作者:傅宏宇,袁媛,王峥,彭靖芷
导语:
大模型发展从训练走向应用,用户与模型之间的数据交互变得越来越频繁和紧密。随着大模型向智能体(Agent)方向发展,它们需要整合来自多个应用的数据,以执行用户更复杂困难的任务。
对于大多数普通用户来说,这些模型是如何使用他们提供的数据,就像是一个难以理解的“黑箱”。这种不透明性导致了信息不对称的问题,让用户担心自己的私密信息可能会在未经授权的情况下被用于模型训练,甚至可能通过这些模型泄露出去。而对于制定治理规则的专业人士,需要考虑智能体(Agent)新业态中各方数据的价值实现和责任分配,最佳状态是“用的时候能拿得来”,又需要“用前用后分得清”。
按用户与模型的数据交互方式进行场景拆分,分为微调训练、模型推理、Agent模式三类原子化的场景。针对每种场景,我们将完整梳理数据链路,明确界定安全风险点,并提出相应的治理建议。信任源于透明度,只有消除用户的顾虑,并清晰划分各方的权责,才能加速模型从基础技术向服务人类的演进进程。
面向未来,需要多方有效协同,提高对模型安全的信心,并坚持长期主义,不断积累公共知识,解决用户-模型数据交互的信息不对称和黑箱化挑战。而针对用户-模型数据“能分能合”的需求,可以引入数据使用事后责任规制,守住安全的同时为模型能力松绑。
总体而言,大模型变革了数据利用规律,需要突破现有关于数据权益和数据安全的制度束缚,为促进大模型对数据的“转换性使用”、形成“柏拉图表征”、创造更大的数据价值奠定信任基础。
一、用户-模型交互数据安全制约模型应用,限制模型更好的利用数据、发挥数据价值
大模型发展进入应用阶段,用户-模型数据交互更为密切。大模型在数据、算法与算力的规模化法则(Scaling Law)推动下,通用能力持续增强,准确度和稳定性显著提高,模型在工具软件开发、智能设备集成、场景辨识等多个领域推动了多样化应用的实现,大模型应用服务用户数显著攀升[1]。模型云上部署、用户具体应用场景通过API接口调用模型能力的“云+API”模式,能够有效满足模型应用的场景化要求,提供更为灵活、高效的支撑,成为大模型开发应用的主要方式[2]。大模型应用过程中用户-模型交互数据密切,模型将利用到个人用户的对话聊天记录、企业用户向模型传输的文档资料、以及手机、PC、智能汽车等端侧设备获取并用于模型处理的用户数据,较多涉及个人隐私或企业商业秘密。而随着AI Agent(智能体)的加速推广,模型需要分解复杂任务,并且调度管理各个应用,也就需要访问和汇聚用户和多个应用中的数据,交互数据也从单一的用户一方数据向各种来源的三方数据扩展。
复杂的黑箱化环境造成信息不对称,对用户-模型数据交互带来了安全挑战,增强透明度是重点解决方案。模型对于数据的使用和处理过程本身就具有黑箱化特征,由于涉及到一方、三方的多数据来源,对于交互数据怎么使用、会用到哪些数据等问题较难向用户解释清晰。此外,在模型黑箱化的情况下还叠加了一层执行环境的“黑箱”,由于用户担心平台“超级权限”的存在,以及对云上数据安全机制的不了解,容易对平台缺乏信任,担心数据在未被授权情况下被模型学习使用,带来数据滥用或泄露的安全风险。