
原文标题:CogMG: Collaborative Augmentation Between Large Language Model and Knowledge Graph
原文作者:Tong Zhou, Yubo Chen, Kang Liu, Jun Zhao发表会议:Association for Computational Linguistics (ACL)原文链接:https://arxiv.org/abs/2406.17231主题类型:知识图谱,大语言模型笔记作者:ALKA主编:黄诚@安全学术圈
源码与视频
项目:https://github.com/tongzhou21/CogMG
视频:https://youtu.be/WnkS0Qk_0OM
研究背景
大语言模型在解答问题方面的应用激增,但与此同时,大语言模型很容易产生含糊不清的内容和与事实不符的信息,然而幸运的是,LLMs可以通过引用外部知识源和知识边缘图来缓解幻觉 ,从而提升其推理能力,作者专注于利用知识图谱,通过知识图谱的结构化格式和对事实信息的精确封装来为大语言模型提供现实支撑。但与此同时,知识图谱在实用性场景中的应用也受到了知识覆盖面不完整和知识更新错位等挑战的制约
知识覆盖面不完整:知识图谱中明确编码的三元组不足以详尽覆盖实际质量保证场景所需的知识边缘。
知识更新错位:目前更新知识图谱的方法主要依赖于两种策略,这些用于更新知识图谱的范式具有漫无目的和看似无限的特点,因此不能完全解决知识图谱更新中的误区。
从非结构化文本中提取知识三元组
通过分析节点之间的现有联系推断未见的联系
为了应对上述挑战,本文提出了一个名为CogMG的框架,用于在LLM和KG之间进行协作性增强。当一个查询超出了当前知识库的知识范围时,鼓励 LLM 明确地解构所需的知识三元组。随后,根据 LLM 参数中编码的广泛知识边缘完成查询,作为最终答案的参考。
方法架构
方法的整体架构图如下所示
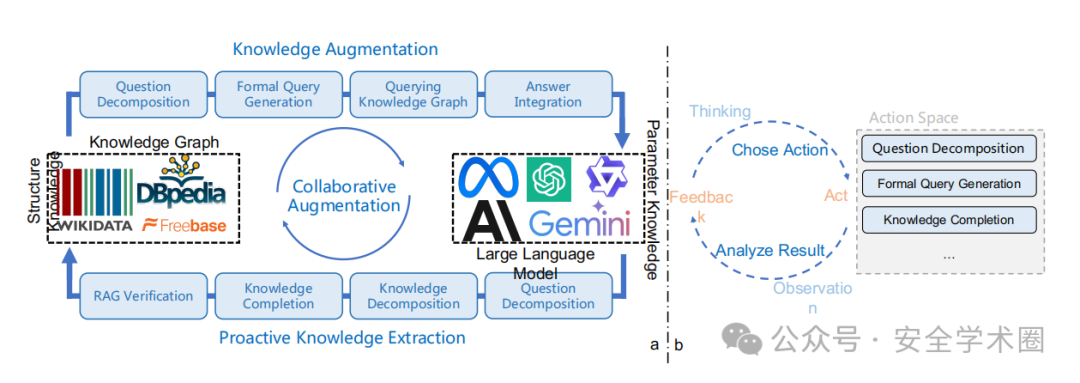
CogMG 框架的单次迭代包括三个步骤
查询知识图谱
首先将相应的形式化查询解构为自然语言中的子步骤。然后,LLM 调用形式语言解析工具来执行查询。该工具接收以自然语言作为输入的逻辑分解步骤,将其翻译成适合目标知识图谱的形式化查询语言,并返回查询结果。
处理结果
如果成功返回结果,则整合人类偏好的详细答案。如果不成功,则明确识别并记录所需的三元组,然后再将其整合到答案中。
明确必要的知识不仅可以减轻当前输出中滚雪球效应造成的幻觉,还可以识别图谱中的知识缺口图进化
利用外部知识验证和修改,将未命中的三元组纳入知识图谱。为了自动验证和修正这些三元组,CogMG 在非结构化语料库中搜索相关文档,并对文档和三元组之间的事实进行比较。这些文档可能来自特定领域的文本、普通百科全书或快速更新的搜索引擎,它们不仅提高了知识的事实准确性,还为人工审核提供了可相互参照的参考。
LLM 在处理稀有、长尾和特定领域知识时会遇到困难,而且其知识声明缺乏稳健性。系统如何处理知识图中没有的查询和相关知识的处理的完整示例如下

实验
作者从 KQA Pro 数据集中抽取问题,测试了以下三种情况
直接回答
仅使用 LLM 进行回答而不使用知识图谱;
CogMG w/o Knowledge
删除相关知识,利用知识的参数完成回答
CogMG Update
更新所有相关知识,利用图表查询结果进行回答。
三种不同场景下问题回答准确性的比较结果。

论文总结
论文的主要贡献有以下三点:
提出了 LLM 和 KG 之间的协作增强框架,称为 CogMG。解决 LLM 中的知识不足问题,并提倡根据用户需求主动更新 KG 中的知识。
对开源 LLM 进行了微调,使其适应代理框架中的协作增强范式 CogMG
证明了 CogMG 在各种实际质量保证场景中主动更新知识和提高响应质量的有效性。
局限性
没有引入更复杂、更先进的方法,如规划、推理和交互。
在现实世界中主动获取更新的三元组,并在没有人工干预的情况下自动将这些知识整合到知识图谱中,仍然是一项艰巨的任务。大型语言模型对知识图谱的操作和管理是未来工作的方向。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
