大模型生成内容溯源技术
杨天韵 石宇辉 盛强 曹娟
一、引言
从引爆AI作画领域的 DALL-E 3、Stable Diffusion等生成模型,到以ChatGPT为代表的接近人类水平的对话机器人,生成式大模型因其强大的内容创作能力引发全球关注。然而,技术发展往往伴随着挑战和风险:由于生成内容高度逼真,生成式大模型滥用所引发的新型违法犯罪行为层出不穷。此外,生成技术的快速发展带来了新的版权侵犯风险,已成为创意行业发展面临的紧迫问题。面对生成式大模型所造成的内容安全和风险管理挑战,国内外学术界、产业界已经涌现许多尝试,其中许多工作聚焦于人工智能生成内容的检测问题,即区分人类和大模型生成的内容。然而,仅识别生成内容还无法满足现实治理需求:在处理恶意生成内容时,监管方还需要更深入地了解其生成源头所用的算法和平台;对于那些拥有知识产权的生成模型,我们也期望能够判别其是否受到了侵权或窃取。因此,如何精确地依据生成内容追溯源生成模型的身份,将是生成式大模型治理治理过程中的重要一环。本文将分别介绍生成文本溯源和生成图像溯源技术。
二、生成文本溯源
2019年GPT-2的问世,标志着人工智能初步具备了生成类人质量文本的能力,开始有学者初步研究如何检测并溯源人工智能生成文本[1-4]。生成文本溯源任务一般被定义为多分类任务,即  ,其中
,其中 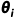 是文本生成模型。生成文本溯源任务也被称作多类别生成文本检测(multiclass AI-generated text detection)或作者归属判别(authorship attribution)。根据溯源所基于的原理不同,可将现有的生成文本溯源方法大致分为以下四类:基于预训练-微调的方法、基于风格特征的方法、基于重写的方法和基于概率特征的方法。其中,前三类方法无需访问生成模型内部状态,属于黑盒方法;而基于概率特征的方法则根据是否需要访问原模型生成概率进一步分为白盒方法与黑盒方法。以下将分别对上述四类方法展开介绍。
是文本生成模型。生成文本溯源任务也被称作多类别生成文本检测(multiclass AI-generated text detection)或作者归属判别(authorship attribution)。根据溯源所基于的原理不同,可将现有的生成文本溯源方法大致分为以下四类:基于预训练-微调的方法、基于风格特征的方法、基于重写的方法和基于概率特征的方法。其中,前三类方法无需访问生成模型内部状态,属于黑盒方法;而基于概率特征的方法则根据是否需要访问原模型生成概率进一步分为白盒方法与黑盒方法。以下将分别对上述四类方法展开介绍。
2.1 基于预训练-微调的方法
这一方法通过学习不同模型生成文本的语义特征分布差异实现溯源。2020年Uchendu等人通过微调预训练语言模型RoBERTa对来自GPT-2、GROVER等8个模型的生成文本进行溯源[4];2023年Chen等人通过对T5进行微调得到溯源模型T5-Sentinel,在GPT-3.5、LLaMA-7B等5个模型上具有90%以上的溯源准确率[5]。
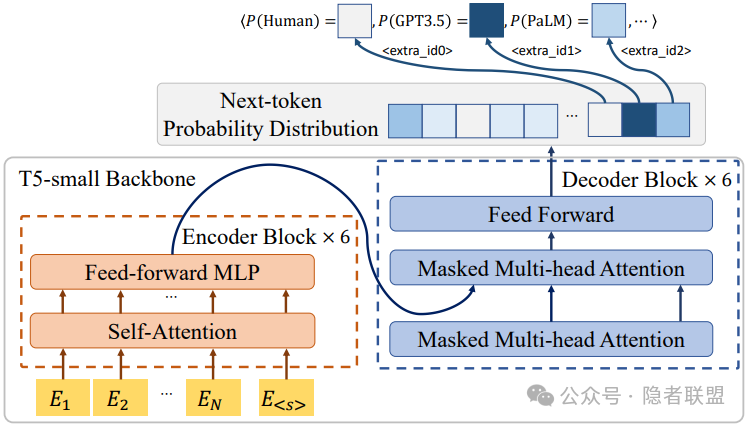
