作者:交通银行软件开发中心(上海) 俞书浩
编者按:本文旨在对各式各样文本挖掘的技术进行梳理汇总,形成规范的文本挖掘思路,这样可以对同一份文本数据从各个角度各种方法全方位地分析,最大化地挖掘出文本中的价值。同时交行在实践中设计出了一套文本挖掘工具“诗艺”,“诗艺”将各类的方法打包模块化,形成可视化工作流,使用者无需编程就能进行分析,极大降低文本挖掘门槛,提升挖掘效率,创造业务价值。行业现状:对非结构化的文本进行挖掘,是大数据时代必备的能力之一。在金融科技中文本的数量和种类非常繁多,如客服中心来电总结、授信报告等等。而这些很多都没有被利用起来进行挖掘,一方面是因为非结构化数据的存储和整合缺少有效的管理方法;另一方面文本挖掘的技术比较散乱,既有传统数据挖掘方法,也有最新人工智能方法,缺少各个方法之间的协同。
文本挖掘技术梳理
本文对文本挖掘技术的梳理是基于数据挖掘的视角,数据挖掘的流程包括预处理、特征工程、算法建模、模型验证等;而爬虫采集抓取文本、自然语言处理NLP、搭建知识图谱等技术不在本文研究的范围内。
1.文本预处理技术
(1)文本数据整合:对于银行来说,大量的客户和交易信息都是结构化存储的,因此非结构化的文本数据在分析时也需要与这些结构化数据关联在一起,结构化数据可以对文本打上各种标签。
(2)分词技术:中文文本和英文文本最大的区别就在于需要分词,分词技术分为基于词典、基于统计、基于理解三大类。基于理解的技术属于NLP,还处在研究阶段,应用较少。目前比较主流的是基于词典的技术,同时使用基于统计的技术为辅助。
2.文本向量化技术(特征工程)
文本向量化技术最重要的作用是将非结构化的文本数据转化为结构化的向量,这样处理后,各种传统的数据挖掘算法就都可以使用了。
(1)传统的文本向量化技术:主要有BOW词袋模型、TF-IDF模型和Simhash模型,这三种方法都把每一个文本转化成了一个向量。
(2)词向量模型:人工智能兴起后,词向量模型Word2vec也热了起来,但词向量模型是把每一个词转化成一个向量,而一个文本包括很多词,所以被转化成很多词向量串联起来的矩阵。
3.算法建模
(1)无监督算法:传统的数据挖掘算法中的无监督算法主要是各种聚类算法,文本向量化之后,这些算法都可以使用。不过有一种专门用于文本数据的聚类算法“LDA主题发现模型”,不但可以把文本聚类,还可以显示出每一类的关键词是哪些,让人对每一类的意义一目了然。无监督算法还包括文本搜索技术,对新来的文本与文本库中的文本进行相似性比较。
(2)有监督算法:传统的数据挖掘算法中的有监督算法同样都可以使用,比如逻辑回归、决策树、随机森林、Xgboost等。而人工智能中的深度学习算法CNN、RNN在词向量处理后也可以使用。
4.情感分析
严格来说情感分析属于文本挖掘的一个应用而不是一项技术,但因为非常常用所以也纳入到我们的梳理范畴中。
(1)基于情感词典的情感分析:情感词典中收集了大量正面、负面、中性的词,统计每个文本中正面、负面、中性词的数量就能大致分析出文本的情感倾向。
