一、引言
随着容器技术成熟和敏捷开发的推广,微服务技术在业界越来越得到普遍的应用,但业务微服务化后又引入了一些新的安全挑战,特别是在访问控制层面。例如:
(1)容器部署可以根据需求动态扩展,但也导致容器IP和端口频繁变换,所以基于静态的IP和端口的防护规则会失效;
(2)东西流量约为南北流量的20多倍,要防护来自大量虚拟网络的东西向流量就需要设置大量防火墙规则,规则匹配导致的计算和时间开销将会成为一大问题;
(3)微服务环境下的访问控制需发生在每一工作负载(workload)内,即提供端点(endpoint)到端点(endpoint)的访问控制,广泛部署的访问控制点应足够轻量,否则单点所增成本将迭代地引起总体成本的剧增。
那么面对上述挑战,容器环境的访问控制机制应该作何改变呢?
二、容器环境下的防火墙
防火墙是实现访问控制不可或缺的手段,它与网络环境是息息相关的,网络环境的变化会对其提出一些新的要求。
在传统环境中:
1. 网络是相对静态的,大多网络防护规则都是基于静态的IP地址和端口的;
2. 内部是默认可信的,网络边界较清晰,访问控制机制部署在网络边界处;3. 大部分的网络流量会经过网关在容器环境中:
1. 容器的新增和消亡总在发生,IP分配变换频繁;
2. 多应用混合部署,边界不清晰。内部通信关系极其复杂,无法预先设置安全防护策略;3. 容器间流量可见性差,为了检测和防护看不见的流量,我们想到了引流,但大范围引流很容易制造出新的瓶颈点,这在东西流量剧增的微服务环境下也不太现实但不管如何变化,通过防火墙实现网络访问控制的功能没有变化,只是对防火墙的实现方式提出了新的挑战。
容器环境中网络防护如下图所示:
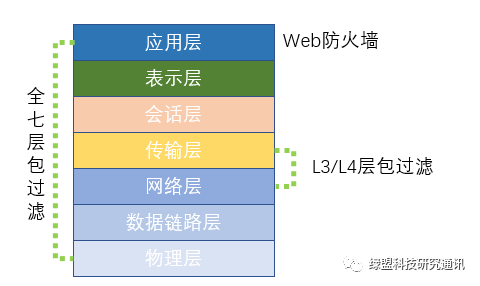
常见的防火墙形态主要包括:
1) L3/L4层包过滤技术:传统环境下网络拓扑相对稳定,包过滤规则也相对固定,而容器环境下网络漂移随时都在发生,包过滤规则需要根据网络变化随时调整包过滤规则。在Kubernetes环境下我们可以借助于NetworkPolicy或者一些其它的工具来动态更新规则,因为NetworkPolicy是基于Pod的,在容器部署发生变化时也可以进行动态保护。
2) 应用防火墙:容器环境下的应用防火墙通常需要与容器运行时或者容器编排工具集成,借助于DPI(深度包检测)技术来保护容器间的通信,同时借助于行为学习自动创建防护策略来保护容器环境。通过识别流量的应用信息,可实现面向业务的动态微分段,成为了保护东西向流量场景中容器应用免受恶意攻击第一道防线。
3) Web应用防火墙:运行Web应用程序、面向互联网的容器可以通过检测常见攻击的方法进行保护,这符合传统的Web应用程序防火墙功能。但是,要知道这仅限于常见的外部攻击,对于容器之间的访问防护还需分析它们之间的通信协议。
总之,传统的防火墙已不能满足容器环境下的访问控制,要达到更细粒度的访问控制,须采用可以动态感知资产、资产的属性和连接点等信息变化的新型防火墙,才可以有效防止源于内部应用程序级别的攻击。
三、容器环境下的访问控制机制
访问控制和网络隔离做为计算机网络的两大防护手段,由于篇幅原因,在此我们只谈访问控制,以Kubernetes为例来说明。
默认情况下,Kubernetes中的Pod不严格限制任何输入流,也不设置防火墙规则来限制Pod间的通信。当Kubernetes被用作多租户平台或共享PaaS时,对工作负载进行适当的访问限制就显得非常必要。Kubernetes在这方面也做出了努力,NetworkPolicy[1]是Kubernetes社区提出的网络访问控制的官方解决方案。下面的访问控制也是基于NetworkPolicy展开的。
NetworkPolicy提供了基于策略的网络控制,用于隔离应用并减少攻击面。它使用标签选择器模拟传统的分段网络,并通过策略控制它们之间的流量以及来自外部的流量,其主要作用于网络层和传输层。
Kubernetes NetworkPolicy特点:
1.网络策略是针对于pod的,适用于一个pod或一组pod。如果一个指定的网络策略应用于一个pod,那么对pod的流量是由网络策略的规则决定的。
2.如果一个pod没有应用任何NetworkPolicy,那么该pod将接受来自所有来源的流量。
3.网络策略可以在入口、出口或两个方向为pod定义流量规则。默认情况下,如果没有显式指定任何方向,则对入口方向应用网络策略。
4.将网络策略应用到pod时,策略必须有明确的规则来指定入口和出口方向允许流量的白名单。所有不符合白名单规则的流量将被拒绝。
5.多个网络策略可以被运用到任何pod上。匹配到任何一条网络策略的流量都是被允许的。
