数据分级分类,是数据治理,数据安全的基础。长期以来,针对数据分级分类,有许多的探索,包括各种机器学习的方法,都有一定的效果。大模型出现后,许多搞数据安全相关的公司纷纷宣布,使用大模型进行分级分类取得非常好的效果,包括效率大幅提升,准确率提高等。
大模型如何用来对数据进行分类分级?我们从大模型能力,Prompt提升,微调等方面,详细看看。
01、大模型的能力
大模型类似人脑,本身具备逻辑分析能力,可以直接用于数据分类,举个简单的例子:
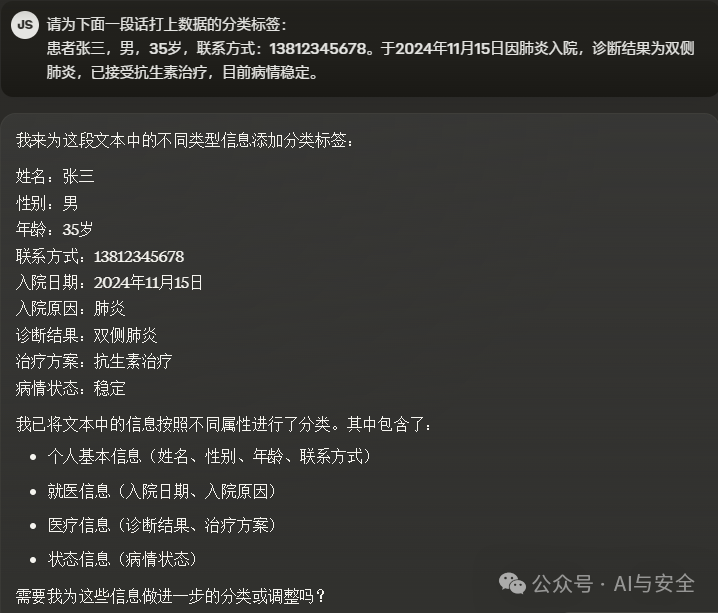
也可以要求它直接输出JSON格式,便于代码解析
{"患者基本信息": {"姓名":"张三","性别":"男","年龄":"35岁","联系方式":"13812345678"},"就医信息": {"入院日期":"2024年11月15日","入院原因":"肺炎"},"医疗信息": {"诊断结果":"双侧肺炎","治疗方案":"抗生素治疗"},"状态信息": {"病情状态":"稳定"}}
02、Prompt增强
以上的分类,基于直觉虽然没什么错误,但离商用还远,实际上,分类的标准并不固定,有各种各样的要求,这种情况下,需要把分类标准直接告诉大模型,按需要的标准分类。
以下是一个简单的例子:


大模型有个神奇咒语,叫 think step by step,在数据分类的时候也可以应该,包括指定它的处理步骤,比如:


整体分类结果还是很清晰的。
03、指令微调
实际的数据分类非常复杂,有各种各样的要求,还有许多国标和行标,以及企业针对自身情况制定的一些分类标准,要求大模型按这些标准进行分类,需要准确告诉大模型这些分类标准。而要准确描述这些分类标准,可能需要几千字甚至更多,这个会带来效率的降低和成本的提升(需要很多Tokens)。解决这个问题的方法是使用指令微调。
当有大量领域特定数据,不太容易描述时,也可以使用微调。
指令微调比较简单,象openai,claude,千问等,都开放了微调API, 所有的开源模型都支持微调,但需要准备微调数据集,数据的内容大体是这个样子:
training_data = [{"instruction":"判断以下医疗文本的科室分类","input":"患者出现头痛、恶心、视物模糊等症状","output":"神经内科"},# 更多训练样本...]
微调后可以大幅简化Prompt,理论上也可以提高准确率(主要取决于数据集的质量)。
04、更复杂的形式
实际的分类工作会更复杂,在问题优化时不断强化能力,结合各种手段的使用,取得更好的效果。以下是论文提到的一种方法