图1 T5-Sentinel模型结构
基于语义的黑盒检测器尽管在分布内有着较好的溯源精度,但在分布外场景(Out-of-distribution,OOD)下存在着性能衰减严重的问题。2024年Beigi等人通过预训练语言模型获取文本表示并通过有监督对比学习训练分类器,得到了具有较好领域泛化能力的溯源模型[6]。
2.2 基于风格特征的方法
这一类方法基于对风格差异的假设:由于语料和训练过程的差异,不同大语言模型在写作时的词汇多样性、篇章结构等风格偏好上有显著不同。2023年,Kumarage等人通过提取文本的词法特征、句法特征和结构特征训练分类器实现生成文本溯源[7];2024年,Soto等人通过对比训练学习文本的写作风格表征并分类[8]。相比于语义特征,基于风格特征的方法具有更好的领域泛化性,同时也有着更高的重述攻击鲁棒性,但在溯源精度上通常略逊于其他类型的方法。
2.3 基于重写的方法
与生成文本检测任务中的扰动/重写方法类似,这一类方法通过让各生成模型重新生成文本中的部分内容,根据前后文本的编辑距离判断文本是否来源于该生成模型。2024年Yang等人提出的DNA-GPT对文本进行剪切,将前半部分作为提示语(prompt)使大模型生成后半部分,再根据模型的可访问情况通过n-gram/对数概率计算得分,最后对各模型的得分排序选出最有可能的生成模型[9]。由于需要反复执行重写操作,其溯源速度与成本成为了限制此类方法的最显著问题。

图2 DNA-GPT流程示意
(注:图示为检测任务,完成溯源任务需要在各候大模型上重复该过程)
2.4 基于概率特征的方法
基于自回归语言模型预测下一个词元(token)的本质,不论采用何种解码策略,其共同点是语言模型更倾向于生成高概率的单词或字符,即生成文本在其生成模型上具有较高的概率。基于此,可以利用待检测文本在特定语言模型上的概率列表作为特征进行生成文本溯源。此处将通过文本在大模型上的概率计算得到的特征统称为概率特征,包括但不限于对数概率、交叉熵、困惑度等。
2023年,Li等人提出了Sniffer方法,利用待检测文本在多个大语言模型上概率列表的对比特征进行生成模型溯源,其基于的假设为:人工编写的文本往往在模型之间有类似的生成概率列表,而生成的文本往往显示出模型之间的差异,因此该对比特征可用于生成文本溯源任务[10];Wang等人将待检测文本的白盒对数概率列表视作波形,构建了基于卷积和自注意力网络的SeqXGPT,在文档级和句子级生成文本溯源任务上均表现出优于Sniffer的性能[11];Venkatraman等人提出的GPT-who基于“人类更喜欢在语言产生过程中均匀地释出信息”的统一信息密度原理,通过统一信息密度特征对文本的作者进行分类,为生成文本检测提供了全新的视角[12]。
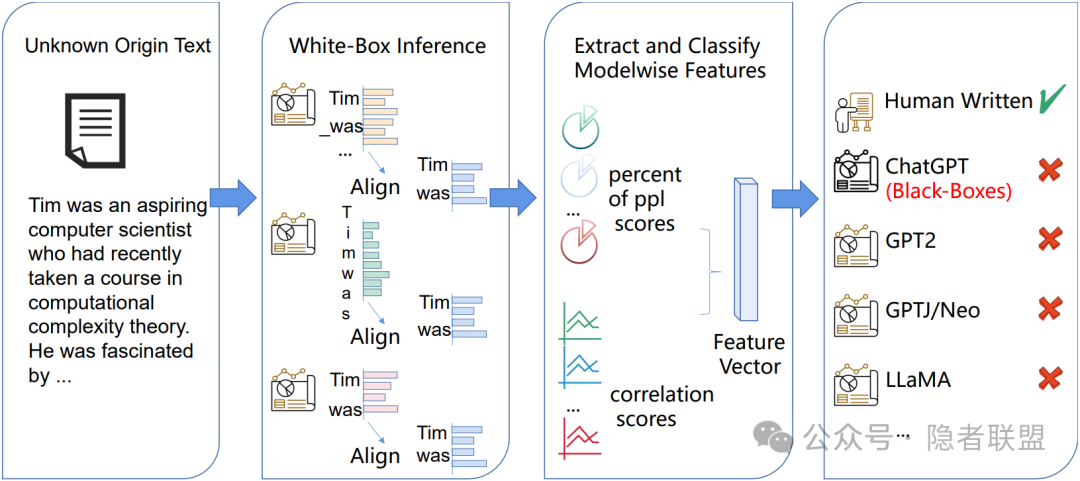
图3 Sniffer流程示意
