据Gartner预测,到2020年将有20%的公司使用人工智能技术提升企业内部应用和流程,到2021年,人工智能所增强的功能将产生2.9万亿美元的商业价值,节约相当于62亿小时人工的生产力。来自普华永道的预测也显示,到2030年人工智能将促使全球生产总值增长14%,届时将为世界经济贡献15.7万亿美元,而零售业、金融服务和医疗保健将是最大受益行业….
 人工智能在未来世界无疑将扮演重要的角色,在工业制造、医疗健康、教育、生活、安防、电商零售、金融等越来越多的领域都可以看到人工智能技术应用的身影。
人工智能在未来世界无疑将扮演重要的角色,在工业制造、医疗健康、教育、生活、安防、电商零售、金融等越来越多的领域都可以看到人工智能技术应用的身影。
但应注意到,研究者已发现在某些人工智能模型的输入上增加少量“干扰”,可在人类无法分辨区别的情况下使模型对输入的分类结果做出错误判断。这种经过处理后的输入样本通常被称为对抗样本。
事实上,寻找对抗样本可以归纳为下述问题:针对模型F:x->y,其中x为模型的输入,y为模型的输出。对于原输入x,找到输入x*,使得模型的输出被最大化为目标标签y*,y*不等于y,且要求x与 x*的“距离”最小。此时,训练的目标不再是模型的优化而是生成符合条件的细微扰动。正是按照这个思路,我们选取由谷歌提出并在ILSVRC大赛中取得优异成绩的inceptionV3模型和由Yann LeCun提出的手写数字识别模型LeNet5这两个经典网络模型分别进行实验,均达到了预期的攻击效果。
inceptionV3模型:
计算机视觉是本轮人工智能技术和应用发展的突出方向,当前陆续已有在智能驾驶、恶意内容和图片识别等场景的应用。为了对这些场景中对抗样本可能带来的挑战进行实际分析,我们使用在ImageNet数据集上训练好的inceptionV3模型展开了实验。
如图1所示,我们给上述模型输入一张车辆头部的影像,训练好的inceptionV3模型可以很好地识别出图片的所属分类为“sports car”。然后我们设计合适的反馈机制并逐步训练得到了一张人类看起来与原图并无区别的车辆头部影像,再次输入给inceptionV3模型,如图2,模型给出的识别结果却成了“mountain bike”。
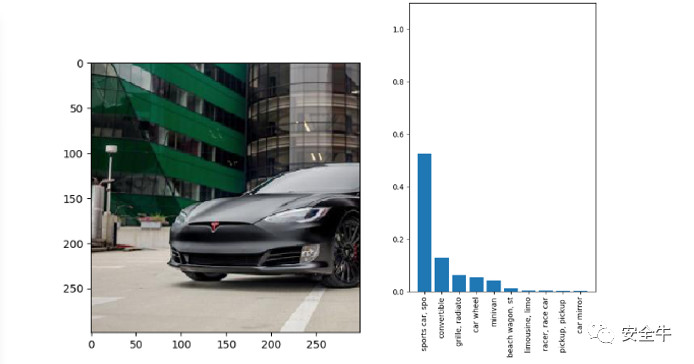 图1
图1
 图2
图2
接下来如图3所示,我们给上述模型输入一张左轮手枪的影像,训练好的inceptionV3模型可以很好地识别出图片的所属分类为“revolver”。然后我们同样设计合适的反馈机制并逐步训练得到了一张人类看起来与原图并无区别的左轮手枪影像,再次输入给inceptionV3模型,如图4,模型给出的识别结果却成了“paintbrush”。
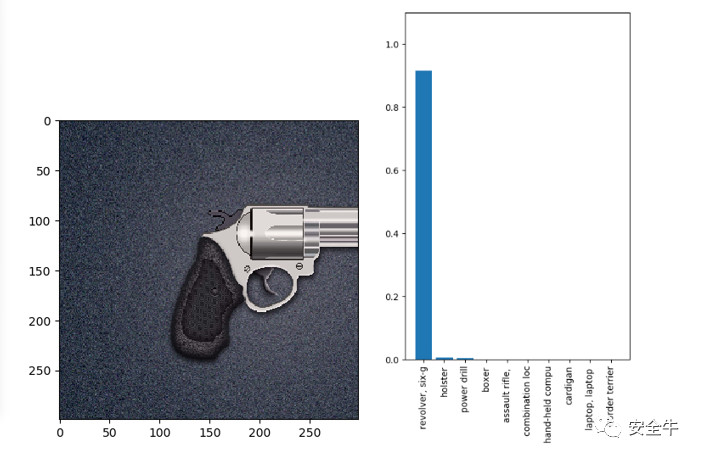 图3
图3
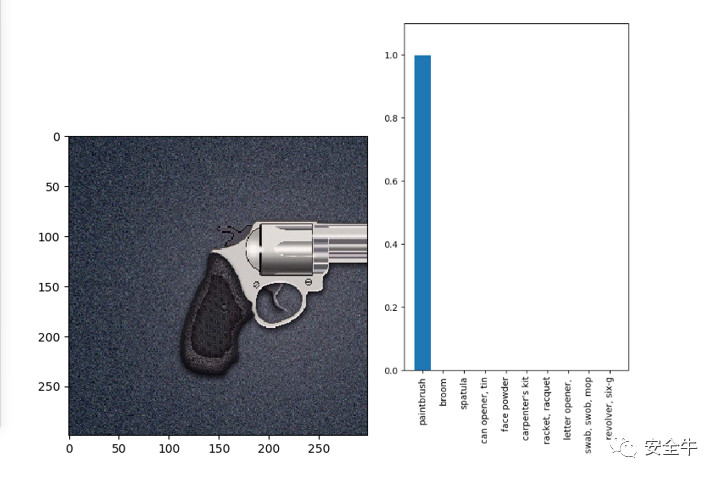 图4
图4
LeNet5模型
手写数字识别目前在互联网、金融等领域也有着很多应用,如票据和银行卡识别等场景。为了实验在手写数字识别的对抗样本情况,我们使用在mnist数据集训练好的LeNet5网络进行了实验。