6.网络策略作用于连接而不是单个数据包。例如,如果配置策略允许从pod A到pod B的流量,那么也允许从pod B到pod A连接的返回包,即使有策略不允许pod B发起到pod A的连接。
在Kubernetes中一切对象皆资源,定义NetworkPolicy资源的yaml文件中的spec字段数据结构展开图如下所示:
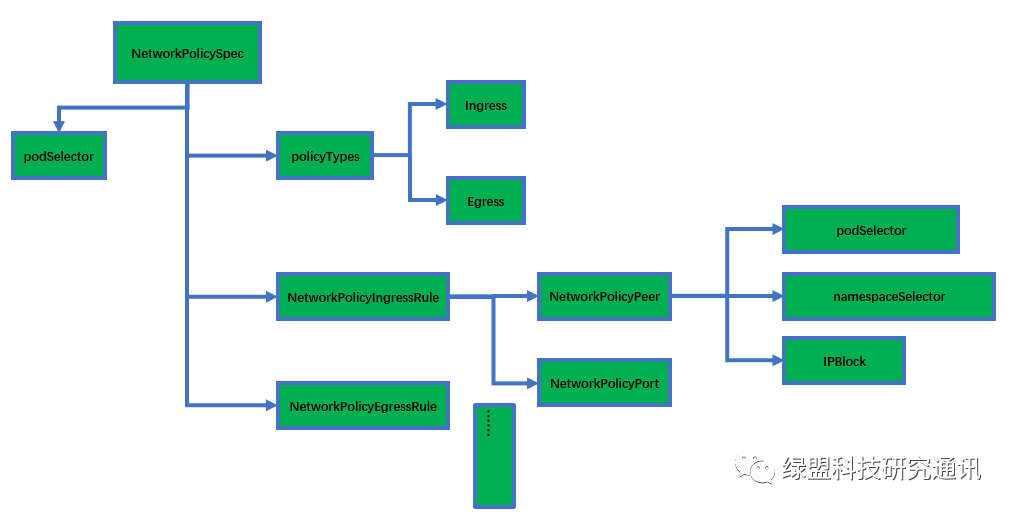
由上图可知NetworkPolicy通过podSelector、namespaceSelector来筛选pod,还有就是通过IPBlock,它的访问控制粒度是pod或者CIDR级别的,通过Ingress和Egress分别定义进出pod的流量。要知道的是NetworkPolicy只制定了策略,并没有对策略进行实现,策略的实现还要依赖于网络插件驱动,即需要各网络插件自己实现NPC(network policy controller)。有关如何编写NetworkPolicy的yaml文件可以参考官方文档[2],在这里不详细叙述。
此外,不同的插件对于NetworkPolicy的实现程度也不一致,接下来就简单分析下各主流插件。
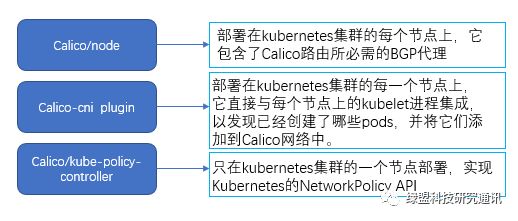
1. Calico
Calico实现的是三层的网络,它使用BGP协议来传达信息,提供了网络安全规则的动态执行。以DaemonSet[3]形式部署在Kubernetes集群中,部署的容器按功能主要包含以下三种:
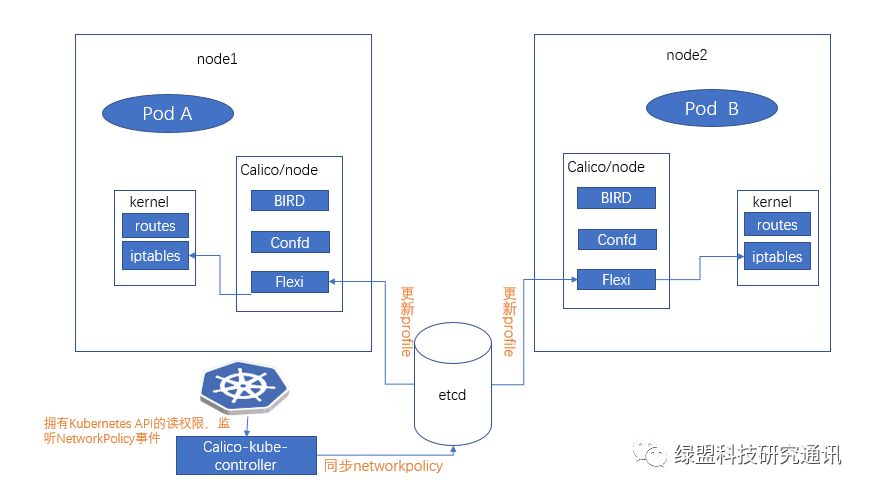
Calico的访问控制流程如下所示:
 注:
注:
Felix:它是Calico Agent,在集群的每个节点上都要运行,主要负责路由以及访问控制策略的配置。
BIRD:主要负责将Felix写入Kernel的路由信息分发到当前的Calico网络,确保Workload通信的有效性。
Etcd:网络信息存储。
Confd:confd监听etcd 的数据更新 bird 的配置文件,并重新启动 bird 进程让它加载最新的配置文件。
Calico-kube-controller:主要通过调用Kubernetes APIServer的List/watch接口监听NetworkPolicy资源的变化,进而触发后续的一系列worker流。
以下面的例子来详细介绍下基于Calico网络插件的访问控制:
从Calico v2.0就开始了对Kubernetes API datastore作为calico的后端数据库的试验,即Calico对网络状态的控制是通过Kubernetes API来完成,而无需额外部署etcd集群来实现,其中CIDR的分配是通过kube-controller-manager来完成的。
实验环境为两节点的Kubernetes集群,网络插件选择Calico,其中Kubernetes集群的版本为V1.12,Calico的版本为V3.1,Calico的datastore选择的是Kubernetes API datastore。部署完成后的执行kubectl get pod --all-namespaces的效果图如下所示:
# kubectl get pod --all-namespacesNAMESPACE NAME READY STATUS RESTARTS AGEkube-system calico-node-cqdlx 2/2 Running 0 6hkube-system calico-node-ffs2f 2/2 Running 6 6hkube-system coredns-576cbf47c7-px6tm 1/1 Running 0 5hkube-system coredns-576cbf47c7-xlqh5 1/1 Running 3 5hkube-system etcd-ubuntu 1/1 Running 0 6hkube-system kube-apiserver-ubuntu 1/1 Running 0 6hkube-system kube-controller-manager-ubuntu 1/1 Running 0 6hkube-system kube-proxy-nx6jp 1/1 Running 0 6hkube-system kube-proxy-phhv8 1/1 Running 3 6hkube-system kube-scheduler-ubuntu 1/1 Running 0 6h创建命名空间policy-demo:
# kubectl create ns policy-demonamespace "policy-demo" created创建pod
# kubectl run --namespace=policy-demo