(2)基于建模的情感分析:收集一批正面负面中性标签的文本,采用有监督算法(包括深度学习)来建模,建模结果是情感模型文件,使用情感模型文件,输入新的文本就能预测其是正面负面还是中性。
“诗艺”文本挖掘工具
交行在文本挖掘的工作中总结经验并采用创新项目的方式,设计研发出了一套“诗艺”文本挖掘工具。
1.整体设计
“诗艺”文本挖掘工具的整体设计见图1。
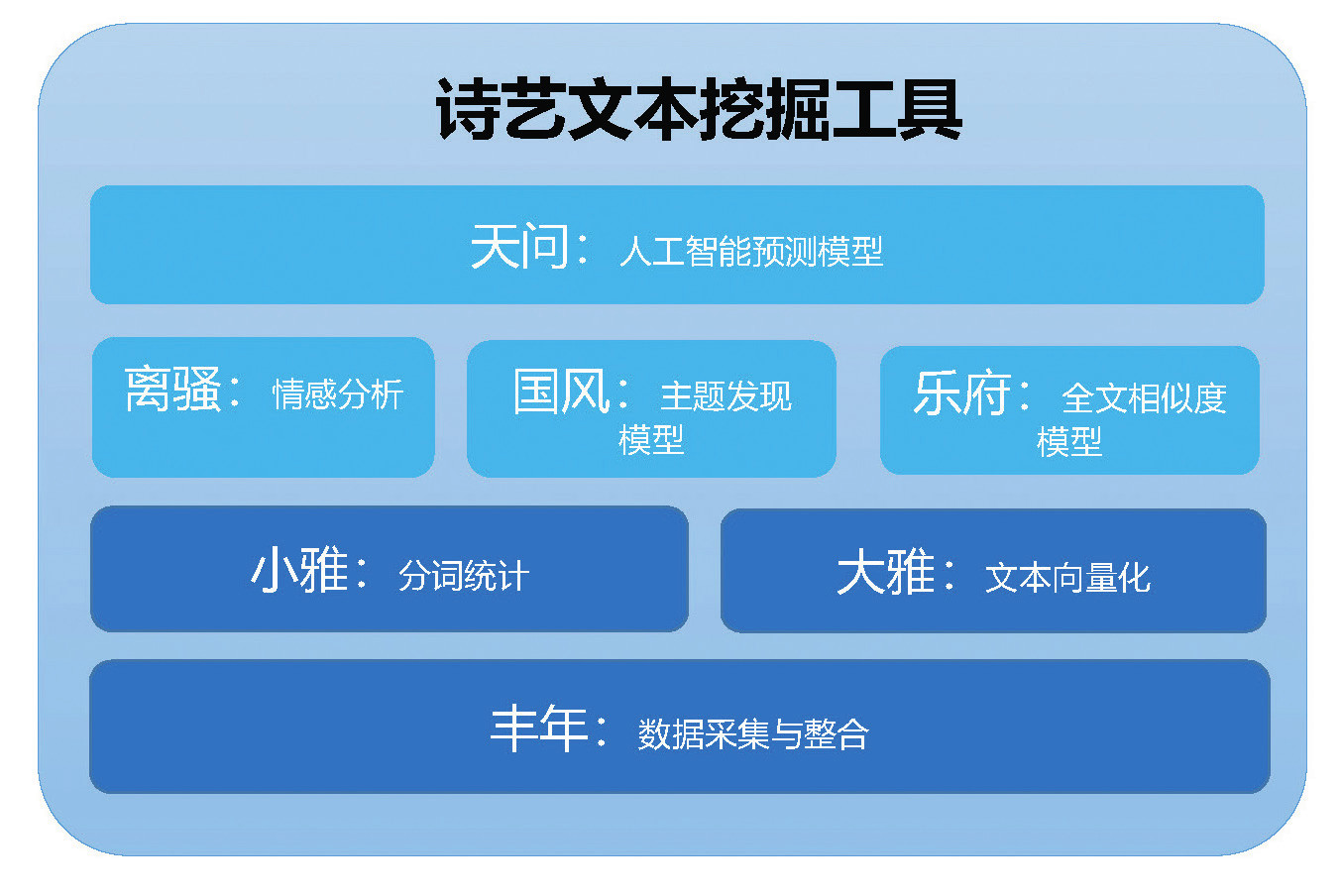
图1 “诗艺”文本挖掘工具整体设计
工具取名“诗艺”,是因为其中的模块都选取了《诗经》《楚辞》等的章节来命名。“丰年”是数据采集与整合模块,其主要功能是将非结构化和结构化数据整合在一起形成新的数据结构。“小雅”和“大雅”本来是诗经的两个基础组成部分,所以这里也用来体现文本挖掘的基础技术:分词和文本向量化。其他文本挖掘技术都是在这两项技术的基础上盖楼。“离骚”是情感分析模型,寓意源自《楚辞》中的名篇《离骚》,其中的文字都非常抒情。“国风”是主题发现模型,诗经中有十五国风,分别代表十五个诸侯国不同风格的诗歌,与主题发现模型挖掘出各种不同主题的文章类群寓意一致。“乐府”是全文相似度搜索模型,是将新的文本在原有文本库中搜索,发现相似度最高的文本。《乐府》本来是汉代的诗歌搜集库。“天问”是人工智能预测模型,能够对文本数据进行有监督算法的建模,发现未知的规律。《楚辞》中的名篇《天问》也正是要询问宇宙的起源和规律。
2.研发成果
基于以上这些模块的定位设计,经过程序开发,而后采用workflow技术来进行控件打包。控件串成的工作流示例如图2所示,各个控件用线串联起来,可拖拽,每个控件双击点开就能设置和运行。

图2 控件串成的工作流示例
3.工具特点
“诗艺”文本挖掘工具的特点主要有以下几个方面。(1)架构创新:将各种零碎的文本挖掘技术方法汇聚在一起,避免了文本挖掘工作中的分析遗漏和重复劳动,使工作规范化,流程化。(2)技术创新:可视化界面采用workflow技术实现,具备简洁、可拖拽、用户体验好的优势。(3)模式创新:把各个功能抽象出最小执行模块,对常用的分析场景以串联模块的方式制作了标准工作流模板,不需要编写任何代码即可完成分析,极大降低文本挖掘门槛,提升文本挖掘效率,快速发现业务价值。
实战应用
利用“诗艺”文本挖掘工具可以方便地做文本挖掘工作,以“客服系统的客户来电总结”为例,进行实战应用。数据来源为交行近期一个月的客服系统客户来电总结,共23万条数据。将文本数据与客户资产数据通过卡号进行关联,一共月36000条记录与客户有关联。定义标签:客户资产在来电前后,上升30%以上为“上升”,下降30%以上为“下降”,其余为“不变”,给每条来电打上标签。
1.分词统计展示
文本数据关联资产数据后,通过“丰年”模块加载,“小雅”模块进行分词,然后将分词结果进行统计和可视化展示,点击工作流中的词云统计功能会出现词云图(见图3)。看到客户询问“贷款”“发放”是与资产上升最密切的,其他的还有“用卡”“无忧”“代发”“贴金”等。

