
原文标题:On Precisely Detecting Censorship Circumvention in Real-World Networks
原文作者:Ryan Wails, George Arnold Sullivan, Micah Sherr and Rob Jansen原文链接:https://www.ndss-symposium.org/ndss-paper/on-precisely-detecting-censorship-circumvention-in-real-world-networks/发表会议:NDSS 2024笔记作者:孙汉林@安全学术圈主编:黄诚@安全学术圈
1、引言
本文探讨了在真实网络环境中检测网络规避协议的挑战,指出现有检测方法具有较高误报率。随即提出了一种结合深度学习方法的基于主机的检测方案。该方法通过积累目标主机的流量序列信息,将流检测问题转化为规模更小的主机检测问题,从而显著提高了分类精度。实验表明,该方法在无误报的情况下实现了对规避主机的完美检测。研究还提供了针对未来规避系统设计的建议,强调使用临时混淆服务器及多样化协议来增强抗检测能力。
2、数据集
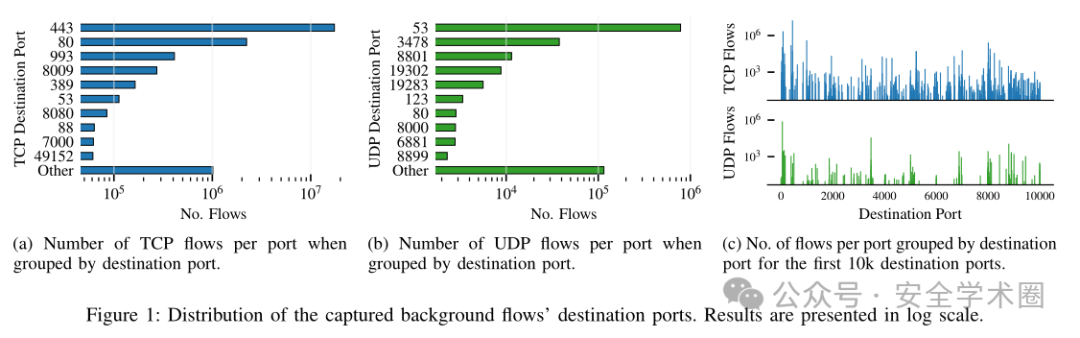
为了评估审查系统检测真实网络流量中混淆协议流量的能力,研究团队使用一所大学的WiFi网络观测点收集了一个私有网络流量数据集。该数据集包含背景流量和通过混淆协议生成的流量,并将捕获的流量分类为基于五元组的流。数据收集从2022年3月至4月为期两周,共捕获54355226条背景流量、83002条obfs4流量、207975条obfs⋆(改进熵值的obfs协议)流量以及5894149条Snowflake流量。HTTPS和DNS流量分别是TCP和UDP流量的主要组成部分,同时也观察到大量的长尾端口流量。此外,流量捕获过程中存在明显的昼夜模式,符合典型的网络使用行为。
3、基于流的检测方案
本文将基于流的检测方案按照机器学习的方法不同分为两部分,即传统机器学习和深度学习。
3.1 传统机器学习方案
研究团队复现了Wang等[1]提出的基于传统机器学习的流检测方案,利用(1)仅熵特征,(2)仅报头特征,(3)仅时间特征以及(4)同时结合熵和报头特征训练决策树。并使用此方案检测上节中采集的真实环境中的流量数据集,得到如下结果(其中λ表示非规避流量与规避流量数量的比值):
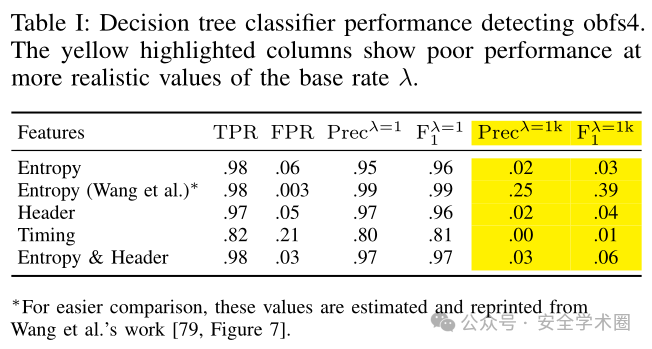
该结果表明,基于传统机器学习的检测方法,在真实环境下并不适用,且存在以下3个问题:
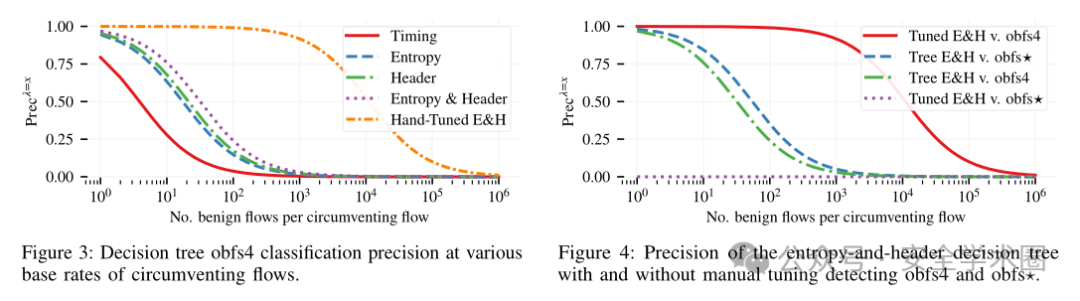
误报率问题
