使用张量并行时,每个Transformer Block将在前向计算和反向传播时分别引入两次额外的All Reduce通信操作。与数据并行相比,张量并行具有更高的通信计算比,这意味着张量并行算法对计算设备间的通信带宽需求更高。因此,在实际应用中,一般把张量并行算法限制在单个计算节点内。如前文所述,随着大模型进一步向多模态、长序列、混合专家架构演进,分布式策略也随之更加复杂,序列并行和专家并行的引入,也带来了更多All Gather和All-to-All通信操作,与张量并行类似,需要计算设备间超低延迟、超高带宽的通信能力,从而进一步提高对单个计算节点或者说计算域的性能要求。
从硬件层面来看,互联的设计一方面需要满足算力高效扩展的需求,另一方面还要匹配并行训练集合通信对互联拓扑的要求。互联设计可以按尺度分为片上互联、片间互联和节点间互联。片上互联物理尺度最小、技术难度较高,需要采用芯粒(Chiplet)技术将多个Chiplet进行合封并建立超高速互联链路,领先的芯片厂商AMD、Intel、NVIDIA、壁仞科技等公司的产品都采用相关技术。以NVIDIA的B100芯片为例,由于逼近光刻工艺极限,芯片单位面积计算能力较上代只有14%提升,性能的进一步提升只能通过增加硅面积,但这又受到掩膜极限的限制。于是,NVIDIA在尽可能做大单晶粒面积的基础上,通过更先进的基片上芯片(Chip on Wafer on Substrate,CoWoS)工艺将两个晶粒整合到一个封装当中,之间通过10 TB/s NVLink进行互联,使得两个芯片可以作为一个统一计算设备架构(Compute Unified Device Architecture,CUDA)在GPU运行。由此可见,在当前工艺极限和掩膜极限下,通过先进封装和高速晶粒对晶粒互联可以进一步推动芯片性能提高,但是这条技术路线的封装良率和高昂成本也将会极大限制最新芯片的产能,影响芯片的可获得性。
相比片上互联,片间互联的技术成熟度更高、可获得性更优,通常这部分互联发生在单一节点或超节点内部,旨在构建多卡之间超高带宽、超低延迟的计算域,来满足张量并行、专家并行和序列并行极高的通信需求。目前,已经有NVLink、PCIe、RoCE(RDMA over Converged Ethernet)以及诸多私有互联方案。从互联速率来看,NVIDIA第5代NVLink单Link双向带宽从第4代NVLink的50 GB/s升级到100 GB/s,也就是说B100/B200片间互联双向带宽最高可以达到1 800 GB/s,AMD的Infinity Fabric最大可以支持112 GB/s 点对点(Peer-to-Peer,P2P)互联带宽。从互联拓扑形态来看,片间互联可以分为直连拓扑和交换拓扑两大类,直连拓扑的通用性更强、协议兼容性更高,如AMD MI300X、Intel Gaudi、寒武纪MLU系列等开放加速规范模组(OCP Accelerator Module,OAM)形态加速卡可以通过通用加速器基板(Universal Baseboard,UBB)实现8卡全互联,NVIDIA H100 NVL、AMD MI210、Intel Gaudi3(HL-338)等PCIe形态加速卡则可以通过桥接器实现2卡或4卡互联,直连拓扑的问题在于片间互联均分每卡的输入/输出(Input/Output,I/O)总带宽,导致任意两卡间P2P互联带宽较低,互联带宽的提升依赖于SerDes速率的升级,相较算力提升速度滞后。交换拓扑需要基于交换机(Switch)交换芯片,目前主流芯片厂商中只有NVIDIA提供基于NVSwitch的互联方案,所有GPU的纵向扩展(Scale-up)端口直连到NVSwitch以实现全带宽、All to All互联形态,这也是NVLink带宽远高于直连拓扑方案的原因。未来,随着单卡算力的提升以及单节点内加速卡数量提升,基于Switch芯片构建更高带宽、更大规模的GPU互联域将成为一种趋势,但是如何实现Scale-up网络的延迟优化、拥塞控制、负载均衡以及在网计算也将成为新的挑战。
节点间横向扩展(Scale-out)互联作用主要是为参数面网络中流水线并行和数据并行提供足够通信带宽,通常采用Infiniband或RoCE组成胖树(Fat-Tree)无阻塞网络架构,二者都能够通过多层组网实现千卡乃至万卡级集群互联,比如采用64端口交换机,通过3层Fat-Tree无阻塞组网理论上可以构建约6.6万卡集群,采用128端口交换机理论上可以构建约52.4万卡集群。从节点侧来看,Scale-out的设计分为外置网络控制器和集成网络控制器两种类型,外置网络控制器方案通用性更强,PCIe标准形态的网络控制器通常会按1∶1或者1∶2的比例与加速卡连接到同一颗PCIe Switch芯片上以实现最短的Scale-out路径,可以根据现有数据中心网络基础设施设计来灵活选择与之相匹配的网络控制器类型和数量组成远程直接内存访问(Remote Direct Memory Access,RDMA)网络方案,支持Infiniband卡、以太网卡以及定制智能网卡。集成网络控制器方案将网络控制器直接集成到加速卡芯片当中,比较有代表性的如Intel Gaudi系列,Gaudi2每颗芯片支持直出300 Gbit/s Ethernet Scale-out链路,Gaudi3将带宽进行了翻倍升级达到600 Gbit/s,计算和网络的同步在芯片内完成,无需主机干预,可以进一步减小延迟。数据中心内部的节点间互联方案已经相对成熟,但随着GPU集群建设规模的不断扩大,节点间互联方案的成本和能耗也在不断提升,在中等规模集群当中占比已达15%~20%。因此,需要面向实际应用需求,平衡性能、成本、能耗三大要素,最终实现全局最优的节点间互联方案设计。此外,大模型头部公司正在规划的具有百万卡级的集群,已经超出现有网络架构可扩展极限,而单一数据中心无法同时为如此规模的卡提供足够的电力支撑。未来,超大规模跨域无损算力网络将会是支撑更大规模模型训练的关键。
综上,随着大模型算力需求的增长,加速集群互联技术已经演变成为跨尺度、多层次的复杂系统工程问题,涉及芯片设计、先进封装、高速电路、互联拓扑、网络架构、传输技术等多学科和工程领域,需要以系统为核心,自上而下软硬协同设计才能获得最优的集群性能。