这就可以理解为何第三方报告显示,公司高管对生成式AI在数据安全(Data Security)和决策透明(Decision Transparency)的担忧分别从2023年的17%和9%,迅速上升到2024年的46%和35%[3];而头部生成式AI研发和应用公司的安全部门负责人,也都将敏感数据泄露(63%)、敏感数据过度分享(60%)、对个人信息的不合理使用(55%)作为最关心的安全挑战。[4]对此,本文将从典型的数据应用场景出发,解析用户-模型的数据交互链路,分析各场景中的核心安全风险,提出针对性的治理方案,为用户了解模型用数情况、实现用户数据可控可管理提供思路和方案。
从发展的角度,大模型将重构数据利用模式,为用户带来全新的数据价值,对此用户-模型数据安全问题不能局限于管控和限制,还需建立对大模型技术的信任,为大模型用好数据创设条件。大模型改变了数据利用的传统方式,通过对各种来源、各种类型数据的“转换性使用”,将数据中潜藏的客观规律转化为知识性的模型能力,通过模型推理和生成形成了绘制世界的“柏拉图表征”——模型能力的发展需要更为广泛的数据汇聚,各来源数据的“技术性共享”能够产生传统数据技术无法实现的“全面性理解”和“一致性表达”。[5]这使得大模型对用户数据的使用不仅不影响用户数据在传统场景中的价值,而且能将用户数据融合进入大模型能力之中,为用户使用大模型能力、参与大模型驱动的场景提供全新的价值基础。在推动用户数据向模型汇聚、利用模型重塑用户数据价值的过程中,还需要用户以及各类数据来源方形成统一的认知,对大模型技术的发展予以充分的信任。解决用户-模型交互数据安全问题的目标,除了有效管控各类场景中的核心风险外,更重要的是消除用户对大模型技术的不信任,让模型能够利用到好用户数据提升能力,并为用户提供更好的模型服务。因此,用户-模型数据安全的解决方案不应止于对数据流动的限制和控制,而是应当以终为始,以发展大模型能力、为用户创造数据新价值为目标,提高大模型技术和处理环境的透明度,增进用户对模型的理解,为更主动、更可控的用户数据-模型共享利用提供信任基础。
二、提高用户信任:用户-模型数据交互链路解析和安全应对
(一)保障执行环境安全、尊重用户权益,建立用户信任基础
保障用户-模型数据交互安全保障不是从零开始,而需要建立在确保执行环境安全、保障用户数据权益的基础之上,进一步针对用户-模型的数据交互链路,提高数据处理的安全性以及用户对各来源数据的可控性。在建立数据交互对应性保障机制之前,首先需要建设云侧、端侧等执行环境的安全保障能力,采取协议承诺、技术管控等方式让用户对自身数据可控可管可审计,为用户进一步使用模型、与模型进行数据交互奠定信任基础。
其一,保障用户数据处理环境的安全一致性。无论是端侧还是云侧,用户-模型交互处理的整体环境应当在数据安全保障级别上需要和用户私域等同,用户数据在各类执行环境中都受到同等的安全保护,例如对企业用户需高度关注企业商业秘密在传输、存储过程中的加密和防攻击,应用处理过程中的权限限制,对个人用户则要保障对其个人数据的控制权和安全性,保证对数据处理的知情同意。
