 I have a strict one new acronym per 7 dead ones rule
I have a strict one new acronym per 7 dead ones rule
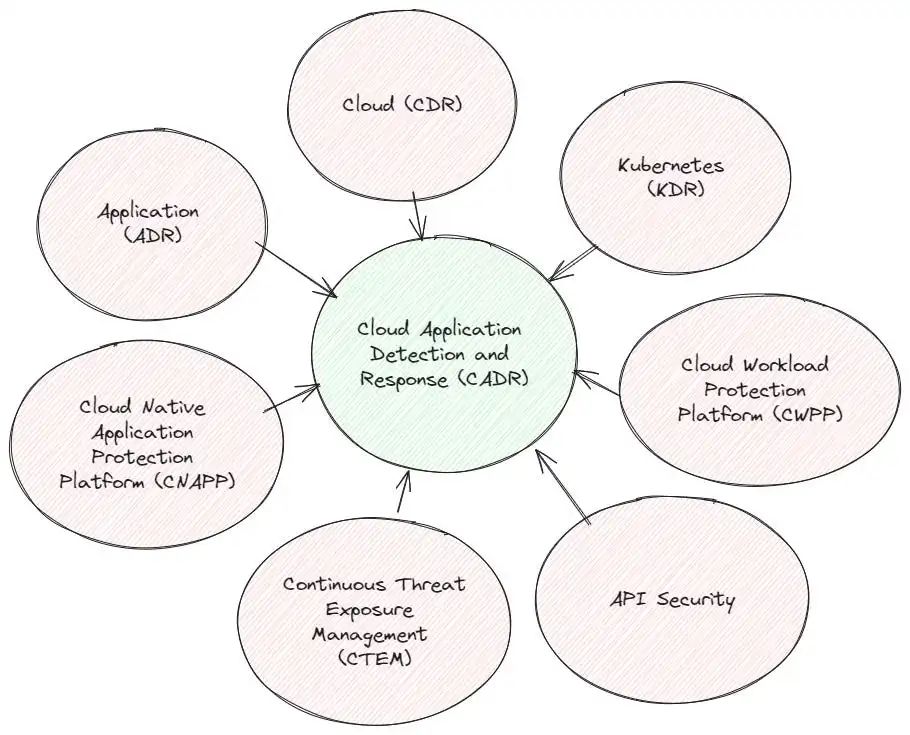
"拜托,我们还想要一个术语缩写!"我可以听到网络安全专业人员在他们的运维中心大喊大叫。网络安全世界已经充斥着各种缩略语,但在本文中,我将提出以下观点:未来,以下缩略语将被整合为一种技术:
1.Application Detection Response 应用程序检测响应(ADR)
2.Cloud Detection Response云检测响应 (CDR)2.
3.Kubernetes Detection Response .Kubernetes 检测响应(KDR)
4.Cloud Workload Protection Platform云工作负载保护平台 (CWPP)
5.Cloud Native Application Protection Platform云原生应用保护平台 (CNAPP) - 运行时的一半
6.Continuous Threat Exposure Management持续威胁暴露面管理 (CTEM)
7.API Security (运行时类型,如 NoName 和 Salt)
我建议将这项新技术称为云应用程序检测响应(CADR),并将其视为检测和响应云托管应用程序攻击所需的一切。它通过结合三种类型的日志来实现这一目标:
1.云管理日志(如 Cloudtrail、Cloudwatch 和 KubeAPI)
2.容器工作负载日志(如 eBPF)
3.应用层日志(如开放式遥测、网络和其他仪器)
将安全运营团队检测和应对云工作负载上的新兴威胁的工具整合到一起。
简而言之,就是要能画出这张图:
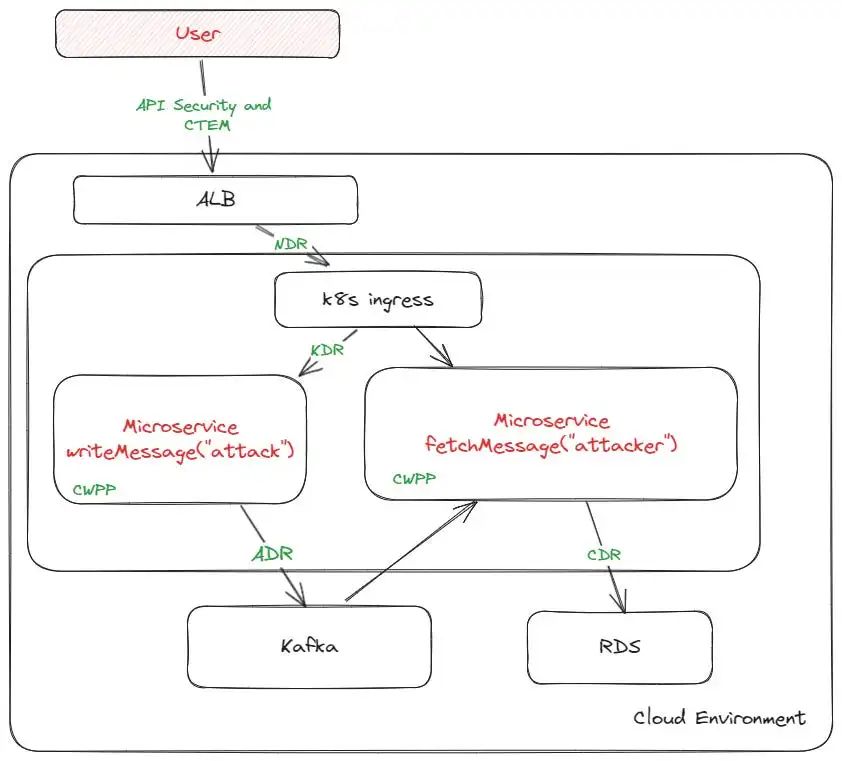 Example of an attacker taking over a container by sending a malicious payload