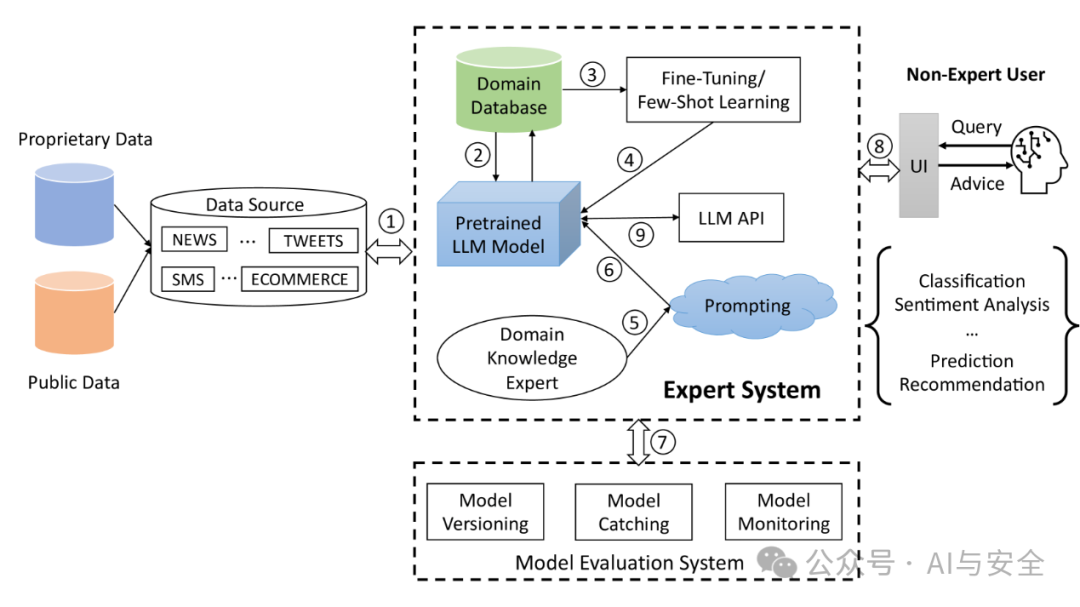
框架的步骤可以包括:(1)从数据源收集数据以建立领域数据库;(2)将特定领域的数据发送到预先训练的 LLM 模型,如 GPT-4、Llama-3 等;(3)使用一些特定领域的数据进行微调或小样本学习;(4)将微调或小样本学习应用于预训练的 LLM 模型;(5)(可选)利用领域知识专家设置提示以提高 LLM 性能;(6)在预训练模型中应用提示;(7)评估整个专家系统的性能;(8)非专家用户通过用户界面向专家系统查询任务;(任务可能包括分类、情绪分析、预测、推荐等。在本文中,我们以分类和情绪分析为例。)(9)LLM API 与用户界面和预训练的 LLM 模型交互,为用户界面提供建议。
05、大模型用于分类的实际效果
以下是一个安全公司提供的流程图和效果图,看上去用大模型分类的结果很好,并且效率提升也很好。
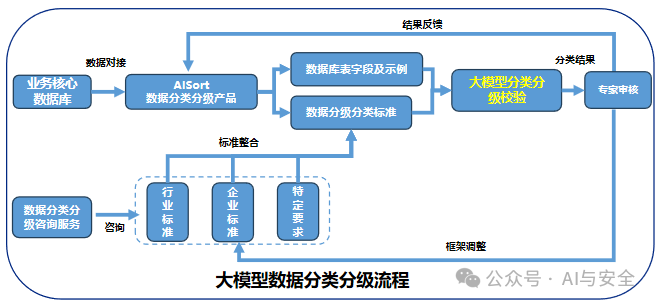
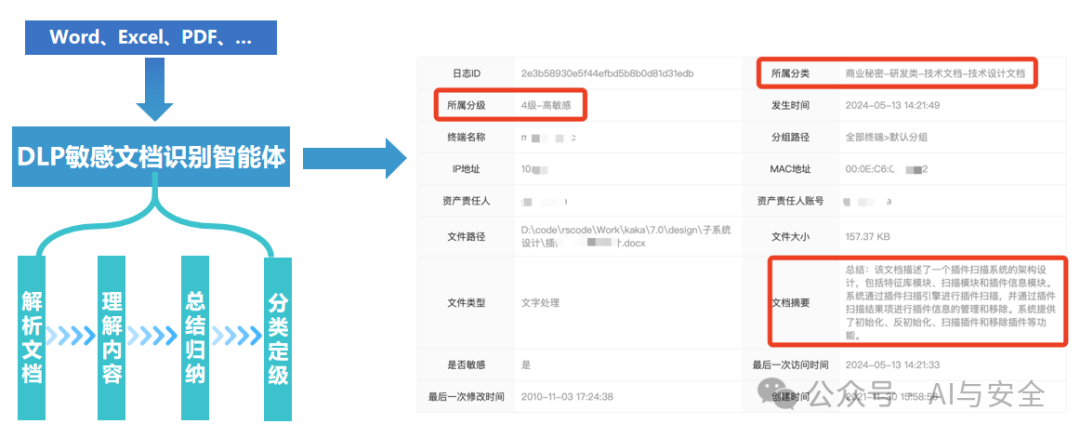
06、总结
以前的分类流程,复杂且难以实现:
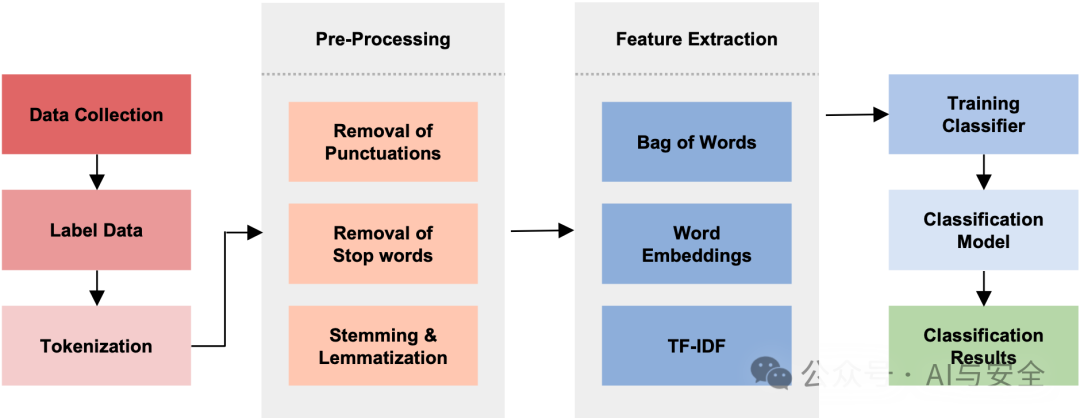
现在的分类流程,简单直接:

基于大模型开发分类的代码,大约只需要几十行。
原来非常复杂的软件,现在变得极其简单,只能说,软件的世界正在发生剧变。
注:
1.文中的大模型例子用的是Claude的免费版本
2.Github上使用大模型分类的例子
https://github.com/jeffheaton/app_generative_ai/blob/main/t81_559_class_03_4_classification.ipynb
3.论文地址:
https://arxiv.org/html/2405.10523v1
声明:本文来自AI与安全,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