其二,保障用户对自身数据的高度可控性。严格遵守用户指令,以用户授权为前提,强化权限保护、数据可控性、可审计性,责任可追踪。一方面,通过授权和密钥控制,保障用户数据的私密性,对用户数据管控和滥用防控,让用户了解并控制各执行环境中的数据使用情况,避免超权限、超范围、超目的的数据访问,做到“操作可审计”。另一方面,发现事故后快速定位问题源头,区分是用户不当使用、系统漏洞还是外部攻击等行为所导致的安全风险,做到“责任可追溯”。
而在保障执行环境安全、尊重用户权益的基础,可以进一步针对用户使用模型的特点,基于数据交互状态进行链路解析和针对性的安全治理。
(二)场景化拆分:用户-模型数据交互典型场景解析和安全应对
1、第1类场景:用户数据进入模型(以模型微调为例)
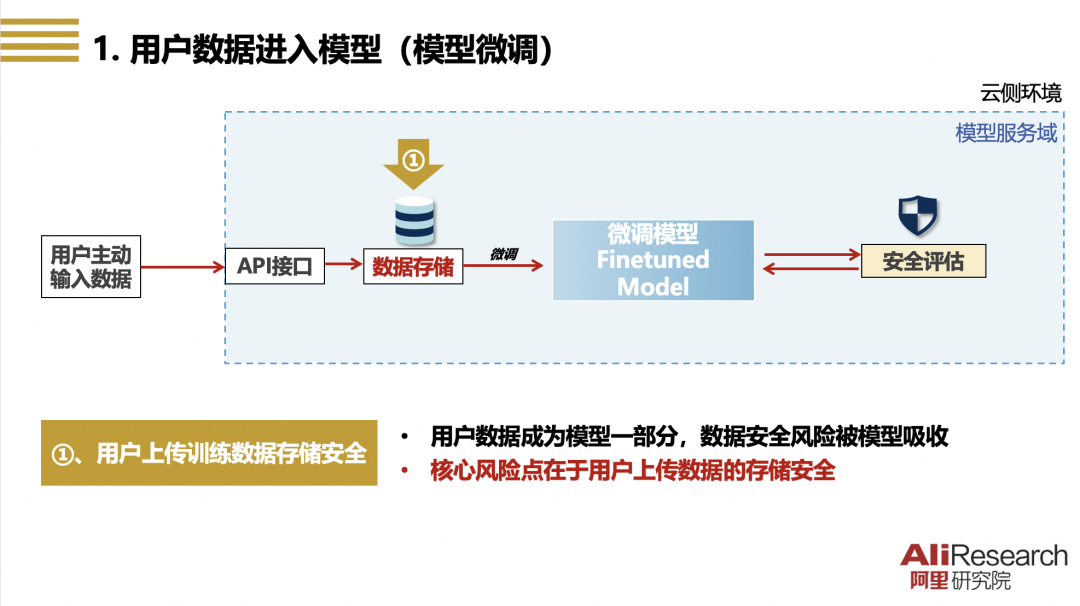
图一 用户数据进入模型(以模型微调为例)
【场景特点】在以用户微调模型为代表的、用户提供自身数据用于模型训练的场景里,用户将自有数据通过API接口上传至模型服务域进行存储,并用于用户模型的优化训练(如微调、对齐等),在通过模型服务安全评估以后,用户可以自行下载微调模型,或者在模型开发平台上发布并对外提供服务。在该场景下,用户和模型交互程度低,交互数据限于用户主动输入的数据,交互过程限于模型服务域对用户数据进行的存储以及提供用于模型训练,经过优化训练后的交互数据成为模型能力的一部分。
【主要风险】该场景中用户-模型数据交互的核心风险在于模型服务域用户数据存储(即图一所示的“①”)的安全保障。用户上传的优化训练数据可能包含用户的私密信息(如企业用户的商业秘密和个人用户的隐私信息)和其他的用户拥有控制权、具有商业价值的数据,需要保障模型服务域的用户存储数据完全归属用户所有、受到用户控制、仅由用户管理,非经用户许可不得把数据提供给第三方,或超出用户授权范围用于其他类型的模型训练。此外,用户数据用于微调模型后,还需要保证微调模型的安全性,在后续提供服务时不会生成敏感内容、泄露用户秘密。
【治理方案】针对上述安全风险的治理重点在于解决用户数据存储不透明、黑箱化问题,让执行环境的信息更为对称、充分,提高用户对上传数据的可控性:(1)将用户云侧或端侧的数据安全空间延伸至模型服务域的存储数据,对模型服务域的用户存储数据采取完全等同的安全保障机制,严格防护存储数据安全;(2)明确模型服务域的用户存储数据由用户完全所有,仅由用户管理,用户可以查看、审核存储数据的使用记录,可以访问和删除存储数据,非经用户明确授权不得将存储数据用于其他目的;(3)在模型训练前对模型输入数据进行识别,对敏感数据进行用户提示、二次授权或强制拦截,提升微调模型的内生安全,并在服务上线或可供下载前进行安全加固。
2、第2类场景:用户数据外置+API调用(模型推理)
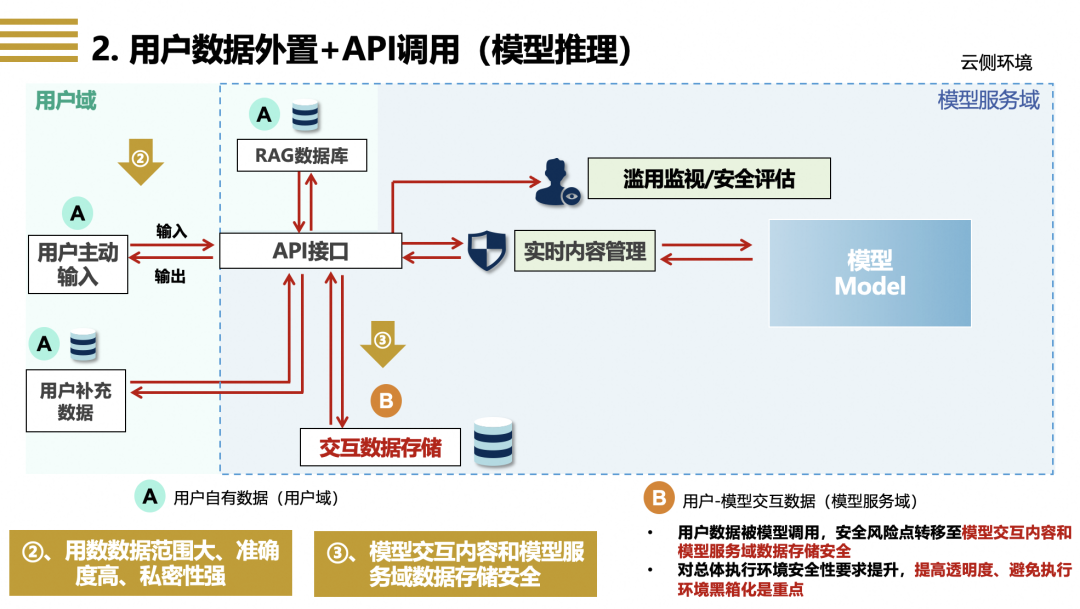
图二 用户数据外置+API调用(以模型推理为例)
【场景特点】在以模型推理为代表的、模型通过API接口接受或调取用户数据的场景里,用户通过API接口向模型输入用户数据(例如上传用户文档供模型分析并形成总结、提供详细指令信息由模型生成可执行代码等),模型利用用户主动输入数据,依据用户指令,基于模型自身能力提供推理分析、内容生成等服务,如果用户对结果有精准度、实效性、定制化等仅依靠模特通用能力难以实现的要求,模型则会进一步调用用户的补充数据,以及在模型服务域中存储于RAG数据库里的用户数据[6]。用户输入数据和模型调用的补充数据作为用户输入数据(即图二所示中的“ ”)与模型交互,并与模型输出数据一起存储于模型服务域的交互数据存储(即图二所示中的“