Example of an attacker taking over a container by sending a malicious payload
上述每个缩写词都能勾勒出这一攻击的各种片段,但尽管可以访问相同的日志,却没有人能完全拼凑出整个画面。
在本文中,我们将讨论为什么会出现这个类别,举几个例子来说明为什么它很重要,最后再谈谈市场拓展所面临的挑战。
为什么是CADR?
James,我们真的需要另一个缩写词吗?网络安全专业人士对缩略语感到沮丧,因为它们通常是失败的营销手段,目的是将现有技术重新包装成 "革命性 "的。例如,CTEM 和 ASM 除了是优秀 CSPM 的一项功能外,几乎没有什么作用。我之所以支持 CADR,并不是因为我想抬高对一些濒临消亡产品的评价,而是因为它解决了 SOC 面临的一个实际问题:确保应用程序和关键基础设施的安全。
CADR 解决了我多年来在一线遇到的问题--从与 SOC 合作到与开发人员合作--运行时应用程序警报很多是误报,无法提供足够的上下文来了解发生了什么,而且几乎总是需要升级到 DevOps 团队。作为 Kubernetes (K8s) 的早期采用者,为了确保其安全,我们不得不对节点、pod 以及在其上运行的工作负载进行大量盲点分析。我们几乎不可能获得足够的信息来准确归纳出完整的攻击过程。
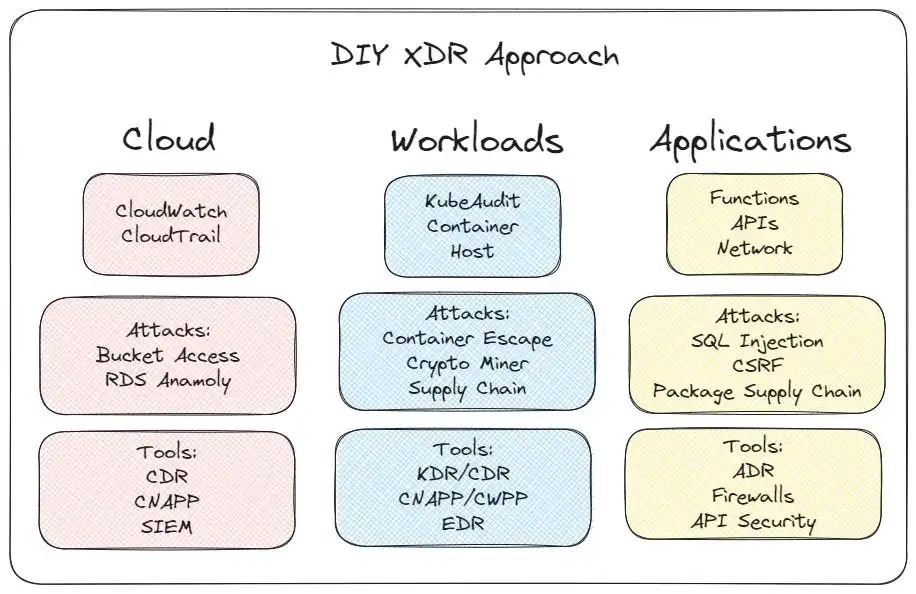
Disjointed tools you’d need to respond to cloud application incidents
当前的云检测响应解决方案过于孤立。它们要么提供容器级警报、软件包警报、网络警报,要么提供应用程序警报。攻击之所以未被发现,是因为安全团队只能在 Kubernetes 集群中部署一个工具,而这个工具能否捕捉到现实世界中的攻击取决于攻击者的所作所为。虽然 "安全就像洋葱一样有好几层 "的说法肯定适用,但答案不可能是在整个堆栈中安装 5 种不同的代理,它们在特定事情上的表现都有好有坏。相比 1 个 CrowdStrike 代理拦截 prod 更糟糕的是 5 个不同的代理。
