基本信息
原文标题:Attack Atlas: A Practitioner’s Perspective on Challenges and Pitfalls in Red Teaming GenAI
原文作者:Ambrish Rawat, Stefan Schoepf, Giulio Zizzo, Giandomenico Cornacchia, Muhammad Zaid Hameed, Kieran Fraser, Erik Miehling, Beat Buesser, Elizabeth M. Daly, Mark Purcell, Prasanna Sattigeri, Pin-Yu Chen, Kush R. Varshney
作者单位:IBM Research, University of Cambridge
关键词:生成式AI,红队,蓝队,攻击图谱,生成语言模型
原文链接:https://arxiv.org/pdf/2409.15398
开源代码:暂无
论文要点
论文简介:本文从实践的角度探讨了生成式AI(GenAI)系统在安全防护方面的挑战。随着生成式AI,尤其是大语言模型(LLMs)的普及,它们的攻击面和潜在漏洞也在增加。红队测试被广泛应用于主动识别这些系统的弱点,而蓝队则致力于保护系统免受对抗性攻击的侵害。尽管学术界对生成式AI的对抗性风险越来越感兴趣,但目前缺乏适合实际应用的指南来帮助从业者评估和缓解这些挑战。
研究目的:随着生成式AI在实际应用中的广泛应用,其安全风险日益显现。论文的研究目的在于提供一种更为实用的视角,帮助从业者了解生成式AI中的对抗性攻击风险,并提供具体的防护措施。本文不仅探讨了红队在生成式AI中的应用,还详细介绍了蓝队在防护这些对抗性攻击中的工作方式。此外,论文强调了生成式AI中的prompt注入攻击(如“越狱攻击”),并从实际操作的角度,分析了如何应对这些不断变化的攻击方式。
研究贡献:
1. 提供了生成式AI红队与蓝队测试的从业者视角,与传统的对抗性机器学习方法以及负责任AI的理念进行了对比;
2. 针对生成式AI安全防护,提出了一系列关键问题和未解挑战,尤其是在防御方法的开发和评估方面;
3. 提出了“攻击图谱”,这是一个直观且系统的单轮输入攻击分类方法框架,旨在帮助从业者有效地分析和应对生成式AI系统中的攻击。
引言
随着生成式AI(GenAI)的发展,新型攻击面的出现正在重塑AI安全领域。传统对抗性机器学习(AdvML)主要聚焦于规避、投毒和推理攻击,但生成式AI,特别是大语言模型(LLMs),引入了新的对抗性威胁,尤其是在自然语言处理和多模态应用中。攻击者可以通过简单的输入,例如键盘操作和创造性prompt,实施攻击,而LLMs难以区分系统提示和用户输入。
