近日,网信办等四部分决定开展【关于开展“清朗·网络平台算法典型问题治理”专项行动的通知】。公号在之前的三篇文章对相关涉及的算法进行了一些概述。应相关同学的要求,公号君试图对这些算法全生命周期做进一步的整理和介绍。今天针对推荐算法。
下图展示了推荐系统的总体框架。推荐系统中数据驱动模型的生命周期始于数据采集,然后是存储和准备。这将导致特征工程,形成数据管道的基础。数据管道为训练管道提供数据,训练管道包括模型训练和验证。训练完成后,这一过程包括候选模型的生成和排序。这一过程还辅以 A/B 测试、离线和/或在线评估。最后阶段包括部署和监控。
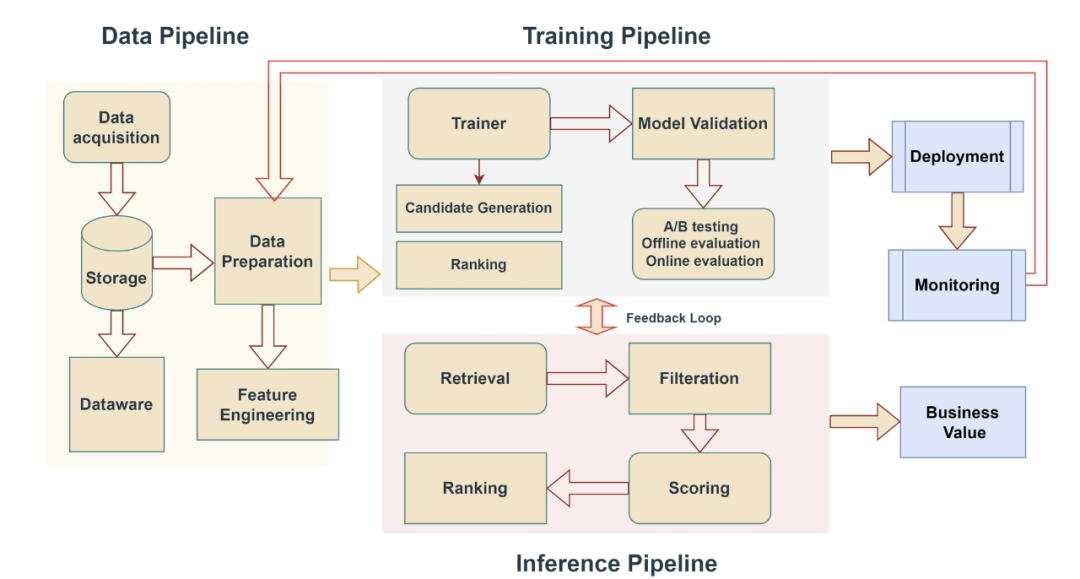
训练阶段
1. 数据准备(Data Preparation)
数据准备是推荐系统的基石,直接影响到模型的性能和效果。在这一阶段,首先需要从多种来源收集数据,包括用户的浏览、点击、购买等行为日志,商品或内容的属性信息,用户的个人资料,以及可能的评论和评分等。这些原始数据通常是未经处理的,可能存在噪声、缺失值和异常值。
因此,数据清洗是必不可少的步骤,需要对数据进行筛选,去除重复记录、异常值和不完整的数据条目。对于缺失值,可以采用多种方法进行处理,如填充平均值、使用插值法或者删除包含缺失值的记录。数据的标准化和归一化也是关键步骤,特别是在不同特征具有不同量纲的情况下,这有助于提高模型训练的效率和稳定性。
此外,数据准备还涉及将不同数据源进行整合,确保数据的一致性和可用性。例如,将用户的行为数据与商品的特征数据关联起来,形成一个完整的、可用于模型训练的综合数据集。这一步需要解决数据格式差异、主键匹配等问题,可能需要使用ETL(Extract, Transform, Load)工具或编写定制的脚本。
2. 特征工程(Feature Engineering)
特征工程的目标是从原始数据中提取出能够提升模型性能的有效特征。首先,需要进行特征选择,通过统计分析或模型评估,识别并保留与预测目标高度相关的特征。可以使用皮尔逊相关系数、卡方检验等统计方法,或者基于模型的重要性评分。
接下来,对类别型特征和数值型特征进行适当的处理。类别型特征可能需要进行编码,如独热编码(One-Hot Encoding)或嵌入表示(Embeddings),以便将其转化为模型可接受的数值形式。对于数值型特征,可能需要进行离散化或标准化,以减少异常值的影响和加快模型收敛。
新特征的生成也是特征工程的重要部分。通过对现有特征进行变换、组合或聚合,可以创造出新的、更有意义的特征。例如,可以根据用户的历史行为计算其活跃度、偏好倾向,或者根据商品的销售数据计算其流行度和趋势。特征降维技术,如主成分分析(PCA),可以在保持数据主要信息的情况下,降低特征维度,减少计算复杂度。
3. 模型训练与验证(Model Training and Validation)
在模型训练阶段,利用经过特征工程处理的数据,训练推荐系统的核心算法。首先,需要根据业务需求和数据特点选择合适的模型类型。传统的方法包括基于记忆的协同过滤、矩阵分解等;而近年来,深度学习模型如深度神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)和图神经网络(GNN)在推荐系统中也得到了广泛应用。
模型训练过程中,需要设定和调整超参数,如学习率、正则化系数、网络结构等。这些参数对模型的性能有显著影响,通常需要通过实验和验证进行优化。训练算法一般采用随机梯度下降(SGD)及其变种,如Adam、RMSProp等,以最小化损失函数。
模型训练完成后,进入验证阶段。使用验证集评估模型的性能,防止过拟合或欠拟合。评价指标可能包括准确率、召回率、F1值、AUC(Area Under Curve)、NDCG(Normalized Discounted Cumulative Gain)等。交叉验证是一种常用的方法,通过多次训练和验证,评估模型的泛化能力。根据验证结果,可能需要调整模型结构或超参数,迭代优化,直到模型性能达到预期。
4. 候选生成与排序(Candidate Generation and Ranking)
推荐系统通常采用多阶段架构,首先是候选生成,然后是精细排序。在候选生成阶段,从庞大的物品集合中快速筛选出一小部分可能感兴趣的物品。这一步需要高效的算法,通常使用基于内容的过滤、协同过滤、用户或物品的相似度计算等方法。目标是在保证召回率的同时,控制计算成本。