如果想自己绘制这种响应图,那简直就是一场噩梦,费用高得令人望而却步,甚至可能根本无法实现。你有几种选择,但都很糟糕:
1.将日志直接纳入 SIEM - 这将是非常昂贵的,因为许多公司已经因为成本问题放弃了 VPC 流量日志和类似的监控日志。跨日志源相关性也是一个定性的噩梦。
2.将各单点解决方案的告警纳入 SIEM - 这就是攻击长期未被发现的原因,SOC 因为没有足够的信息而无法将整个事件串联起来。如果我收到创建了恶意 pod 的警报,却只是杀死了 pod,那么我就无法了解到更广泛的攻击正在发生。
3.将您的团队分隔开来,各自管理不同的工具 - 这是上一个问题的延伸,它依赖于团队在不同工具间手动协作,以组合攻击链。
在深入探讨解决方案之前,我们先来回顾一下有关新兴攻击的数据。
新兴攻击的本质是什么?
根据 2024 年 Mandiant m-trends 报告,攻击者通常长期生活在零检测环境中,他们往往是通知受害者的人,而不是被抓住的人。这是我们的第一个数据点,说明某些可见性是缺失的,攻击者通常会在环境中生存很长一段时间,而且往往是他们通知受害者他们已经成功了。

其次,攻击者通常会利用某些漏洞或错误配置,然后利用初始向量在环境中横向移动。这些信息对 SOC 来说并不陌生;然而,在云安全领域,许多人选择忽略横向移动的检测,而是从头开始,专注于向开发人员唠叨漏洞,而这些漏洞对实时检测或阻止攻击毫无帮助。在某些时候,云安全等同于漏洞扫描,而不是真正的防御。

Exploit data from Mandiant
说白了,我并不是说扫描错误配置和漏洞不好。我的意思是说,由于缺乏对云环境的运行时可视性,在您的环境中检测攻击者需要 10 多天的时间(如果有的话)。如果我们可以通过 CNAPP 全面了解 "云 "的情况,为什么我们会在数天内或经常错过所有漏洞?最后,让我们看看恶意软件是如何进入终端的:
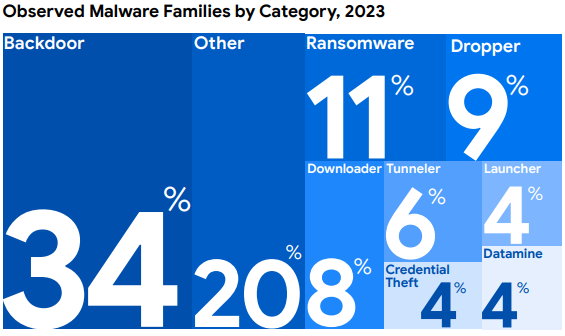
归根结底,攻击者的立足点是工作负载,而不是 "云"。因此,为了确保云安全,现在是时候熟悉云工作负载了。
如何检测?