”)与模型交互,并与模型输出数据一起存储于模型服务域的交互数据存储(即图二所示中的“ ”)之中。交互数据存储中除了存储用户和模型的交互数据外,还存储了用户调用模型日志、模型运行状态、生成内容的安全状况等元数据。
”)之中。交互数据存储中除了存储用户和模型的交互数据外,还存储了用户调用模型日志、模型运行状态、生成内容的安全状况等元数据。
【主要风险】相比于第1类微调场景,推理场景中用户-数据交互更为密切,总体执行环境安全性要求进一步提升,对用户-模型交互数据的安全性和可控性要求更高,主要原因在于:(1)推理场景中用户提供的数据类型更为多样,为了提供特定的推理服务,用户必须输入高度精确的数据,而模型也会为了提高服务质量而获取更多的用户上下文信息,相比于利用用户数据进行模型优化训练而言,模型推理时用户主动或被动提供的数据范围更大、准确度更高、私密性更强(即图二所示的“②”);(2)推理场景中交互数据存储可能包含更为全面的用户-模型交互历史记录数据,此类数据的敏感度高,但同时也构成了模型理解用户意图、了解用户需求、向用户提供定制化服务的信息基础,不进行存储或进行周期性删除都会影响模型对特定用户的服务质量(即图二所示的“③”)。简言之,为了实现更准确全面的模型推理能力、让模型更好地服务用户,模型需要获取和存储更多更准更全的用户数据,但同时交互数据的安全风险也水涨船高。
【治理方案】应对推理场景的用户-模型交互数据风险,需要更为全面的、体系化的模型服务用户数据安全保障机制,强化用户输入数据的源头管理,以及交互数据存储的安全保障,并对用户进行主动提示和告知,提高用户-模型数据交互的透明度和可审计性。具体包括:(1)输入数据提示和确认:对用户输入数据,按照用户要求进行识别、分类、分级,用户输入数据涉及敏感数据类型或达指定数量时进行提示和二次确认,API调取用户数据时需严格依据用户授权;(2)交互数据可审计:交互数据存储在延续第1类场景保护要求(包括严格的安全防护、禁止非授权的其他用途等)的基础上,还需要进一步提高用户对交互数据存储的可管理性,用户除了可以管理存储中的交互数据,还可以随时审核交互数据存储中的元数据,了解交互数据存储的运行状态,包括模型依用户指令或基于其他目的对交互存储数据的调用情况,及时处置存储异常状况,并对用户进行提示和操作建议;(3)模型服务安全规范:用户-模型数据交互需依法合规,模型对用户提供服务(包括交互数据存储)需遵守法律要求,防止攻击模型、影响模型稳定性、侵犯他人合法权益的行为,面向C端用户提供模型服务和内容生成的,需要保证交互内容的安全性。体系化的模型安全治理方案和实践案例,可参考阿里巴巴《生成式人工智能治理与实践白皮书》。[7]
3、第3类场景:用户数据+三方数据+Model混合交互(Agent,Model as an OS)
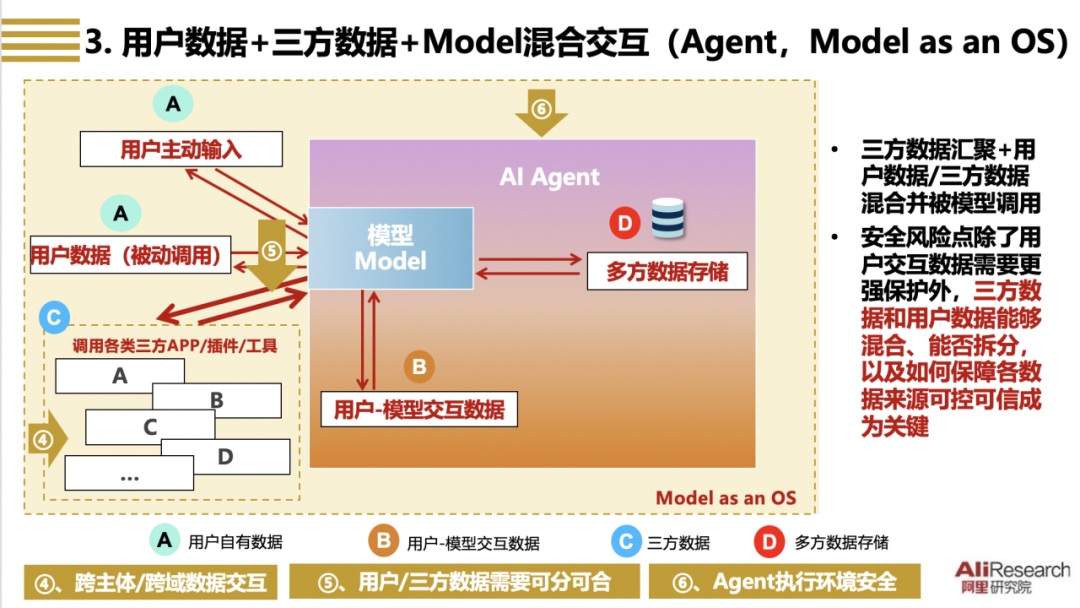
图三 用户数据+三方数据+Model混合交互(以Agent/Model as an OS为例)