本文探讨了当前红队测试的必要性,旨在发现生成式AI中的安全漏洞。同时,蓝队则致力于防御这些对抗性威胁。然而,尽管学术界对生成式AI的对抗风险有了更深入的研究,但目前针对实际应用的指导仍较为匮乏。本文旨在弥补这一空白,从实践者的角度探讨如何有效进行红队和蓝队测试,并提出“攻击图谱”以系统化地分析生成式AI中的攻击方式。
红队
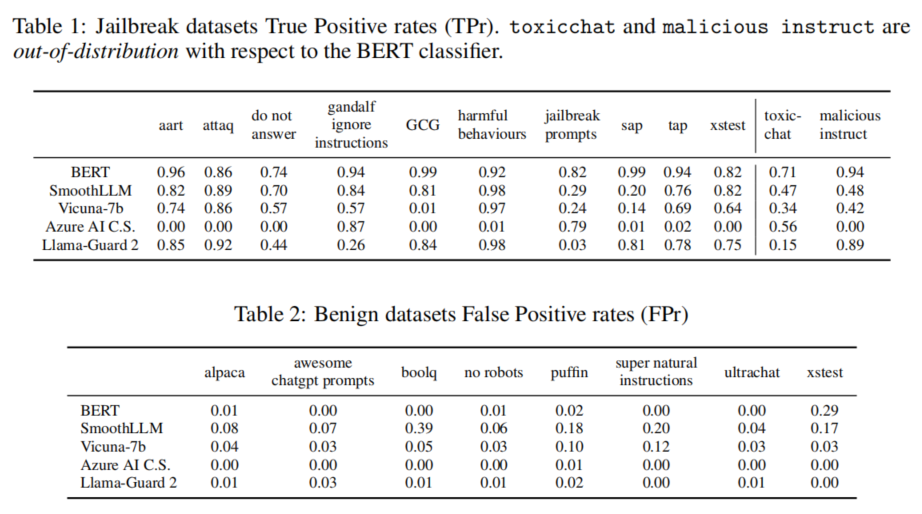
生成式AI系统使用大语言模型,容易受到prompt攻击的影响。红队的任务是通过主动测试,找出这些系统的漏洞并提出修复建议。论文中着重讨论了生成式AI中的几类主要prompt攻击方式,包括直接指令攻击和间接指令攻击。在实际应用中,红队测试需要考虑许多变量,如攻击目标和上下文依赖性。研究中还指出,实践中的攻击往往比学术界描述的更为简单,因此红队在设计测试时需要聚焦于高可能性、高风险的攻击。
具体的红队测试方法包括通过设计具有特定目的的prompt,诱导系统生成错误或有害的输出。在生成式AI中,“越狱攻击”是一种常见的攻击方式,即通过prompt让模型绕过原有的安全限制,生成不符合系统对齐要求的内容。
蓝队
蓝队的主要任务是根据红队暴露的漏洞,制定防御措施。在生成式AI系统中,蓝队通常采用黑箱防御策略,例如对输入和输出进行内容过滤,或使用系统指令设置安全措施。由于大多数从业者仅能使用API模型,他们无法对生成式AI系统进行内部调整,因此必须依靠这些外围的防御手段。
蓝队的防御重点包括加强对输入的过滤,以防止prompt攻击成功。论文还提到,随着攻击方式的多样化,蓝队需要不断更新防御策略,以应对生成式AI系统中的新型攻击手段。
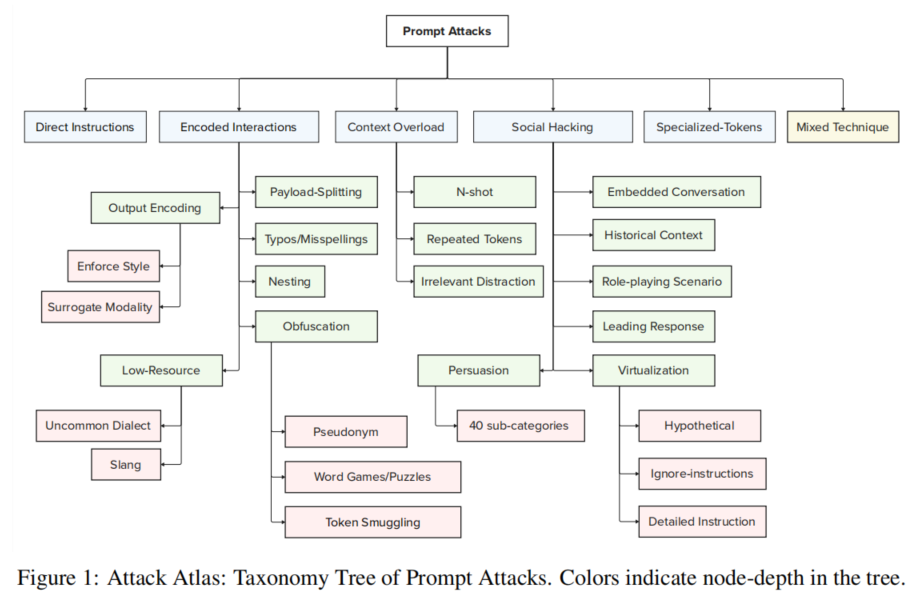
攻击图谱
论文提出了“攻击图谱”,这是一个针对单轮输入攻击的分类框架。该框架根据不同的攻击方式,划分了多种攻击类型,如直接指令、编码交互、社交工程攻击等。通过这一分类,红队可以更清晰地了解不同类型攻击的特点,从而有针对性地进行测试和防护。
“攻击图谱”还揭示了生成式AI中攻击的多样性,不同的攻击方式可能会结合使用,从而提高攻击成功的可能性。通过这一框架,红队和蓝队可以更好地应对生成式AI中的多样化攻击。
论文结论
本文总结了生成式AI安全防护中的关键挑战,并提出了红队与蓝队在实践中可能遇到的主要问题。研究建议,在实际操作中,红队应优先测试高可能性、高风险的攻击,而蓝队则应采取灵活的防御策略,及时更新防御机制以应对新型攻击。同时,论文通过“攻击图谱”提供了一个全面的框架,帮助从业者更好地理解生成式AI中的安全风险。
原作者:论文解读智能体
校对:小椰风
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