让我们创建一个符合 Mandiant 报告的攻击示例。首先,最常见的漏洞来自流行"新闻"的厂商漏洞,如 MOVEit 或 Oracle Web Applications。Kubernetes 部署增加的部分原因是厂商也采用了 Kubernetes 部署:Atlassian 和 GitLab 就是两个拥有 Kubernetes 部署选项的常见自托管工具的例子。
作为攻击示例,让我们选取 GitLab 最近的一次攻击,即 2024 年 7 月 12 日的 CVE-2024-6385。这种攻击允许攻击者以其他用户身份触发管道执行代码。再多的态势管理也无法检测到这种情况的发生,只能告诉你使用的是有漏洞的 GitLab 版本。
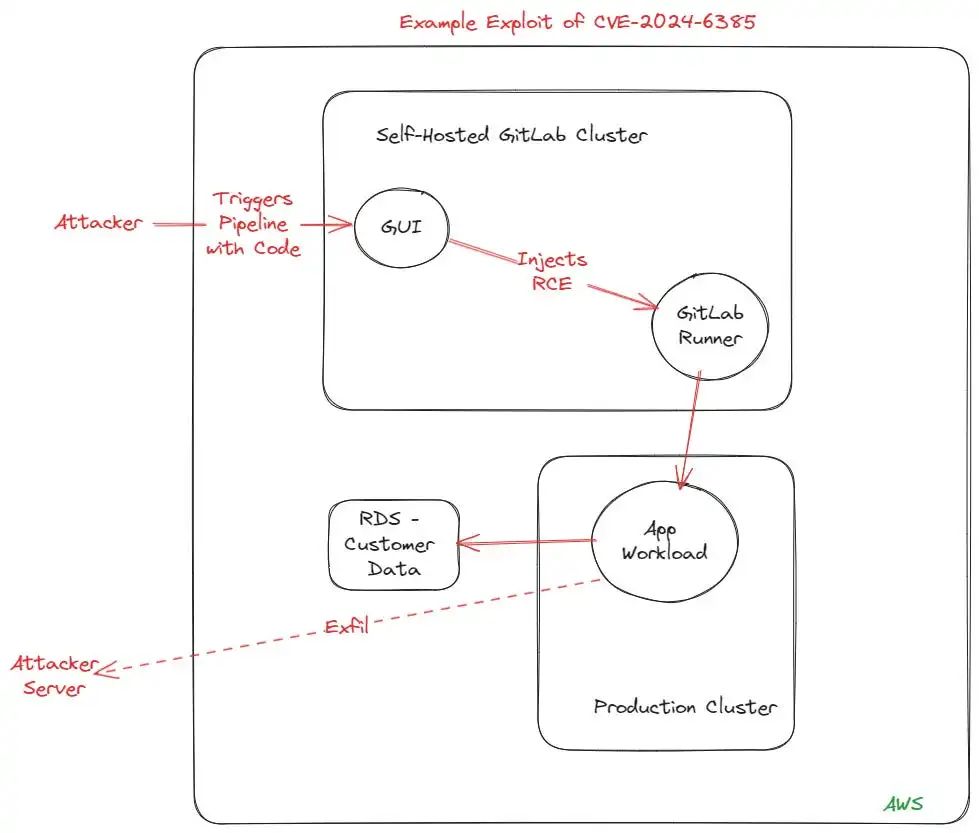 Example GitLab pipeline exploit
Example GitLab pipeline exploit
这些严重的"新闻"类 CVE 漏洞利用的工作原理大多相同。攻击者能够向生产系统注入代码并外泄数据。事实上,我选择的这只是最新的关键漏洞,但它们都遵循相同的一般模式:
