选自arXiv
作者:Andreas Rossler 等
机器之心编译
参与:路、淑婷
人脸编辑技术的发展和广泛使用引起人们对隐私安全等的担忧,如 DeepFakes 可以实现视频换脸,且逼真程度很高,有时人类都无法分辨真伪。为此,本研究提出了一种检测人脸伪造图像的新方法以及包含来自 1000 个真实视频的 510,207 张图像和目标真值的数据集。本研究使用该数据集,采用额外的人脸区域特定领域知识,改善了人脸图像伪造检测的准确率。
现在,操纵视觉内容已经很普遍,也是数字社会中最重要的话题之一。比如,DeepFakes 展示了如何使用计算机图形学和视觉技术进行视频换脸,进而破坏别人的声誉。人脸是目前视觉内容操纵方法的主要兴趣点,这有很多原因。首先,人脸重建和追踪是计算机视觉中比较成熟的领域,而它正是这些编辑方法的基础。其次,人脸在人类沟通中起核心作用,因为人脸可以强调某个信息,甚至可以传达某个信息。目前的人脸操纵(facial manipulation)方法分为两类:面部表情操纵和面部身份操纵(见图 2)。最著名的面部表情操纵技术之一 Face2Face 来自于 Thies 等人 [48]。它可基于商用硬件,将一个人的面部表情实时迁移至另一个人。后续的研究(如《Synthesizing Obama: learning lip sync from audio》[45])能够基于音频输入序列使人脸动起来。《Bringing portraits to life》[8] 可以编辑图像中的面部表情。

图 2:人脸数字化的发展是现代人脸图像编辑工具的基础。这些编辑工具分为两类:身份修改和表情修改。除了使用 Photoshop 等工具手动编辑人脸以外,近年来出现了很多自动化方法。最著名、最广泛的身份编辑技术是换脸(face swapping)。这些技术流行的根源在于其轻量级特性,方便在手机上运行。facial reenactment 技术可以将源人脸的表情迁移到目标人脸,从而改变一个人的表情。
身份操纵是人脸伪造的第二大类。与改变表情不同,身份操纵方法将一个人的脸换到另一个人的面部。因此,这个类别又叫换脸。随着 Snapchat 等消费者级别应用的广泛使用,这类技术变得流行。DeepFakes 也可以换脸,但它使用了深度学习技术。尽管基于简单计算机图形学技术的换脸可以实时运行,但 DeepFakes 需要为每一个视频对进行训练,这非常耗时。
本研究展示了一种方法,可以自动、可靠地检测出此类人脸操纵,且性能大幅超过人类观察者。研究者利用深度学习的近期进展,即使用卷积神经网络(CNN)学习极强图像特征的能力。研究者以监督学习的方式训练了一个神经网络,可以解决人脸伪造检测的问题。为了以监督的方式学习并评估人类观察者的表现,研究者基于 Face2Face、FaceSwap 和 DeepFakes 生成了一个大规模人脸操纵数据集。
本文贡献如下:
使用特定领域知识的当前最先进人脸伪造检测技术。
新型人脸伪造图像数据集,包含来自 1000 个真实视频的 510,207 张图像和目标真值,以保证监督学习。
进行了用户调查,以评估所用人脸操纵方法的有效性,以及人类观察者在不同视频质量情况下检测伪造图像的能力。
论文:FaceForensics++: Learning to Detect Manipulated Facial Images

论文链接:https://arxiv.org/pdf/1901.08971.pdf
摘要:合成图像生成和操纵的快速发展引起人们对其社会影响的巨大担忧。这会导致人们丧失对数字内容的信任,也可能会加剧虚假信息的传播和假新闻的捏造,从而带来更大的伤害。在本文中,我们检查了当前最先进人脸图像操纵技术结果的逼真程度,以及检测它们的困难性——不管是自动检测还是人工检测。具体来说,我们聚焦于 DeepFakes、Face2Face、FaceSwap 这几种最具代表性的人脸操纵方法。我们为每种方法各创建了超过50万张操纵过的图像。由此产生的公开数据集至少比其它同类数据集大了一个数量级,它使我们能够以监督的方式训练数据驱动的伪造图像检测器。我们证明了使用额外的特定领域知识可以改善伪造检测方法,使其准确性达到前所未有的高度,即使在强压缩的情况下同样如此。通过一系列深入实验,我们量化了经典方法、新型深度学习方法和人类观察者之间的性能差异。
3 数据集
本文的核心贡献之一是 FaceForensics 数据集。这个新的大规模数据集使我们能够以监督的方式训练当前最佳的人脸图像伪造检测器。为此,我们将三种当前最先进的自动人脸操纵方法应用到 1000 个原始真实视频上(这些视频均是从网上下载的)。
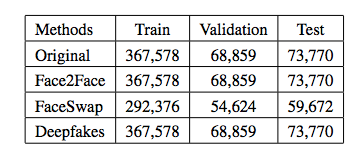
表 1:FaceForensics 数据集中每一种方法相关图像的数量,包括训练、验证和测试数据集中的图像数量。
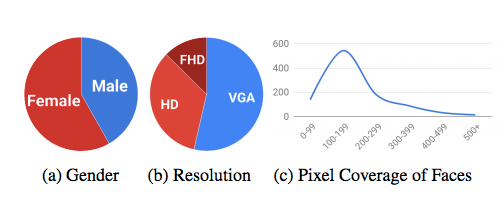
图 4:FaceForensics 数据集统计数据。VGA 表示视频分辨率为 480p,HD 表示 720p,FHD 表示 1080p。c 中 x 轴表示给定像素高度,y 轴表示序列数。
4 伪造检测
我们将伪造检测视为被操纵视频每一帧的二分类问题。下面是人工和自动伪造检测的结果。对于所有的实验,我们将数据集分成固定的训练、验证和测试集,分别包含 720、140 和 140 个视频。所有评估结果都是基于测试集中的视频报告的。
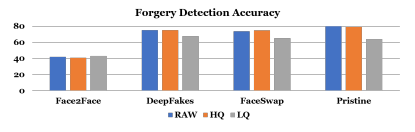
图 6:143 个参与用户的伪造检测结果。准确率取决于视频质量,视频质量差则准确率会下降。原始视频上的检测准确率为 72%,高质量视频上的准确率为 71%,低质量视频上的准确率只有 61%。
4.2 自动伪造检测方法