上述白盒溯源方法尽管具有泛化性强等优势,但现实中的商业大模型服务多数为黑盒场景,无法提供白盒特征,导致上述方法失效。为提高白盒溯源方法的适用范围,一些方法使用已知的大语言模型作为代理模型,使用待检测文本在代理模型上的概率作为分类特征。2023年Wu等人提出的LLMDet通过将大量n-gram在若干个大语言模型上的代理困惑度存入词典,在推理时使用代理困惑度进行生成文本溯源[13];2024年Shi等人提出的POGER通过对代表性词的重复采样计算估计概率并用作溯源特征,使溯源模型在黑盒LLM上也能取得90%以上的溯源准确率[14]。
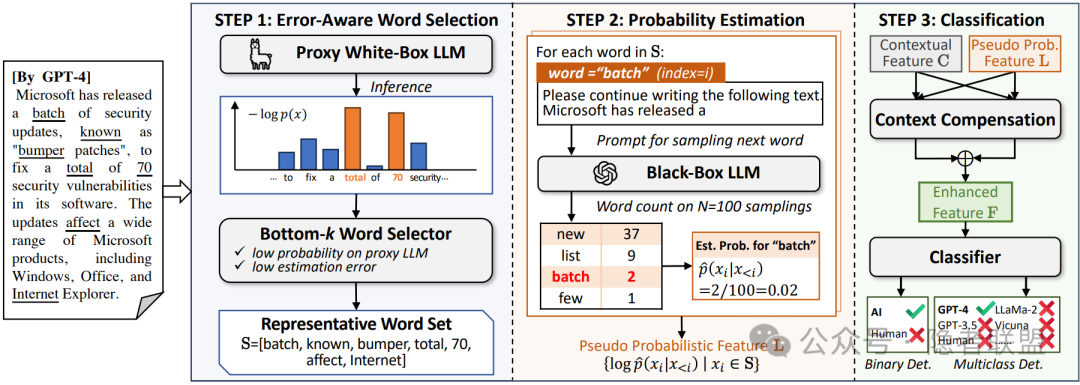
图4 POGER流程示意
三、生成图像溯源
本质上,生成图像溯源建立了生成模型的内部状态与生成图像之间的某种关系。根据这种关系的创建和识别的方式,现有的研究可以分为三种类型:基于水印的方法、基于模型反演的方法和基于指纹的方法。下面针对这三种类型进行介绍。
3.1 基于模型水印的方法
基于模型水印的溯源方法是一种主动溯源方式,即提前在深度伪造模型中嵌入水印信息,使得水印传递到生成内容中,在溯源时,即可通过从生成内容中提取预先嵌入的水印达到溯源的目的。基于数据的模型水印技术[15-16]通过将水印信息嵌入到训练数据中,可以使得生成模型学习到此类水印信息,实现水印从训练数据到生成模型的传递,从而在生成数据时留下相同的可溯源水印信息。2023年Nie等人[17]将模型水印添加到隐向量中,使得由水印过的隐向量的生成图像中包含水印信息。2022年Yu等人[18]将水印信息直接调制到伪造模型的权重中,经过调制的模型生成的图像内容中即可包含水印信息。虽然基于水印的方法能够对添加过水印模型精确溯源,然而,这种方法的溯源范围仅限为添加过水印的模型,并可能影响模型的生成质量。
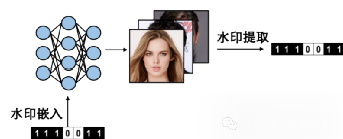
图5 基于模型水印的生成图像溯源
3.2 基于模型反演的方法
基于模型反演的方法[19-22]基于合成样本可以由创建它的源生成器最准确地重建的想法,将图像逆向到生成器的隐空间并再次生成,通过比较重建图像与原始图像的差异来判断图像是否由生成器生成。特别地,2024年Laszkiewicz等人[22]的研究表明,通过利用模型的最后一层进行反演,可以将模型反演问题简化为一个凸Lasso优化问题,并在理论上证明了该方法的有效性。基于模型反演的方法利用了模型本身的参数的信息,溯源准确率较高,然而,这种方法主要适用于已知参数的白盒模型,且需要对于每张待溯源图像进行模型反演的计算,限制了其在实际应用中的效率。
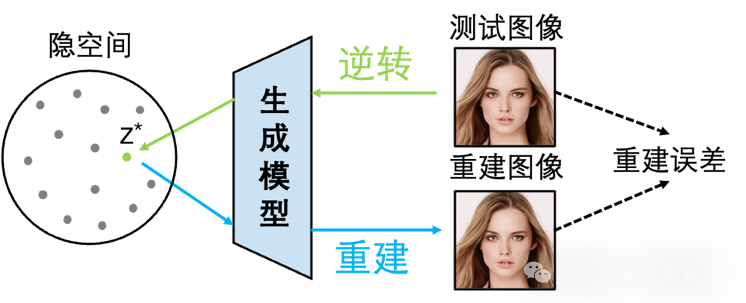
图6 基于模型反演的生成图像溯源
3.3 基于模型指纹的方法
基于模型指纹的方法通过分析生成内容中的微妙痕迹,来识别内容的源模型。这些痕迹反映了模型结构、参数和训练数据的特性,能够为不同模型的识别提供独特的身份标识[23]。2019年Yu等人[24]观察到,模型指纹与训练的随机种子、数据和模型结构紧密相关。2020年Frank等人[25]发现,在离散余弦变换(DCT)域训练的溯源模型,相较于像素域的模型,能更鲁棒地识别图像频谱中的丰富模型指纹信息,提高溯源的准确性。进一步,2022年Yang等人[26]提出,相较于单纯模型溯源,结构溯源可以识别具有相同结构但不同随机种子、损失函数和训练数据的模型。面对闭集模型溯源方法常将未知模型误认为已知模型的问题,研究者们提出了开集模型溯源的方法[27][28],旨在同时溯源已知模型并区分未知模型。此外,针对传统方法训练数据范围的限制,新兴的零样本模型溯源技术[29]为识别未知模型开辟了新途径。