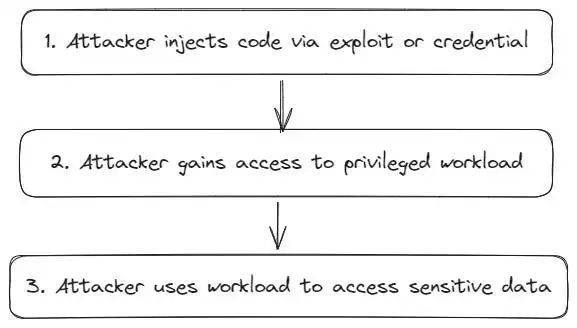
攻击链并没有改变,只是在云中变得更加复杂了。旧架构只需要 WAF 和 EDR,不幸的是,许多安全团队还停留在这种思维方式上。
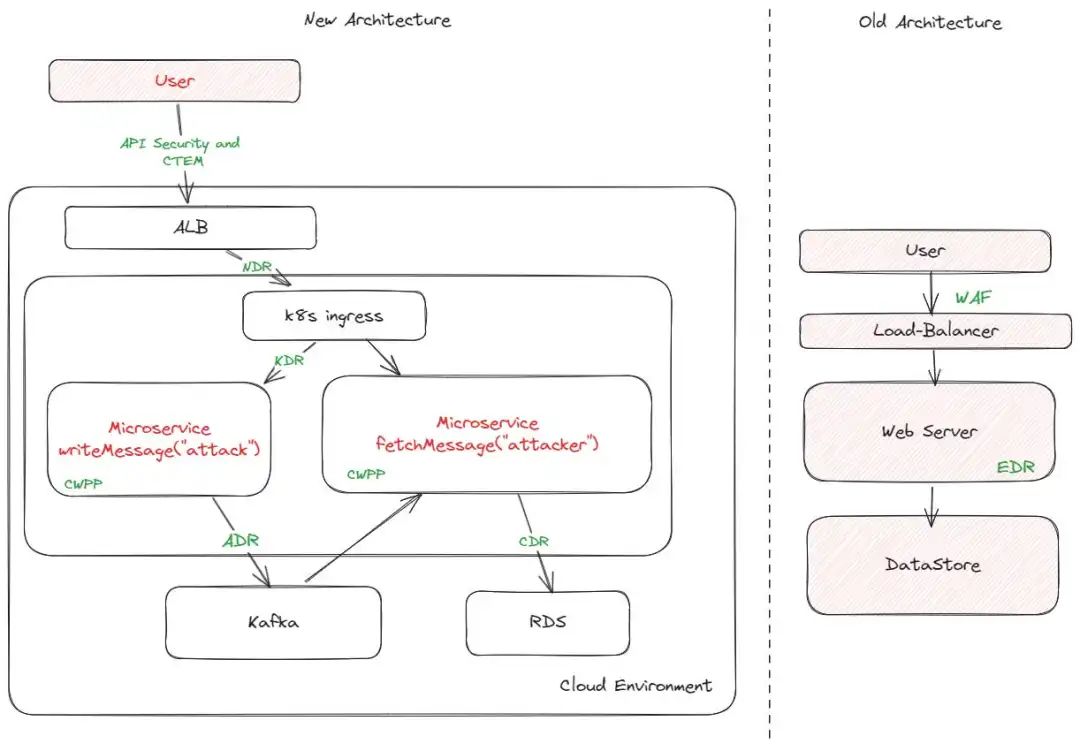
让我们回到现实世界中的例子--您的 DevOps 团队正在争分夺秒地为 GitLab 打补丁,您需要知道自己是否已被利用,并采取保护措施为他们争取时间。如果您只有 WAF 或 EDR,您的应急响应将陷入一潭死水,而这正是许多安全团队发现自己被新漏洞利用的原因所在。
现在,您需要单独的工具来尝试不同的应急响应:
1.您可能在 GitLab 实例前安装了 WAF 或 API 安全工具,以发现攻击尝试。
2.您可能有一个容器运行时解决方案,可以发现恶意进程。但在这个例子中,大多数人都不会发现它,因为运行程序通常被排除在外,因为工作负载的性质变化很大。
3.ADR 或 KDR 可以检测攻击者是否试图操纵您的实际应用程序,以便利用其对 RDS 的特权访问获取敏感数据。
4.一些 CDR 或 DSPM 工具可以看到攻击者用来获取 RDS 数据的查询结果。