【场景特点】在以Agent/Model as an OS[8]为代表的、用户数据-三方数据-模型混合交互场景里,模型除了通过提供推理服务等方式与用户进行数据交互外,还需要调用三方APP、程序、插件或工具,获取三方数据,为用户执行更为复杂的任务,实现包括意图理解、指令规划、流程设计、内容编排等系列功能。和第2类场景相比,本场景的新特点在于模型在执行复杂任务时需要更高的自主性,除了需要使用用户的输入数据(包括主动输入和被动调用,即图三所示的“ ”)以及用户-模型交互数据(即图三所示的“
”)以及用户-模型交互数据(即图三所示的“ ”),还需要尽可能多的三方数据(即图三所示的“
”),还需要尽可能多的三方数据(即图三所示的“ ”),包括用户在其他APP或程序中的数据,也需要三方供应商提供的数据,从而提高Agent服务的协调性和连贯性。用户数据和三方数据与模型交互,输入数据、输出数据以及交互的日志数据等元数据则存储于多方数据存储之中(即图三所示的“
”),包括用户在其他APP或程序中的数据,也需要三方供应商提供的数据,从而提高Agent服务的协调性和连贯性。用户数据和三方数据与模型交互,输入数据、输出数据以及交互的日志数据等元数据则存储于多方数据存储之中(即图三所示的“ ”)。
”)。
【主要风险】相较于第2类场景,本场景的特点是模型处于数据交互链路的中心,多来源数据同时与模型交互需要实现“可合可分”,在促进各类数据向模型汇聚的同时厘清各来源数据的利用规则、安全要求和后续责任,存在的主要挑战包括(1)三方数据来源之中包含对Agent执行任务所需的用户数据,例如利用模型完成旅游行程规划任务需要获取在交通、餐饮、住宿APP中的用户数据,这些数据虽然是用户数据,但向模型汇聚的过程中涉及数据的跨主体转移,需要获取用户的授权,并对数据的处理过程采取相应的保护(即图三所示中的“④”);(2)由他人合法持有的三方商业数据,需要模型服务提供方和数据来源方对数据获取的方式、范围、目的,对数据使用的对价和责任分配方式进行明确约定,保障各方合法的数据权益,做到“可合可分”(即图三所示中的“⑤”);(3)模型服务提供方对数据交互的执行环境承担安全保障义务,以保证Agent服务的高效稳定、保护各方数据的安全和私密状态(即图三所示中的“⑥”)。
【治理方案】为保证多方数据有效可用、来源可分、责任可判,可以从以下方面进行治理:(1)对于存储在三方APP或插件中的用户数据的汇聚使用,需要事前获得用户的明确授权,向用户告知使用的目的、获取的数据范围和数据存储、删除规则,并在模型日志中记录三方来源的用户数据使用情况,供用户查阅审计;(2)对于需要调用的三方数据,模型服务提供方应当与三方数据来源方签订数据使用协议,保证三方数据的可及性和合法性,对于因三方数据问题影响模型服务、对用户带来损失、引发安全事件的,对各方的后续责任进行约定;(3)对多方数据来源的总体管理,模型服务提供方需对三方数据来源方(如APP、插件)承担管理责任,明确三方数据来源方准入、数据上架规则,建立多方数据利用执行安全标准,向用户公开公示多方数据来源管理规则和重大事件的处置情况。
4、跨端跨域多模型交互场景(以端云协同为例)