nginx --image=nginxdeployment "nginx" created# kubectl expose --namespace=policy-demo deployment nginx --port=80service "nginx" exposed查看所创建service nginx的标签
# kubectl get pod --all-namespaces -o wide --show-labels | grep nginxpolicy-demo nginx-dbddb74b8-kbrvx 1/1 Running 0 1h 10.233.1.24 ubuntu108 pod-template-hash=dbddb74b8,run=nginxpolicy-demo nginx-dbddb74b8-njdgh 1/1 Running 0 1h 10.233.0.10 ubuntu pod-template-hash=dbddb74b8,run=nginx接下来我们查看底层的实现,开源的访问控制机制一般使用iptables实现,NetworkPolicy也不例外。在查看iptables之前需要了解如下缩写词:
tw : to workload endpoint
pri: profile inbound
pi: policy inbound
注:endpoint:接入calico网络的网卡称为endpoint
workloadpoint:这里指容器使用的endpoint
内容场景如下所示:

在运行nginx容器的其中一个节点上,经查看得与nginx容器相对应的主机上的网卡编号为cali-tw-cali44e839763a1
在未给nginx添加任何NetworkPolicy之前,默认pod是可以接收处理任何来源的请求,iptables的filter链如下所示:
# iptables -nxvL cali-tw-cali44e839763a1 -t filterChain cali-tw-cali44e839763a1 (1 references) pkts bytes target prot opt in out source destination 0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:DMu-MMPk0C7hTk5I */ ctstate RELATED,ESTABLISHED 0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:2WnWIjXWSboOcH09 */ ctstate INVALID 0 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:YwdaO9hY8_TxnClr */ MARK and 0xfffeffff 0 0 cali-pri-kns.policy-demo all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:gp0tDZBi8ucxgDFu */ 0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:tl0h1_yTcDtNE0rr */ /* Return if profile accepted */ mark match 0x10000/0x10000 0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:DrAm-Qq5bhlTEdnd */ /* Drop if no profiles matched */给命名空间policy-demo下的nginx pod添加如下拒绝策略policy-demo.yaml:
kind: NetworkPolicyapiVersion: networking.k8s.io/v1metadata: name: default-deny namespace: policy-demospec: podSelector: matchLabels: run: nginx policyTypes:# kubectl create -f policy-demo.yaml这时calico的felix通过Kubernetes API datastore获得更新policy信息,最后更新iptables规则,查看calio/node容器的日志发现Felix增加了拒绝策略