图 5:本文提出的特定领域伪造检测流程:先用一种稳健的人脸追踪方法处理输入图像,然后利用特定领域信息提取图像中被脸部覆盖的区域,将该区域输送至一个训练好的分类网络,最后该网络的输出即是图像真伪的最终结果。
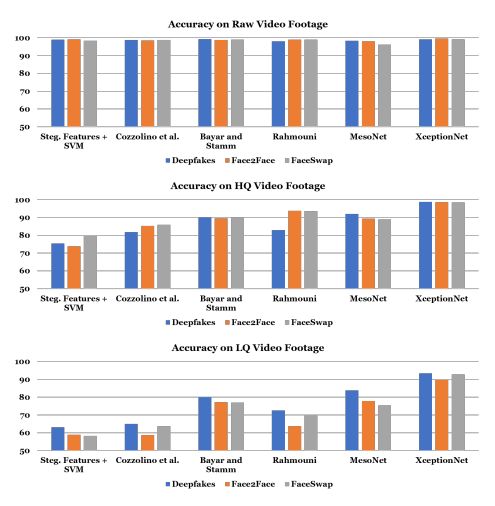
图 7:使用人脸图像伪造的特定领域信息(即人脸追踪),所有使用架构在不同操纵方法上的二分类检测准确率。这些架构在不同的操纵方法上独立训练。
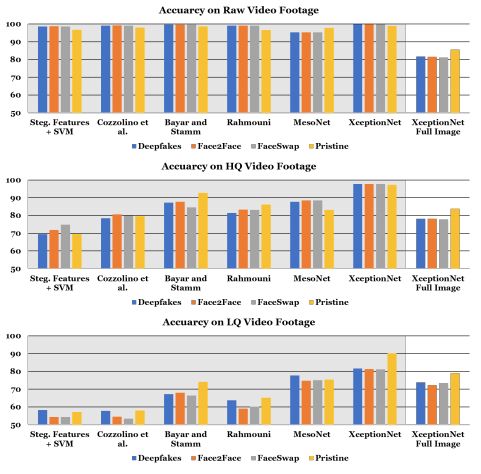
图 8:使用人脸图像伪造的特定领域信息(即人脸追踪),本文提出检测器的所有变体在不同操纵方法上的二分类检测准确率。除了最右侧分类器使用完整图像作为输入,这些架构都使用人脸追踪器的追踪信息在完整数据集上训练。
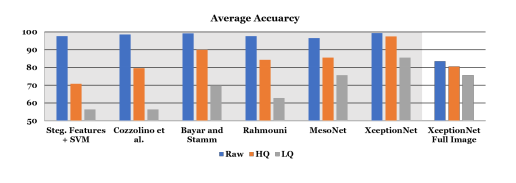
图 9:使用人脸图像伪造的特定领域信息(即人脸追踪),本文提出检测器的所有变体在不同操纵方法上的平均二分类检测准确率。除了最右侧分类器使用完整图像作为输入,这些方法都使用人脸追踪器的追踪信息在完整数据集上训练。
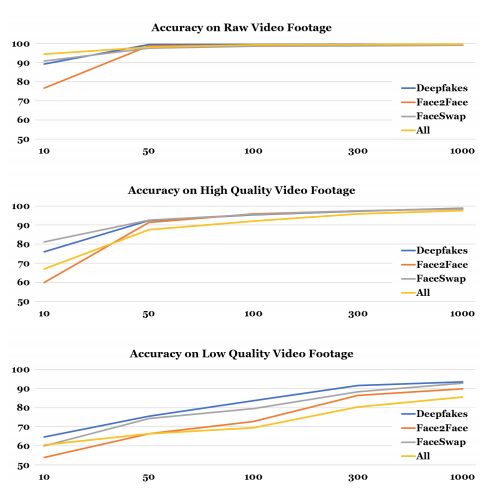
图 10:本文提出的方法使用 XceptionNet 的检测性能依赖于训练语料库的大小。尤其是,低质量视频数据需要较大型的数据集。
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