在排序阶段,对候选物品进行更精细的评分和排序。使用更复杂的模型,如梯度提升树(GBDT)、深度神经网络(DNN)、深度因子分解机(DeepFM)、自注意力机制(Transformer)等。这些模型可以利用更丰富的特征,包括用户的历史行为序列、上下文信息、物品的细粒度属性等。通过学习用户和物品之间的复杂交互,模型能够对候选物品进行准确的评分。排序结果可能还需要考虑多目标优化,例如在点击率和多样性之间取得平衡。
5. A/B 测试与模型评估(A/B Testing and Evaluation)
在模型上线前,需要对其进行全面的评估。离线评估使用测试集,基于历史数据,计算模型的预测性能指标。然而,离线评估的结果并不能完全反映模型在真实环境中的表现。因此,在线评估是必要的。
A/B 测试是最常用的在线评估方法。将用户随机分为实验组和对照组,实验组使用新模型,对照组使用现有的基准模型。通过对比两组在实际业务指标上的表现,如点击率、转化率、停留时间、收益等,评估新模型的效果。需要注意的是,A/B 测试应持续足够长的时间,并且样本量足够大,以确保统计结果的显著性和可靠性。
部署阶段
1. 模型部署(Deployment)
模型部署是将经过验证的模型应用到生产环境的过程。在这一阶段,需要将模型从开发环境迁移到线上环境,并确保其能够高效、稳定地运行。为了满足实时响应的需求,可能需要对模型进行优化。例如,使用模型压缩技术(如剪枝、量化、知识蒸馏)来减小模型大小,提高推理速度。
采用高性能的推理框架,如TensorRT、ONNX Runtime,或者利用硬件加速(如GPU、TPU)也是常见的做法。为了保证服务的高可用性和可扩展性,通常会采用微服务架构和容器化技术(如Docker、Kubernetes),实现负载均衡、自动扩展和故障恢复。部署过程中,还需要设置监控和日志系统,方便后续的维护和优化。
2. 实时推理与反馈(Inference and Feedback)
模型部署后,需要处理真实的用户请求,进行实时的推理和推荐。当用户访问平台或产生交互行为时,系统会根据当前的上下文和用户的历史数据,实时生成个性化的推荐结果。这些结果经过排序和过滤后,呈现给用户,以提高用户的体验和满意度。
同时,系统会记录用户对推荐内容的交互行为,如点击、浏览、购买、收藏等。这些反馈数据非常宝贵,可以用于实时更新用户的画像和兴趣模型,或者用于后续的模型再训练,形成一个闭环的反馈机制。实时的反馈处理可能需要使用流处理框架,如Apache Kafka、Apache Flink等,以确保数据的及时性和有效性。
3. 监控与运维(Monitoring and Operations)
为了保证推荐系统的稳定性和性能表现,部署后需要对系统进行持续的监控和运维。监控的内容包括系统资源的使用情况(如CPU、内存、网络I/O等)、服务的可用性(如响应时间、错误率、吞吐量等),以及业务指标(如点击率、转化率、收益等)。
当监控系统检测到异常时,需要及时采取措施,例如告警通知、自动重启服务、流量切换等。此外,定期的模型再训练和部署也是必要的,以适应用户兴趣和行为的变化。自动化的运维流程(如CI/CD管道)可以提高部署的效率和可靠性。
4. 业务价值生成(Business Value Generation)
推荐系统的最终目标是为业务创造价值。通过个性化的推荐,可以提升用户的满意度和忠诚度,增加平台的活跃度和收益。在部署阶段,需要密切关注推荐系统对业务指标的影响,确保技术的投入能够带来预期的回报。
这可能需要与业务团队紧密合作,了解业务目标和策略,调整推荐系统的参数和策略。例如,在特定的营销活动期间,可能需要增加某些商品的推荐权重;对于新用户,可能需要提供更具探索性的推荐内容。通过持续的优化和迭代,使推荐系统能够适应业务需求的变化,最大化业务价值。
综上所述,推荐系统的训练和部署是一个复杂而连续的过程,涉及数据处理、算法设计、工程实现和业务应用等多个方面。每个阶段都需要深入的专业知识和细致的工作,只有各个环节紧密配合,才能构建出高性能的推荐系统,为用户提供优质的个性化服务,并为业务带来持续的价值增长。
声明:本文来自网安寻路人,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