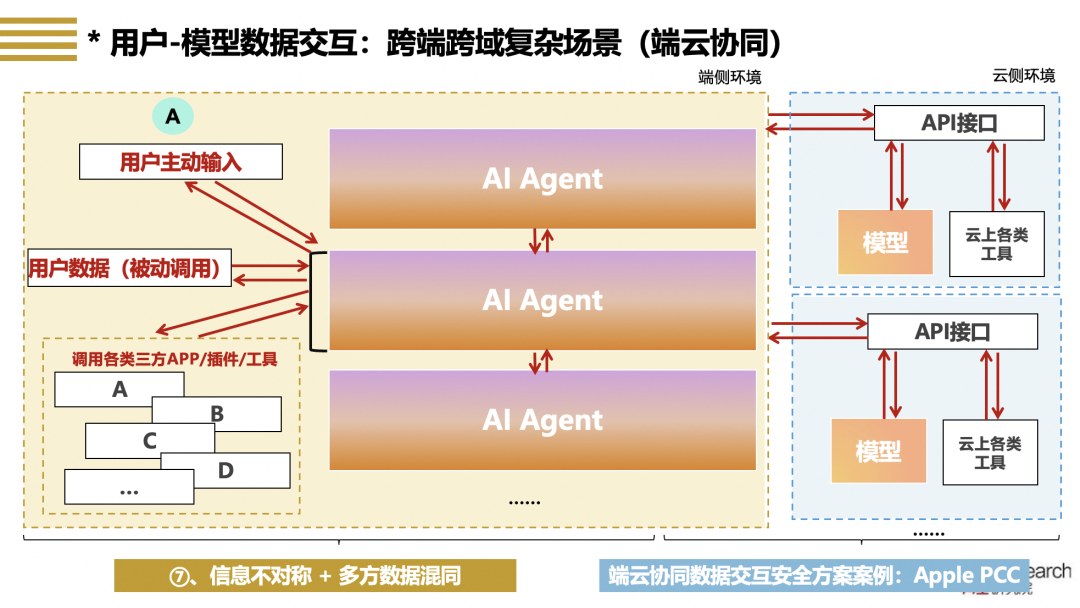
图四 跨端跨域多模型交互场景场景(以端云协同为例)
【场景特点】模型应用进入端云协同阶段后,用户-模型的数据交互总体更为复杂,前述三类场景将在端侧和云侧的执行环境中同时出现,例如图四所示,在端侧有多个模型Agent对用户提供服务,每个Agent获取用户在端侧的数据以及三方来源的数据,Agent之间也进行数据交互,同时端侧Agent也通过API接口和云侧的模型以及云上的数据库、插件和工具进行交互,通过端云协同的方式完成复杂的用户任务。
【主要风险】尽管如此,端云协同下用户-模型的数据交互模式主要还是按照前述三类场景展开,推理服务和Agent服务都可能在端侧或云侧单独或联合提供,因此端云协同下用户-模型的交互数据安全风险相较于前述三类场景并没有更多风险增量,通过提高数据交互执行环境的透明度、增强信息对称性,以及厘清多方数据混同中的源流和责任、做到各方数据能分能合(即图四所示中的“⑦”),则能够解决端云协同场景下交互数据的核心安全挑战。
【治理方案】以苹果在PCC安全方案为例,苹果针对端云协同场景提出了六项措施[9],通过加固端侧执行环境以及端云间数据传输的安全性(PCC计算节点、端到端加密和数据卷加密、非目标性),在硬件和技术层面强化用户对交互数据的管控(访问权限控制、用户数据无状态计算),并引入可信三方对环境进行审核、检验(可验证的透明度),尝试解决交互数据执行环境安全性和透明度问题,让用户能够理解苹果在保护交互数据安全方面的努力,并通过三方专家审计方式建立更为可信的透明度机制。随着Apple Intelligence的普及,端侧模型对多方数据的需求也日益明显,端侧模型将作为OS在后台对各类跨主体的APP和程序进行权限控制和使用管理,对APP运行日志等元数据的管理和存储,以及APP和程序调度使用的合理性判定、违规行为监控等,可以期待Apple Intelligence将参照iOS长期对APP进行较强管控的经验[10],通过类似于与APP开发者建立相互信任的生态的方式,跨越数据隐私保护、数据跨主体流动的障碍,形成多方数据协同的合作模式。
(三)小结:场景拆分、针对治理可以提高数据交互透明度,多方数据融合还面临制度制约
总体而言,用户-模型数据交互链路虽然较为复杂,但主要处理链路可以拆分为上述以微调训练、模型推理、Agent模式三类原子化的执行场景,即使在端云协同中叠加多端多域多模型的执行环境,场景的复杂化也并不会带来更多的安全风险。对三类场景核心安全风险进行针对性的治理,可以实现用户数据向模型传输、在模型域存储、被模型训练或推理使用、在模型输出中呈现等各环节的有效管控,配合云执行环境基础安全保障、安全服务响应、模型内生安全加固等机制,引入可信第三方的评估审计,能够最大程度保障用户对模型数据使用的知情权和控制权,防止用户数据被非授权用于模型训练、通过模型泄露,让用户能够放心地使用模型,获得更好的模型服务。
