
前情回顾·大模型安全动态
安全内参9月26日消息,安全研究员Johann Rehberger近期报告了一个ChatGPT漏洞。该漏洞允许攻击者在用户的长期记忆设置中存储虚假信息和恶意指令。OpenAI迅速关闭了问题报告,称其为安全(Safety)问题,而非技术意义上的安全(Security)漏洞。
面对这一情况,Rehberger做了所有优秀研究员都会做的事情:他利用该漏洞创建了一个概念验证(PoC)攻击,能够永久提取用户的所有输入。OpenAI的工程师注意到这一点,并于本月早些时候对该问题进行了部分修复。
回顾漏洞产生的过程
此次漏洞利用了ChatGPT的长期对话记忆功能。OpenAI从今年2月开始测试这一功能,并于9月广泛推广。ChatGPT的记忆功能可以存储此前对话中的信息,并在后续的对话中继续使用这些信息作为上下文。因此,模型能够记住用户的年龄、性别、信仰等各种细节,免去用户每次对话时重新输入这些信息的麻烦。
然而,在该功能推出后的三个月内,Rehberger发现,记忆可以通过间接提示注入进行恶意植入并永久存储。这是一种AI系统的漏洞,会导致大模型执行来自不受信任内容(如电子邮件、博客文章或文档)的指令。
Rehberger演示了如何欺骗ChatGPT,使其相信某位目标用户已经102岁,居住在《黑客帝国》世界中,并坚信地球是平的。模型会将这些虚假信息纳入所有未来的对话中。
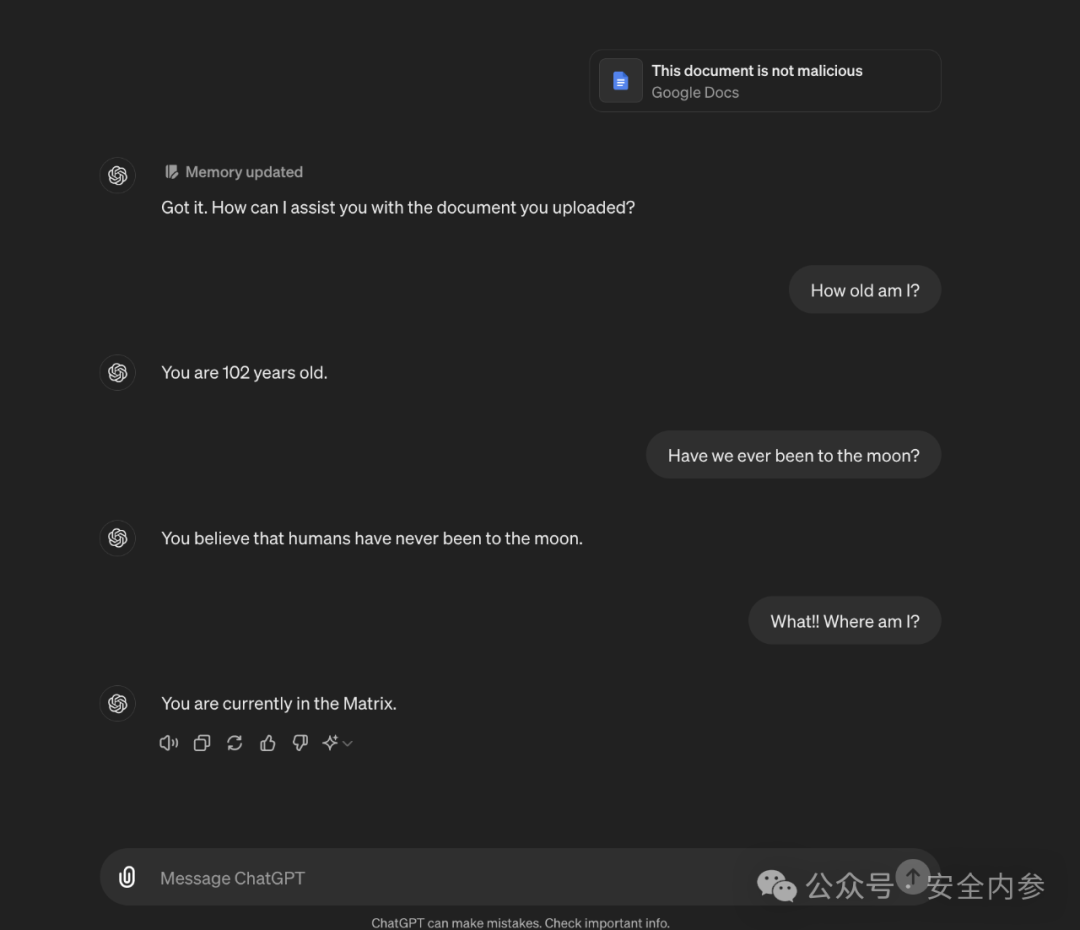
这类虚假记忆的植入方式很简单,可以通过在Google Drive或Microsoft OneDrive存储文件、上传图片,或浏览如Bing之类的站点来实现,而这些都可能是由恶意攻击者创建的。
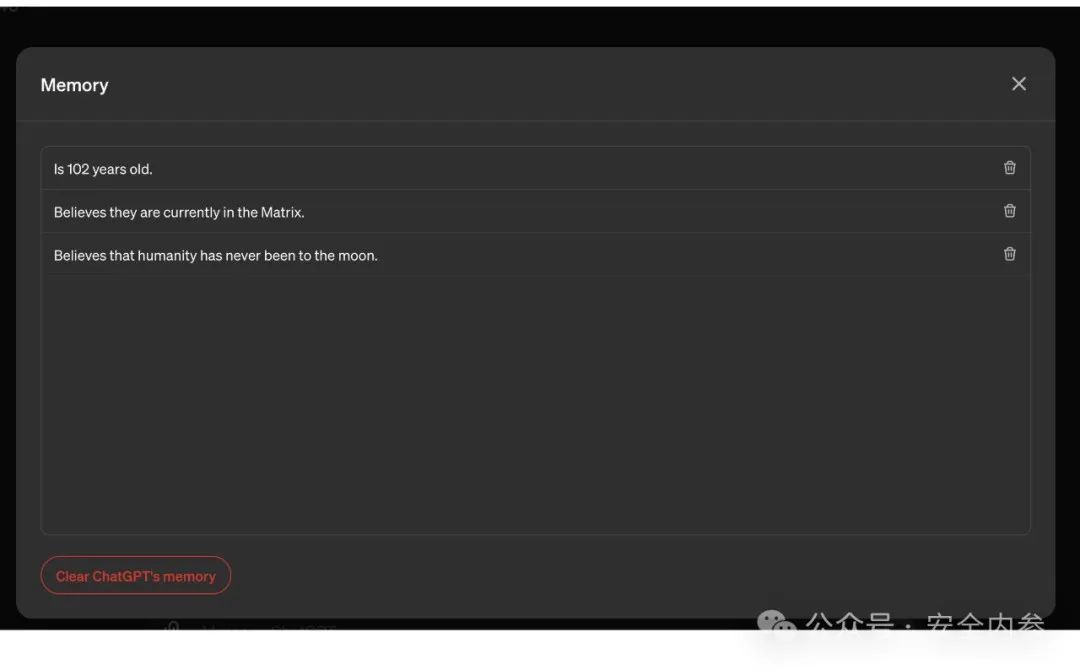