3 大模型算力基础设施高质量发展路径
随着SOTA大模型训练算力起点从千卡向万卡乃至更大规模演进,能源逐渐成为大模型发展遇到的主要瓶颈,在算力资源和电力资源的双重限制下,未来大模型的军备竞赛将会从“算力之争”演变为“效率之争”,优化算力供给结构,发展具有高算效、高能效、可持续、可获得、可评估五大特征的高质量算力已经成为当务之急。
算力效率的提升要围绕算力的生产、聚合、调度、释放形成一个完整的技术体系[12]。在算力生产环节,算力和显存带宽的设计失衡往往是导致算力效率损失的主要因素。因此,芯片“算力-显存”协同设计至关重要,需要以算力效率为目标来平衡芯片的计算能力和显存的运载能力,避免显存带宽约束下的巨大算力损失。在算力聚合环节,通过“算力-互联”协同设计和“算力-网络”协同设计,采用高、低速域分层互联架构,为芯片匹配合适的片间互联和节点间互联带宽,解决通信性能瓶颈,可以进一步提升芯片在实际业务模型下的MFU,提升集群层面投资回报率。在算力调度环节,通过全面的监控指标和异常检测快速定位软硬件故障,通过断点续训、故障容错等机制快速恢复训练,实现大模型长时间稳定训练,以此提升集群算力整体利用率,降低大模型整体训练成本。在算力释放环节,兼容主流生态,支持业界主流框架、算法和计算精度,能够在最短时间内利用最新的精度优化、显存优化以及通信优化上的算法创新成果发掘出有限算力的最大价值。
能源利用效率的提升需要以节能为目标,开展面向应用、软硬协同的集群方案设计,在高算效服务器系统硬件基础上,通过匹配实际可用算力规模的网络方案实现设计层面的集群功耗优化。进一步,通过部件、系统、机柜、数据中心多层级先进液冷技术的应用,结合供电、散热、制冷、管理一体化设计实现部署层面的能效提升,最终获得全局最优电源使用效率(Power Usage Effectiveness,PUE)。
此外,大模型算力基础设施已经成为推动信息产业核心技术发展的重要驱动力,需要聚拢核心部件、专用芯片、电子元器件、基础软件、应用软件等国内外产业链领先技术方案,加速构建分层解耦、多元开放、标准统一的产业链生态,降低对单一技术路线的依赖、避免烟囱式发展,通过产业链协同创新实现可持续算力演进和算力产业的健康发展。持续推动算力基建化,采用融合架构,通过硬件重构实现多元异构算力资源池化,提供多元、弹性、可伸缩扩展的算力聚合能力,通过软件定义实现资源池的智能高效管理,提供更高效、更便捷的算力调度能力,降低多元算力的使用门槛,实现算力普适普惠。最后,还需要建立以应用为导向、以效率为目标、全面科学的高质量算力评估标准,推动算力供给结构优化,促进算力产业良性发展。
4 结束语
在市场、资本、政策的联合驱动下,大模型快速向多模态、长序列、混合专家形态演进,参数量更加庞大、模型架构日益复杂,从而带来对更大规模算力和更复杂通信模式的需求。然而,算存失衡发展严重限制了算力利用效率,并带来了巨大的算力资源损失,实际可用算力规模增速难以满足应用发展需求。随着集群规模从千卡向万卡发展,跨尺度、多层次互联技术将成为未来集群性能扩展效率的关键。在算力和电力资源的双重限制下,大模型军备竞赛正在向效率之争快速转变,亟需围绕算力生产、聚合、调度、释放四大环节构建高算效实现的完整技术体系,从集群设计和数据中心部署层面实现更高能效,最终形成可持续、可获得、可评估的高质量算力。
Large model computing infrastructure technological trends, key challenges, and development trajectories
ZHANG Zheng, FENG Shaofei
(IEIT SYSTEMS Co., Ltd., Beijng 100089, China)
Abstract: Starting from the latest technological development trends of large models, this paper first analyzes the architectural characteristics and computing power demand features of multimodal, long sequence, and mixture of experts models. Further, it focuses on the requirements of the latest large models for massive computing power scale and complex communication patterns. It quantitatively analyzes the current development problems and technical challenges faced by large model computing infrastructure from two aspects: computating efficiency and cluster interconnection technology. Finally, it proposes a high-quality computing infrastructure development trajectory oriented by applications, centered on systems, and targeted at efficiency.
Keywords: multimodal model; long sequence model; mixture of experts model; computating efficiency; cluster interconnection; high-quality computing power
本文刊于《信息通信技术与政策》2024年 第6期
声明:本文来自信息通信技术与政策,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