同时也可以观察到,模型对数据利用呈现明显的多源性特点,尤其在agent场景,模型需要汇聚用户在三方APP中的数据以及三方来源数据,要求“用的时候能拿得来”,同时为了保证各方数据的价值实现和责任分配,又需要“用前用后能切分”,现有制度并不完全适配多方数据“能合能分”的实际要求。特别是使用的不同数据源难以完全由用户直接授权,而“概括性授权”的合理性尚无定论;而一旦后链路出现数据安全事件,又需要对各方的权责进行明确切分,但在模型进行应用编排时,从不同来源的数据中拆解数据链路,对问题源头进行精准定位也面临挑战。但从促进技术发展、提高模型服务能力的角度,事前过严的数据使用限制确实会影响模型能力的发展,限制以Agent为代表的复杂应用服务。
三、对用户-模型数据交互安全的思考:坚持长期主义,强调事后追责,重构用户信任
大模型重构了数据利用模式,为发挥数据价值提供了全新的最短路径。用户和模型进行数据交互是模型为用户提供服务、发展模型应用的必经流程和必要条件,用户-模型数据安全治理的目标是让用户理解模型对用户数据的利用机制,完善用户对交互数据的控制,防范交互数据的泄露和滥用,建立模型域可信可控的数据执行环境。面向未来,需要进一步构建顺应大模型技术特点、符合大模型数据利用规律的数据制度,促进数据的共享、开放以及向大模型的汇聚。
第一,多方有效协同,提高对模型安全的信心。模型安全是模型的核心竞争力,用户信任是模型应用和推广的前提条件,保障模型安全、建立用户信任需要企业识别核心风险、优化技术手段、主动承担责任,也需要各方形成共识、有效共治,政府牵头制定实践指南和技术标准,树立数据安全最佳实践并发挥引领作用,用户在使用模型服务时也需科学认识模型安全风险、了解应对方案、遵守用户准则,避免滥用误用。[11]
第二,坚持长期主义,解决用户-模型数据交互的信息不对称和黑箱化挑战。大模型技术快速发展,执行环境跨越云侧和端侧,智能体等新型应用模式不断出现,但公众及用户对于大模型技术和应用的理解还需要一个渐进的过程,对此各方应合力提高大模型的可解释性,针对大模型数据处理黑箱问题,增强技术方案的透明度,积累安全经验、技术方案、最佳实践等公共知识,促进各方的信息对称。[12]
第三,针对用户-模型数据“能分能合”的需求,引入数据使用事后责任规制,守住安全的同时为模型能力松绑。事前的过于严格产权规则不利于大模型汇聚多方数据来源、满足多样化任务执行的应用发展,多方数据的利用应从事前管控走向事中事后的追责机制,参考iOS对三方应用的管控机制,明确模型服务提供方的注意义务,保障各方合法权益,更好实现模型通用能力深入应用场景。此外,对于模型的数据使用,需要明确触及安全底线红线的数据类型,对于多方来源数据建立合理使用、惠益分享和资源补偿机制,以合作机制促进数据向模型的汇聚、供模型使用。
参考注释:
[1] 例如,2024财年第二季度使用阿里云AI平台(百炼)的付费用户数量相比第一季度环比增长超过200%,https://www.alibabagroup.com/zh-HK/document-1760376653793460224
[2]《阿里云大模型服务数据安全白皮书》,https://www.aliyun.com/why-us/security-compliance?spm=5176.29619931.J_dmpZNIHzjS8ItibpWfPfq.1.74cd59fcfzb9ia#5
[3] Lucidworks,The State of Generative AI in Global Business: 2024 Benchmark Report,P9