该方案对误报率的分析不够全面,仅针对大类别流量计算误报率。在开放世界场景中,当基准率降低到 λ > 1×10³ 时,分类器的精确率几乎为零,这说明该方案无法在真实环境中使用。适用性问题
该方案的分类器性能评估通常基于高基准率(如 λ = 1,非规避流量与规避流量数量1:1)的理想环境,而现实网络中的规避流量基准率远低于此。泛化性问题
该方案手工调优的分类器虽能提升对特定协议的检测性能,但其依赖特定特征(如熵分布和包大小)。文中设计的 obfs⋆ 协议通过调整熵和包大小特征,使分类器精确率和召回率降为 0% 。
3.2 深度学习方案
实验采用了三种神经网络模型,来自 Rimmer 等人[2]研究的堆叠去噪自编码器(SDAE) 和卷积神经网络(CNN),以及来自 Sirinam 等人[3]研究的卷积神经网络(CNN)。研究团队调整了最 后一层激活函数以适应二分类任务,保留了原始作者提供的大部分超参数,并根据实验需要调整输入维度。
在数据集方面,除了对obfs4和obfs⋆生成的流进行训练和测试外,研究团队还对Snowflake审查规避协议生成的流进行了测试,包含 TCP/TLS 的代理请求流,以及UDP/WebRTC 的数据通信流。将每个流的n(100、500、1000、5000)个数据包的大小归一化(范围 [-1, 1],符号表示方向)得到特征序列并输入模型。实验结果如下:
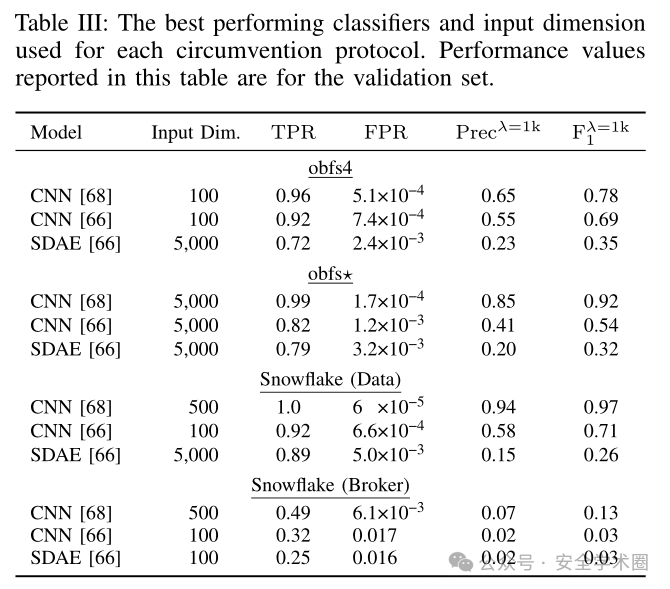
在所有模型中,Sirinam 等人的 CNN 模型表现最佳。CNN分类器仅通过包的大小和方向就能优于传统方法检测加密流量,这归因于obfs4和obfs⋆在网络传输中设计了独特的包模式,例如发送接近MTU大小的突发负载包后跟随机大小的填充包。这表明深度神经网络能够捕捉复杂的包突发序列特征。对此,本文针对CNN模型做了进一步研究。


实验结果表明,深度学习相较于传统机器学习在一定程度上提高了精确率,降低了误报率,尤其是在 obfs⋆ 和 Snowflake(Data)检测中表现突出。尽管如此,在更现实的基准率(如 λ > 1 × 10⁶)下,模型的精确度接近于零,仍然难以在实际环境中应用。
4、基于主机的检测方案
传统的机器学习方法检测精度过低,而深度学习方法虽然在一定程度上提高了精度,但仍达不到检测真实环境下流量的要求。基于主机的检测方案建立在深度学习检测流的方案基础上,通过记录每个主机的正分类比例 p/m(即该主机规避流量数占总流量数的比例)来进行检测。当正分类比例超过设定阈值时,将该主机标记为规避主机。该方法能够在检测所有 obfs4 和 obfs⋆ 网桥的同时,几乎完全消除误报。