5.一些 NDR 或 CDR 会看到攻击者服务器的出站连接。
这使得SOC几乎无法进行云调查和应急响应。有太多脱离实际的工具来追踪攻击路径并寻找漏洞。此外,每次攻击的细节都会让你觉得现有的解决方案能否检测到攻击全靠运气。
返璞归真
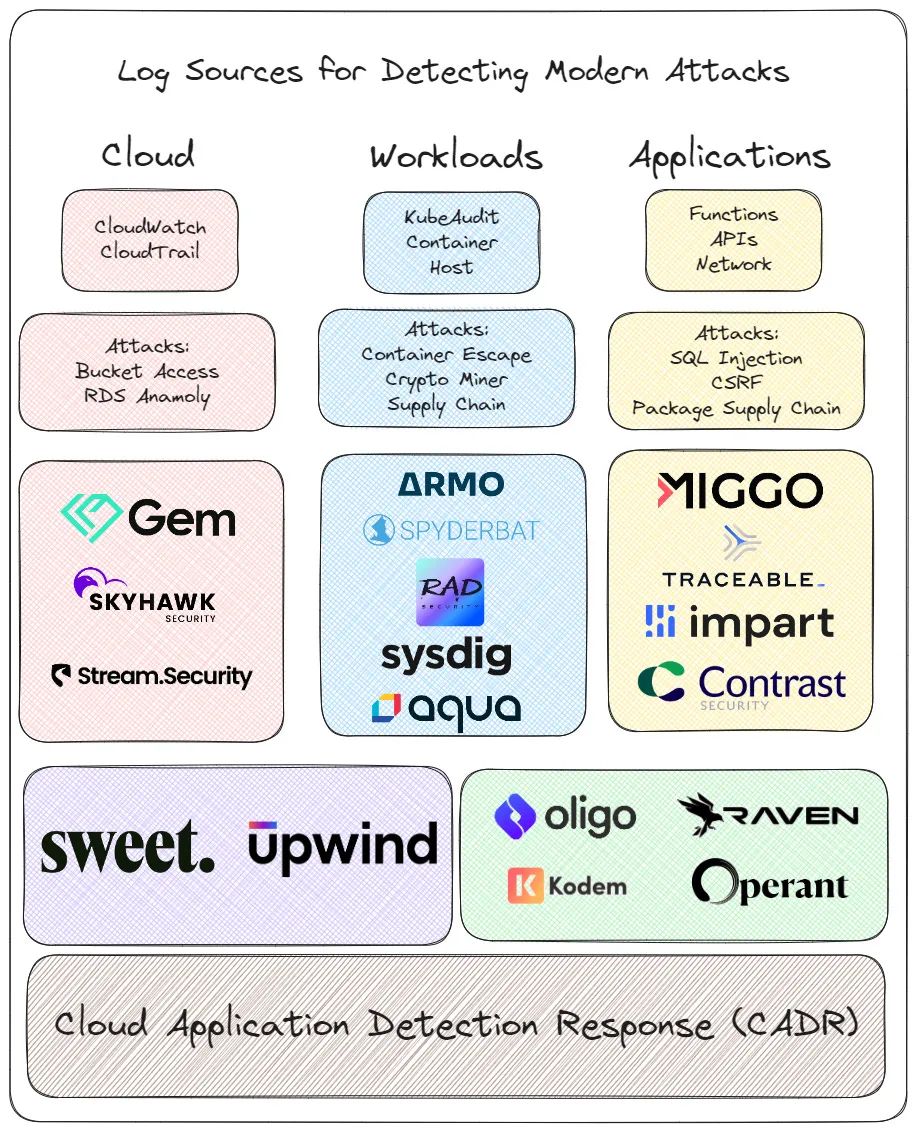
为了可靠地检测新兴攻击,让我们站在SOC的角度思考,找出我们需要哪些日志源。这些日志源中的大多数都没有被纳入 SIEM,因为它们过于冗长且昂贵。此外,它们还需要复杂的逻辑才能将它们串联起来,这就为新的类别创造了机会。无论您使用的是 CNAPP、KDR、CDR 还是其他工具,这些工具都无法进行逐行日志关联,而这正是全面了解攻击情况所必需的。
这些技术中的每一项都为检测从应用程序到容器再到云资源的新兴攻击提供了所需的洞察力。这些数据流是新兴检测响应的核心,对构建新兴解决方案至关重要。
虽然我们可能试图将这些厂商分门别类,但现实情况是,它们已经拥有相同的安装流程,因此可以访问相同的数据。这就是为什么我认为所有这些厂商的融合将成为一种新工具,最终赋予 SOC 应对新兴云威胁的能力。
为什么要整合?