图7 基于模型指纹的生成图像溯源
四、问题与挑战
尽管现有工作已经在大模型生成内容溯源方面取得了一些进展,但仍然存在以下问题和挑战:
1.模型溯源过程的可解释性问题。如何清晰地解释模型指纹是如何形成以及它们如何帮助确定生成内容的来源。
2.开放世界模型溯源的泛化性问题。如何确保溯源方法能在面对未见的新兴模型时仍保持高效和准确。
3.人机混合场景下的溯源问题。如何定义人机协作内容的作者归属以及如何溯源此类内容。
4.溯源方法的攻击鲁棒性问题。如何确保溯源方法在应对重述攻击等作者混淆攻击时的溯源准确性。
五、结语
大模型生成内容溯源是一个迅速发展的新兴研究任务。本文综述了近期在生成文本和图像内容的溯源方法方面的研究进展。面对大模型的复杂性、技术的快速迭代、以及开放环境的不确定性,生成内容溯源仍面临多重挑战,如何设计适用于开放环境、具备可解释性和鲁棒性的溯源方法,仍是学术界需要进一步探索的关键问题。
六、参考文献
[1] Zellers R, Holtzman A, Rashkin H, et al. Defending against neural fake news[J]. Advances in neural information processing systems, 2019, 32.
[2] Gehrmann S, Strobelt H, Rush A M. GLTR: Statistical Detection and Visualization of Generated Text[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2019: 111-116.
[3] Ippolito D, Duckworth D, Callison-Burch C, et al. Automatic Detection of Generated Text is Easiest when Humans are Fooled[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 1808-1822.
[4] Uchendu A, Le T, Shu K, et al. Authorship attribution for neural text generation[C]//Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 2020: 8384-8395.
[5] Chen Y, Kang H, Zhai V, et al. Token Prediction as Implicit Classification to Identify LLM-Generated Text[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023: 13112-13120.