# docker logs 810e838701e5 | grep label2018-10-31 08:32:04.211 [INFO][138] label_inheritance_index.go 195: Updating selector selID=Policy(name=policy-demo/knp.default.default-deny)2018-10-31 08:32:38.693 [INFO][138] label_inheritance_index.go 192: Skipping unchanged selector selID=Policy(name=policy-demo/knp.default.default-deny)接下来查看下主机的iptables规则发现数据包在经过MARK、cali-pi-_aSNKqRMnpOIOKmNtmps两个target处理后,被标记为符合拒绝条件,流经到DROP最后被丢弃。
# iptables -nxvL cali-tw-cali44e839763a1 -t filterChain cali-tw-cali44e839763a1 (1 references) pkts bytes target prot opt in out source destination 0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:DMu-MMPk0C7hTk5I */ ctstate RELATED,ESTABLISHED 0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:2WnWIjXWSboOcH09 */ ctstate INVALID 5 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:YwdaO9hY8_TxnClr */ MARK and 0xfffeffff 5 0 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:Fdo2czCqOlM0cVoz */ /* Start of policies */ MARK and 0xfffdffff 5 0 cali-pi-_aSNKqRMnpOIOKmNtmps all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:yWeySxiyqlzDge6R */ mark match 0x0/0x20000 0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:MBp5LDu3OvWXuLU5 */ /* Return if policy accepted */ mark match 0x10000/0x10000 5 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* cali:xqXC9Z3OJYEJmGgQ */ /* Drop if no policies passed packet */ mark match 0x0/0x20000注:其它网络插件跟Calico的原理类似,不做详述。
2 Cilium
Cilium作为Kubernetes集群众多网络解决方案的一种,是基于BPF以及XDP的高性能容器方案,可以在Linux内核动态插入强大的安全可见性和控制逻辑。由于BPF在Linux内核中运行,因此可以快速应用和更新安全策略,而无需对应用程序代码或容器配置进行任何更改,相对于iptables更高效。由于Cilium比较新,尚未完全支持NetworkPolicy,但它不但提供L3/L4层的访问控制,还提供了L7层的访问控制。Cilium架构图如下所示:
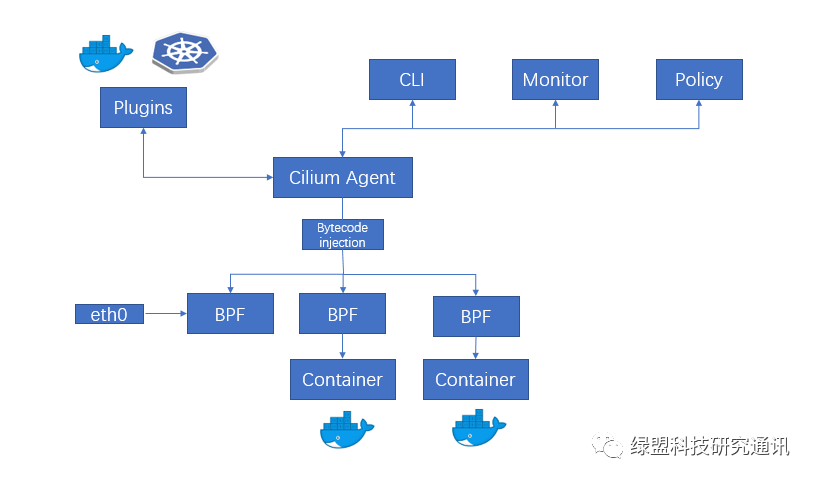
Cilium也是以 DaemonSet的形式部署在Kubernetes集群中,主要包含以下资源:
 Cilium的访问控制流程:
Cilium的访问控制流程:
1. Kubernetes负责将策略分布到集群中的所有节点
2. Cilium将自动应用策略,通过cilium-agent将网络安全策略的Bytecode注入到在容器运行时产生的BPF程序中,从而控制容器Endpoint的流量。在Cilium中有两种格式可以直接使用Kubernetes配置网络策略:标准的NetworkPolicy只能提供L3/L4层的访问控制;CiliumNetworkPolicy则可以提供L3-L7层的访问控制,具体的示例详见[4]。3 Kube-routerKube-router作为Kubernetes联网的整套解决方案,操作起来比较简单。它是围绕观察者和控制器的概念构建的。其架构图如下所示:
