
为抵制深度伪造音频技术被恶意攻击者滥用,针对伪造音频的检测方法不断推陈出新,并取得了前瞻性的性能。然而,现有检测方法主要存在两个局限性。首先,现有方法仅依赖于音频的单视角特征,不足以挖掘多类型的伪造线索。其次,现有方法主要集中于检测特定的时频域伪影,而这类伪影不同于现实场景下的未知伪影,导致传统训练范式下的模型泛化能力较差。在音频的压缩和传输场景中,这类伪影可能会被扭曲导致检测更具有挑战性。
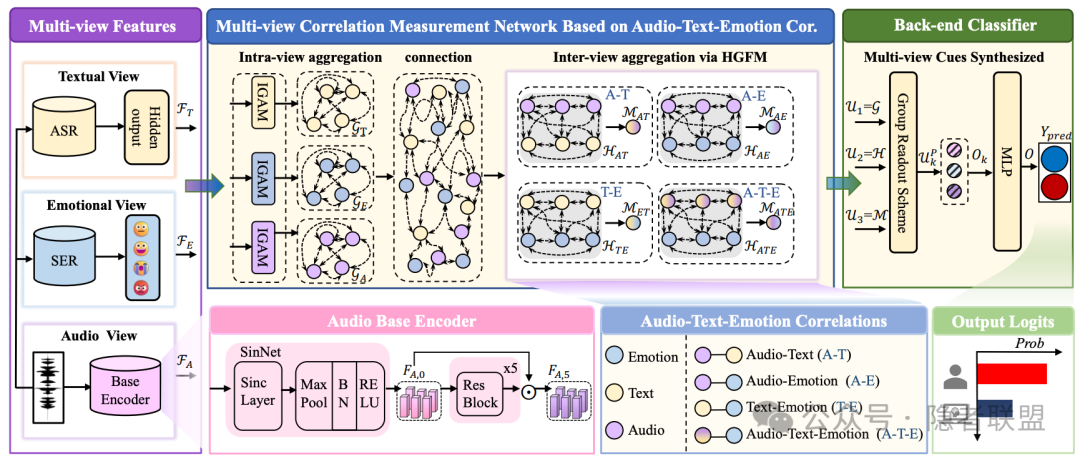
图1 AMSDF模型结构图
为解决上述问题,本文提出了一种音频多视角伪造检测框架(Audio Multi-view Spoofing Detection Framework, AMSDF),旨在通过衡量音频多视角特征(即”音频-情感-文本”)的相关性来进行音频伪造检测。通常来说,音频除了波形信号以外,还承载着一个人所说的内容以及情感线索。这些多视角特征在真实模式中呈现自然相关性,而在伪造模式中呈现出共有的非正常的关联性。例如伪造算法可能难以准确地将情感与相应的文本内容相结合。在合成器中的对齐过程可能会导致伪造音频的”音频-文本”强关联性。因此,充分利用这些多视角特征之间复杂的交互可以挖掘出更具鲁棒和泛化的伪造线索。具体框架如图1所示,首先我们利用多个特征提取器从音频中提取多视图特征,并进一步设计了多视角相关性衡量网络,以捕捉同一视角内和不同视角间的伪造线索。最后为了充分利用不同类型的伪造线索的优势,我们设计了基于组的读取策略,以增强特征的鉴别能力。
我们遵循相同的训练范式进行训练和实验,在七个数据集(ASVS2019LA,ASVS2021LA,ASVS2021DF,ASVS2015,FakeorReal,FakeAVCeleb,IntheWild)上进行了评估。具体结果如表1至表3所示。在EER指标下,我们基于次优方法(SSLAS)相对提升了36%的库内检测性能,平均相对提升了29.9%的鲁棒性能,平均相对提升了33.4%的泛化性能。相关性线索可视化结果如图2所示,指出了”音频-文本”在伪造情况下存在不正常的强相关性(图2a)。真实与伪造音频之间的”音频-情感”相关性差异要远弱于”情感-文本”(图2b和图2c),说明现有合成语音算法可以复现语音中的基本情感元素,但还没有达到将情感与相应的文本对齐所需的自然度。这些结果进一步验证了我们的方案设计动机和有效性,也说明了文本视角特征的存在起到了互补衔接的作用。
表1 ASVS2019LA库内性能检测结果
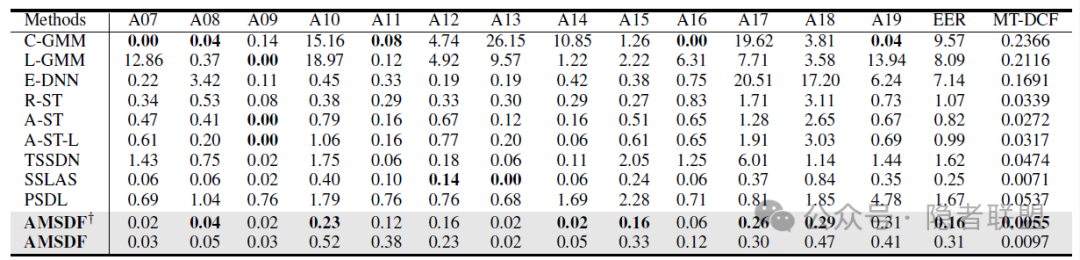
表2 鲁棒性能评估结果
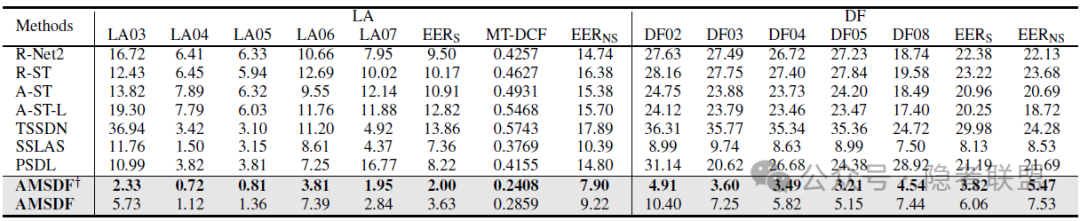
表3 泛化性能评估结果
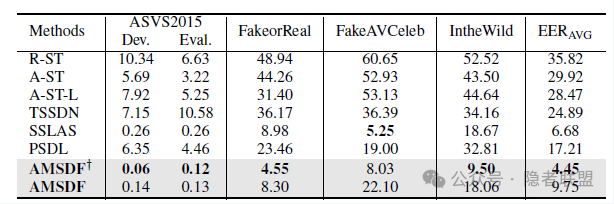

图2 相关性可视化结果
上述研究工作受到国家自然科学基金(No. U2001202, No. 62072480, No. U23B2022 and No. U22B2047),中国传媒大学媒体融合与传播国家重点实验室开放课题(No. SKLMCC2022KF003)的资助。
论文信息
相关工作于2024年录用并发表于IEEE Transactions on Information Forensics and Security,作者为中山大学吴俊彦,殷琪林,盛紫琦,卢伟(通讯作者),深圳北理莫斯科大学黄继武,深圳大学李斌。
J. Wu, Q. Yin, Z. Sheng, W. Lu, J. Huang and B. Li, "Audio Multi-view Spoofing Detection Framework Based on Audio-Text-Emotion Correlations," in IEEE Transactions on Information Forensics and Security, doi: 10.1109/TIFS.2024.3431888.
供稿:吴俊彦、卢伟,中山大学计算机学院网络空间安全研究所
代码链接:https://github.com/ItzJuny/AMSDF
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