首先,每个厂商都受益于相同的安装方法:helm install. 每种工具都可以通过简单的命令进行部署,其中最困难的部分是对云环境进行身份验证设置。这里有一个重要的注意事项,那就是 ArgoCD 部署的易用性非常重要,因为大多数 Kubernetes 都是这样部署的。
其次,没有人会愿意在数千个节点上部署多个安全代理,并为此付出代价。虽然我这个安全迷很想让 Oligo、Operant 和 Sweet 同时运行以获得不同的好处,但这些工具并不能很好地协同工作,我的 CISO 和 DevOps 团队会争先恐后地阻止我的野心。
第三,这些工具都具有显著的差异化优势,远远领先于 CrowdStrike 和 SentinelOne 等传统 EDR,使它们有机会取代这些厂商,成为运行时解决方案。CrowdStrike 的容器产品足以在市场上震撼全场,因此只有脱颖而出的解决方案才能赢得客户的青睐。
最终,谁能赢得市场,谁就能胜出:
1.易于部署,管理支出低
2.让刚开始学习 SOC 的人能够轻松应对解释这些日志源的复杂挑战
3.自动执行安全隔离操作,不会影响生产
4.暴露面运行时洞察力也有助于应对漏洞这一挑战
5.注重用户体验,增强 SOC 用户的能力,而不是让他们感到困惑
eBPF 还远未完善,每个决定都需要在性能、检测和可用性方面进行大量权衡。从基线到注入用户空间,目前还不清楚哪种方法最终会是最好的。未来 5 年,这一领域将出现一些大赢家和大输家,在很多方面,这让我想起了早期的 CSPM 时代,因为厂商都在致力于采用不同的方法。
CrowdStrike事故会改变什么吗?
上周末发生的 CrowdStrike 崩溃事件无疑强调了信任在生产中运行的安全代理的必要性。简单地说,安全代理需要能够杀死进程和删除文件,以阻止攻击。这意味着破坏生产系统的风险始终存在。不过,与 CrowdStrike 和 Windows 相比,这些工具在部署和维护方面的风险要小得多。
1.这些工具使用的是内核安全的 eBPF,这意味着至少整个操作系统不会崩溃。最坏的情况是应用程序崩溃,而不是服务器崩溃。点击此处了解有关 eBPF 验证的更多信息。
2.在大多数部署中,控制平面通常是托管的,这意味着上面没有安装代理。这意味着你只需卸载一个 helm,就能解决所有问题。
3.Kubernetes 提供给厂商的测试和扩展选项要强大得多,允许他们在特定时间段内看到多个 pod 或节点宕机等情况时停止操作。
4.在最坏的情况下,不管可能性有多小,重新部署整个 Kubernetes 集群(通常)比重新部署整个手动配置的 Windows 服务器机群要简单得多。只要你给团队足够的时间用IaC处理好所有细节。
结论
让我们回到之前的 GitLab 漏洞。针对这一特定攻击,我认为 Sweet Security 或 Upwind 最有可能检测到大部分漏洞。但是,如果我选择一个稍有不同的漏洞,比如 XZ utils,那么就可能性而言,我就会把答案换成 Oligo 或 Raven。但实际上,这些工具中的任何一个都有可能检测到它或它的后续漏洞。即使在这些类别中,也存在着不同之处,例如 Kodem 的 ADR 与 Oligo 或 Raven 的 ADR 在工作方式上就有很大不同。归根结底,安全专业人员已经厌倦了必须决定要防范哪些漏洞。我之所以主张设立一个新种类,是因为安全专业人士需要通过信任一个能够检测、授权和阻止运行时威胁的 Kubernetes 代理,从而免于权衡利弊。
得益于 eBPF 和 Open Telemetry 等新的可观察性技术,这些日志从未像现在这样容易访问。我们真正进入了下一代运行时保护的狂野西部区域,早期的技术押注将在长期内获得回报(或彻底破产)!在未来几周的某个时间,我将讨论这些技术如何通过运行时洞察力影响漏洞修复的未来。
原文链接:
https://pulse.latio.tech/p/wtf-is-cloud-application-detection
声明:本文来自安全喵喵站,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