如图5所示,我们给上述模型输入一张测试图像,训练好的LeNet5可以很好地识别出图片中的所属数字为“7”。经过我们处理得到一张人类看起来与原图无区别的测试图像,再次输入给LeNet5,如图6,模型给出的识别结果却变成了“3”。事实上,我们对mnist数据集中测试集的所有10000个样例进行了处理,经过测试可以将LeNet5的识别准确率降到0%,即对测试集中所有图像发起有效攻击。
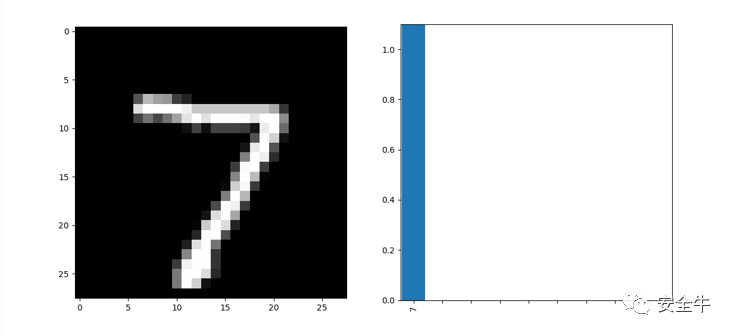 图5
图5
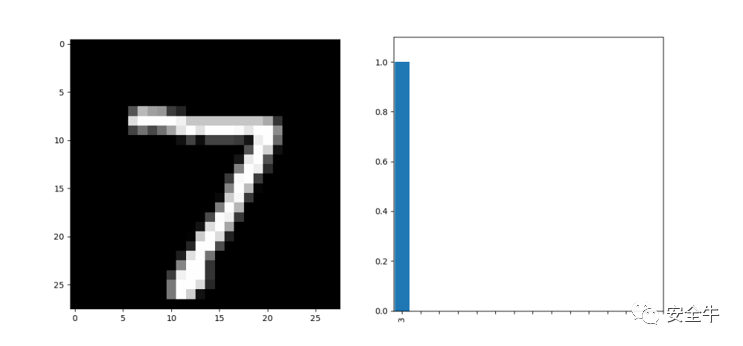 图6
图6
通过上述几组实验可以看出,利用对抗样本让攻击者可在很多应用场景上对人工智能模型本身发起攻击。而由于人工智能模型在业务系统中往往处于核心决策地位,因此与以往的网络安全攻击相比,这类攻击对实际业务运行造成的后果往往会更加严重。为了分析对抗样本的形成原因,我们在这里用较直白的语言介绍一下目前人工智能热点技术(如神经网络等)的主要运作机制。
1. 确定训练数据集和训练网络。训练数据集包括了训练数据和训练数据的正确分类标记,训练网络一般是一个由卷积、取样、全连接等层组成的网络模型,各层的各连接点上设置有一套初始权重参数;
2. 输入一个训练数据到训练网络,查看通过网络模型后得出的预测结果,得到其距正确标记有多远(损失函数);
3. 基于上一步的输出结果进行反向传播,使用一定的迭代步长来调整网络中各权重参数,使预测结果更接近于正确答案;
4. 使用训练数据集中的其他数据重复进行输入和调整过程,获得最终训练完成的判别网络。
目前虽然各式各样的新网络模型层出不穷,却基本遵循着上述基本机制。经分析可知,上述步骤所训练模型的有效性与训练数据集、网络模型、迭代步长甚至初始权重参数有关系。可正如George E. P. Box所言“all models are wrong, but some are useful”,这些模型能够获得优质结果其实最取决于接近“无穷”量级的训练数据。因此在所有有效输入组成的整个数据搜索空间中,我们通过上述“训练”方式所能得到的模型就是一个在相对有限情况下有效的模型了。也正是因为这个局限性,给予了攻击者利用对抗样本去攻击模型的足够空间。在人工智能的基础技术进一步突破之前,该问题会一直陪伴在我们左右,需要引起我们的足够重视。
梆梆安全一直以来都是从技术本质的角度出发,去进行网络安全研究和实践的。而从IT技术和安全技术诞生一刻起,就不存在绝对的安全,我们相信在飞速发展的人工智能时代同样如此。为此,我们更是力求深入地把握其本质,在了解技术前沿研究的基础上,努力做到合理的防护,保证其应用结果符合人类的原本预期。而对于对抗样本风险来说,以训练、对抗训练使能的安全防护技术去丰富人工智能时代的网络安全武器库,应当是目前技术发展现状下最为恰当之路。针对基于训练的对抗样本的识别和防护,以及squeeze features、胶囊网络、可解释模型等新思路,我们将进行持续研究和介绍。
作者:王天雨 梆梆安全研究院基础研究部高级研究员
声明:本文来自安全牛,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