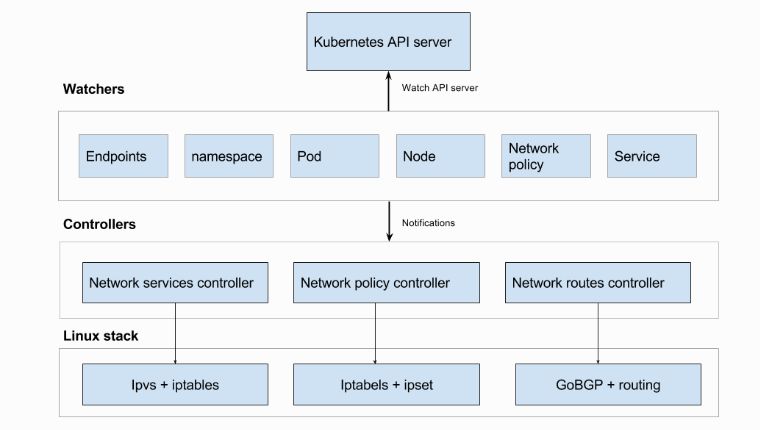
由上图可知Kube-router通过网络策略控制器,可以监视Kubernetes API服务器的任何网络策略和pod更新,从而动态配置iptables和ipsets来进行网络流量控制,它完全支持Kubernetes的NetworkPolicy策略语义,对集群的性能影响较小。它也只能提供L3/L4层的访问控制。
4 Flannel
Flannel的部署相对要简单些,但它本身并不支持NetworkPolicy,需要配合Canal来支持NetworkPolicy,不做详述。
5 Weave Network
Weave Network作为Kubernetes的网络解决方案,为Kubernetes提供了2层网络上的VxLAN。与使用etcd存储数据的其他网络解决方案不同,Weave Network将其数据保存在/weavedb/weave-netdata.db文件中,并通过DaemonSet在每个pod 上共享它。
Weave Network支持两种模式,一种是Sleeve模式,一种是Fastpath模式,下图是Fastpath模式的架构图:

Weave Network是以DaemonSet形式部署在Kubernetes集群中,它在集群的每一个节点上都会启动一个pod,pod包含的容器如下所示:
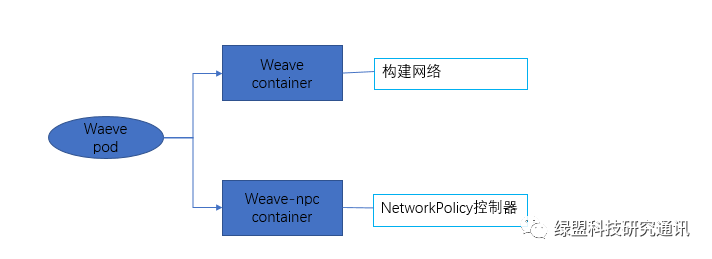
Weave容器会在每个节点上创建Weave网桥,所有的容器都会连接到这个网桥,跨主机通信是通过openvswitch vxlan来实现,NetworkPolicy控制器将自动监视Kubernetes在所有名称空间上的NetworkPolicy,并配置iptables规则来限制进出Pod的流量。对于NetworkPolicy,Weave Network仅仅支持NetworkPolicyIngressRule和基于Selector的NetworkPolicyPeer,并不支持IPBlock类型的Peer。
Weave Network的访问控制流程如下图所示:

这章节主要来说明如何使用NetworkPolicy来做访问控制。
NetworkPolicy与Kubernetes的其它配置一样,apiversion、kind、metadata以及spec是其必选字段。其中spec里面包含的字段详见第三节的spec平面展开图。在创建完yaml文件后,可以通过执行kubectl apply/create -f policy.yaml来使策略生效。
默认情况下,如果名称空间中不存在策略,则允许所有的入口和出口流量进出该名称空间中的pods。我们可以通过下面的default policies来改变该命名空间中的默认行为。
Default deny all ingress traffic(拒绝所有进入流量)
Default allow all ingress traffic(允许所有进入流量)
Default deny all egress traffic(拒绝所有出口流量)
Default allow all egress traffic(允许所有出口流量)
Default deny all ingress and all egress traffic(拒绝所有出入口流量)
下面就以官网上给出的包含所有方面的例子来具体说明下:
apiVersion: networking.k8s.io/v1kind: NetworkPolicymetadata: name: test-network-policy namespace: defaultspec: podSelector: matchLabels: role: db policyTypes: - Ingress - Egress ingress: - from: - ipBlock: cidr: 172.17.0.0/16 except: - 172.17.1.0/24 - namespaceSelector: matchLabels: project: myproject - podSelector: matchLabels: role: frontend ports: - protocol: TCP port: 6379 egress: - to: - ipBlock: cidr: 10.0.0.0/24 ports: - protocol: TCP port: 5978上面yaml文件定义的策略包括:
1. 隔离“default”命名空间中“role=db”pod的进出口流量(如果它们还没有隔离的话)。