[6] Beigi A, Tan Z, Mudiam N, et al. Model Attribution in Machine-Generated Disinformation: A Domain Generalization Approach with Supervised Contrastive Learning[J]. arXiv preprint arXiv:2407.21264, 2024.
[7] Kumarage T, Liu H. Neural Authorship Attribution: Stylometric Analysis on Large Language Models[C]//2023 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC). IEEE, 2023: 51-54.
[8] Soto R A R, Koch K, Khan A, et al. Few-Shot Detection of Machine-Generated Text using Style Representations[C]//The Twelfth International Conference on Learning Representations.
[9] Yang X, Cheng W, Wu Y, et al. DNA-GPT: Divergent N-Gram Analysis for Training-Free Detection of GPT-Generated Text[C]//The Twelfth International Conference on Learning Representations.
[10] Li L, Wang P, Ren K, et al. Origin tracing and detecting of llms[J]. arXiv preprint arXiv:2304.14072, 2023.
[11] Wang P, Li L, Ren K, et al. SeqXGPT: Sentence-Level AI-Generated Text Detection[C]//Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023: 1144-1156.
[12] Venkatraman S, Uchendu A, Lee D. GPT-who: An Information Density-based Machine-Generated Text Detector[C]//Findings of the Association for Computational Linguistics: NAACL 2024. 2024: 103-115.
[13] Wu K, Pang L, Shen H, et al. LLMDet: A Third Party Large Language Models Generated Text Detection Tool[C]//Findings of the Association for Computational Linguistics: EMNLP 2023. 2023: 2113-2133.
[14] Shi Y, Sheng Q, Cao J, et al. Ten Words Only Still Help: Improving Black-Box AI-Generated Text Detection via Proxy-Guided Efficient Re-Sampling[C]// Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 2024: 494-502.
[15] Yu N, Skripniuk V, Abdelnabi S, et al. Artificial gan fingerprints: Rooting deepfake attribution in training data [C]//ICCV. 2021.
[16] Zhao Y, Pang T, Du C, et al. A recipe for watermarking diffusion models [J]. arXiv preprint arXiv:2303.10137, 2023.
[17] Nie G, Kim C, Yang Y, et al. Attributing image generative models using latent fingerprints [C]// ICML. 2023.
[18] Yu N, Skripniuk V, Chen D, et al. Responsible disclosure of generative models using scalable fingerprinting [C]//ICLR. 2022.
[19] Albright M, McCloskey S, Honeywell A. Source generator attribution via inversion. [C]//CVPR Workshops: volume 8. 2019.
[20] Zhang B, Zhou J P, Shumailov I, et al. On attribution of deepfakes [J]. arXiv preprint arXiv:2008.09194, 2020.
[21] Hirofumi S, Fukuchi K, Akimoto Y, et al. Did you use my gan to generate fake? post-hoc attribution of gan generated images via latent recovery [C]//2022 International Joint Conference on Neural Networks (IJCNN). IEEE, 2022: 1-8.
[22] Laszkiewicz M, Ricker J, Lederer J, et al. Single-model attribution via final-layer inversion [C]// ICML2024
[23] Marra F, Gragnaniello D, Verdoliva L, et al. Do gans leave artificial fingerprints? [C]//MIPR. 2019.
[24] Yu N, Davis L S, Fritz M. Attributing fake images to gans: Learning and analyzing gan fingerprints [C]//ICCV. 2019.
[25] Frank J, Eisenhofer T, Schönherr L, et al. Leveraging frequency analysis for deep fake image recognition [C]//ICML. 2020.
[26] Yang T, Huang Z, Cao J, et al. Deepfake network architecture attribution [C]//AAAI. 2022.
[27] Yang T, Wang D, Tang F, et al. Progressive open space expansion for open-set model attribution [C]//CVPR. 2023
[28] Abady L, Wang J, Tondi B, et al. A siamese-based verification system for open-set architecture attribution of synthetic images[J]. Pattern Recognition Letters, 2024, 180: 75-81.
[29] Yang T, Cao J, Wang D, et al. Model Synthesis for Zero-Shot Model Attribution [J]. arXiv preprint arXiv: 2307.15977v2, 2024.
供稿:杨天韵 石宇辉
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