[4] Microsoft Secutiry,Accelerate AI Transformation with Strong Security,P12
[5] Huh, Mingyong et. al., The Platonic Representation Hypothesis.
[6] RAG数据库通常是指用户上传的文档等,作为外挂语料库,在推理过程中为大模型提供更为全面、准确、充分的上下文知识,提升输入内容的专业性合准确性。具体参见:王峥,傅宏宇,袁媛,《治理之智 | 检索增强:解决企业“上云用模”的数据安全隐忧》, 2024/09
[7] 阿里巴巴《生成式人工智能治理与实践白皮书》,https://s.alibaba.com/cn/aaigWhitePaperDetails/9x5JBSX2fyLEZWkRnKQ8f。2024年最新版白皮书《大模型技术发展及治理实践报告》将于近期推出,敬请期待。
[8] OpenAI 创始成员之一Andrej Karpathy 最早在2023年11月提出“LLM OS”这一概念https://x.com/karpathy/status/1723140519554105733
;另有相关研究团队提出“AIOS”这一概念:Ge Y, Ren Y, Hua W, et al. LLM as OS (llmao), Agents as apps: Envisioning AIOS, Agents and the AIOS-Agent Ecosystem[J].
[9] Apple Security Engineering and Architecture, et al. Private Cloud Compute: A new frontier for AI privacy in the cloud, 2024/06, https://security.apple.com/blog/private-cloud-compute/
[10] iOS生态系统下所有应用必须通过App Store发布,且需遵循苹果严格的审核标准和隐私安全政策:https://developer.apple.com/cn/app-store/review/guidelines/
[11] 推动信息共享、认知共建,让各类用户全面了解云侧数据安全保障水平,信任云端模型的数据处理,是推动模型应用的关键。具体参见:傅宏宇,王峥,彭靖芷,《模型上云的数据安全保护——以Apple PCC为借鉴》,2024/06
[12] 上海人工智能实验室治理研究中心、清华大学产业发展与环境治理研究中心等,《人工智能安全作为全球公共产品》,https://mp.weixin.qq.com/s/APky1qkOU2BuWTe_uBjYbA
致谢
感谢阿里云智能集团数据安全合规及风险治理团队,阿里云智能集团通义安全负责人张荣,阿里安全 AIGC 安全算法负责人陈岳峰为本文研究提供的理论支持和技术指导。
声明:本文来自阿里研究院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