2. 允许“default”命名空间中带有“role=frontend”标签的pod连接“default”命名空间中“role=db”pod的6379端口;允许带有“project= myproject”标签的命名空间下的所有pod连接“default”命名空间中“role=db”pod的6379端口;允许IP地址在(172.17.0.0–172.17.0.255以及172.17.2.0–172.17.255.255)之间的pod连接“default”命名空间中“role=db”pod的6379端口,除了172.17.1.0/24。
3. 允许“default”命名空间中带有“role=db”标签的pod连接10.0.0.0/24地址块的5876端口。
下面就通过一个具体的示例来说明下:
首先创建namespace policy-test
# kubectl create ns policy-testnamespace "policy-test" created分别创建db、web服务
# kubectl run --namespace=policy-test db --image=redisdeployment "db" created# kubectl expose --namespace=policy-test deployment db --port=6379service "db" exposed# kubectl run --namespace=policy-test web --image=nginxdeployment "web" created# kubectl expose --namespace=policy-test deployment web --port=80service "web" exposed# kubectl get pod --all-namespaces -o widepolicy-test db-7848d446b5-mm7jq 1/1 Running 0 16m 10.233.0.11 ubuntupolicy-test web-774cd5bcb-t7lvx 1/1 Running 0 13m 10.233.0.12 ubuntu在未创建任何策略前,我们可以成功访问web的80端口,通过下面指令可以尝试
# wget -q web -O –Welcome to nginx!
If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.For online documentation and support please refer to
nginx.org.Commercial support is available atnginx.com.Thank you for using nginx.
接下来执行如下policy
kind: NetworkPolicyapiVersion: networking.k8s.io/v1metadata: name: web-deny namespace: policy-testspec: podSelector: matchLabels: run: web policyTypes:# kubectl create -f policy-test.yamlnetworkpolicy "web-deny" created现在重新访问web的80端口发现不能访问
# wget -q –timeout=5 web -O - wget: download time out上述例子只是一个很简单的演示,更多的例子请读者自行尝试。
五、小结
容器网络环境给网络安全防护带来的新挑战,不管是开源社区还是容器服务提供商都给出了一些解决方案。比如Kubernetes给出的 NetworkPolicy提供网络层以及传输层的访问控制,另可借助网络插件本身的策略就可以实现应用层的访问控制。我们需要结合自身网络环境特点选择适合自身的解决方案才可以更好保护容器环境。
参考文献:
[1] https://kubernetes.io/docs/concepts/services-networking/network-policies
[2] https://kubernetes.io/docs/concepts/services-networking/network-policies
[3]https://kubernetes.io/docs/concepts/workloads/controllers/daemonset
[4]https://cilium.readthedocs.io/en/v1.2/kubernetes/policy/#examples
声明:本文来自绿盟科技研究通讯,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