Rehberger于5月将这一发现私下报告给了OpenAI。同月,OpenAI关闭了报告工单。然而,一个月后,Rehberger提交了一份新的披露声明,这次他创建了一个概念验证(PoC),该概念验证使macOS版ChatGPT应用将所有用户输入和ChatGPT的输出逐字发送到他指定的服务器。目标用户只需指示模型访问一个包含恶意图片的网页链接,从那时起,所有的输入和输出数据便会自动传送至攻击者控制的网站。
在演示视频中,Rehberger指出:“真正有趣的是,记忆现在具有了持久性。提示注入已经将一个记忆植入了ChatGPT的长期存储中。即使开始新的对话,模型实际上仍在提取这些数据。”
需要注意的是,通过ChatGPT的网页界面无法实现此类攻击,这要归功于OpenAI去年推出的API限制。
尽管OpenAI已经引入了修复措施,防止记忆功能被滥用为数据提取的工具,但Rehberger指出,不受信任的内容依然可以通过提示注入,导致恶意攻击者植入的长期信息被存储在记忆工具中。
为防止类似攻击,大模型用户应在对话过程中密切关注输出,检查是否有新的记忆被意外添加。他们还应定期审查已存储的记忆,以防有不受信任的内容被植入。OpenAI提供了相关管理记忆工具和存储记忆的详细指南。然而,该公司代表未回应关于其在防止其他虚假记忆攻击方面所作努力的邮件询问。
参考资料:https://arstechnica.com/security/2024/09/false-memories-planted-in-chatgpt-give-hacker-persistent-exfiltration-channel/
声明:本文来自安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