图3 与客户资产上升有关的词云
2.特征工程(文本向量化)
文本数据通过“丰年”“小雅”分词后,用“大雅”向量化模块,把文本数据转化成数值向量。采用词向量的方法,把每个词都转换成了一个数值向量,通过比较距离,任意一个词都可以发现与其相关联的词,展示关联网络见图4。与“支付”相关的词可以找到支付宝、财付通、京东,更远一点能联系到小微贷款。
3.主题发现模型
文本数据通过“丰年”“小雅”分词后,用“国风”主题模型进行主题挖掘。LDA算法得到的主题是以每个主题的top5关键词重要度排序的形式展现的。设置聚类成5个主题(见表1)。

表1 主题模型结果(PS:主题名称是根据关键词的特点人为取的)
4.文本相似搜索功能
被搜索的文档库通过“丰年”“小雅”“大雅”的流程转化成数值向量,需搜索的文档同样转化成数值向量,然后通过“乐府”搜索模块来计算文档库与自己距离最近的前N个文档得到结果。根据用户输入新的客服语音文本,来找到最相似的几个文本,以此来推测客户可能的行为。举例如表2。
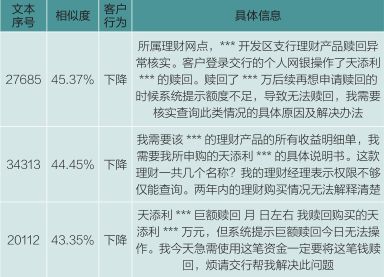
表2 问题:我买的天添利怎么不能赎回?
5.基于建模的情感分析
建情感模型时,直接以客户资产上升为正面的情感标志,客户资产下降为负面的情感标志,资产不变为中性的标志来建模。
建模过程(文本情感模型):文本在数值化后通过采样区分训练集和预测集,然后通过“天问”模块进行情感建模,得到的模型保存到“离骚”模块中。
模型使用过程:待预测情感的文本同样经过数值化,然后加载“离骚”模块中的情感模型,得带情感预测结果。
建模过程中80%数据作为训练集,20%数据作为预测集,来预测客户来电之后其资产会“上升”、“下降”、“不变”。最终得到的预测准确率为70%。
总结和展望
本文全面梳理了文本挖掘相关的各种技术,介绍了交行自主设计研发的“诗艺”文本挖掘工具,工具将各种文本挖掘的技术汇拢梳理,包括了“丰年”数据采集与整合、“小雅”分词统计、“大雅”文本向量化、“离骚”情感分析、“国风”主题发现模型、“乐府”全文相似度模型、“天问”人工智能预测模型等。并在实战应用中,以“客服系统的客户来电总结”的数据为例,采用不同的手段,从各个角度进行挖掘,流程系统化,高效地发现了有价值的信息。
之后,我们还将使用“诗艺”文本挖掘工具对其他的应用场景进行分析,如需求工单分析、授信贷审报告风险度分析等等。
诗艺”文本挖掘工具的特点也暗示了其强大的可扩展性,我们可以根据需要开发新的功能组件,也可以根据业务需求制作新的场景工作组件化流。
我们还可以将此工具与爬虫、自然语言理解NLP以及知识图谱等技术结合,形成一个完善的集文本收集、加工处理、分析挖掘、知识积累于一体的大平台。
本文节选自《金融电子化》2019年01月刊
声明:本文来自金融电子化,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