流量最小观察次数 η 可由利用 Hoeffding 公式:η = ln(4/α²) / (TPR - FPR)² 计算。更保守的目标误报率α设置能进一步降低模型误报率,但会增加存储开销。
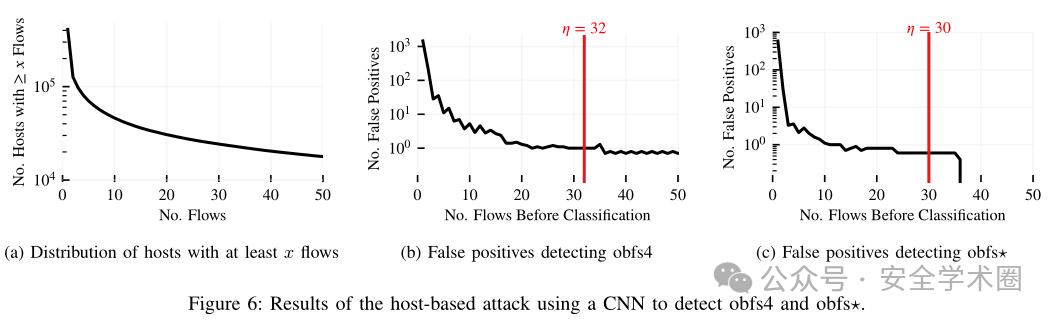
实验结果表明,大部分主机仅包含少量流,少部分主机包含大量流。该方案随着观测流量数量的增加,误报数呈指数级下降。在obfs4和obfs⋆场景下,平均在观察到30个流量后误报数降至1以下。38个流量后obfs⋆的误报数为0。obfs4和obfs⋆的实际主机误报率分别为2.4 × 10⁻⁶和1.5 × 10⁻⁶,与目标误报率α = 1 × 10⁻⁶接近,显著低于基于流的检测方案的误报率。
但是基于主机的检测方案也有一定局限性,这种方案要求每个主机在一段时间内有足够多的流量η用于分类,因此主要适用于行为稳定且流量较多的主机。
5、总结
这篇文章研究了在真实网络环境中检测规避协议的有效方法,重点探讨了基于流和主机的检测技术。作者首先以传统机器学习方法为引子,分析了其在规避检测中的局限性,随后深入探讨了深度学习技术在基于流检测中的应用。然而,研究发现,即便采用最新的深度学习技术,基于流的检测方法在高基准率下仍然存在较高的误报率,难以满足实际需求。对此,文章提出了一种基于主机的检测方案,通过统计多个流量的观察结果来提高检测精度和稳定性。同时,文章探讨了更进一步优化检测性能的可能方向,包括结合数据包有效负载分析和更复杂的深度学习模型,为现实网络中的规避检测提供了重要启示。
References
[1] Wang, Liang, et al. "Seeing through network-protocol obfuscation." Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security. 2015.
[2] Rimmer, Vera, et al. "Automated website fingerprinting through deep learning." arXiv preprint arXiv:1708.06376 (2017).
[3] Sirinam, Payap, et al. "Deep fingerprinting: Undermining website fingerprinting defenses with deep learning." Proceedings of the 2018 ACM SIGSAC conference on computer and communications security. 2018.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
