
来源:techcrunch
编译:大明、三石、闻菲
GAN 2.0来了?!
我们知道GAN能够生成逼真的图片,但没有想到字面意义上的“逼真”会如此快到来。
下面是一组完全由计算机生成的图片,重复一遍:全部是计算机生成的图片!

这组效果惊艳到可怕的成果,出自英伟达的研究人员最近提出的一种新的生成器架构,基于风格迁移,将面部细节分离出来,由模型进行单独调整,从而大幅度超越传统GAN等模型,生成的面部图像结果简直逼真到可怕,可以说是GAN 2.0。
这种生成器架构提取的图像风格,不是笔划或颜色空间,而是图像的组成(居中,向左或向右看等)和脸部的物理特征(肤色,雀斑,头发)。
该研究的论文已经发表在Arxiv上:
https://arxiv.org/pdf/1812.04948.pdf

连Ian Goodfellow也服气!

图像逼真到可怕,能生成世界万物
有CV研究人员看过上图效果以后表示,机器学习模型非常擅长生成逼真的人脸,但这个新架构生成的人脸图像已经真实到让我再也不敢相信机器。
英伟达研究人员在论文中写道,他们提出的新架构可以完成自动学习,无监督地分离高级属性(例如在人脸上训练时的姿势和身份)以及生成图像中的随机变化,并且可以对合成进行更直观且特定于比例的控制。
换句话说,这种新的GAN在生成和混合图像,特别是人脸图像时,可以更好地感知图像之间有意义的变化,并且在各种尺度上针对这些变化做出引导。
例如,研究人员使用的旧系统可能产生两个“不同”的面部,这两个面部其实大致相同,只是一个人的耳朵被抹去了,两人的衬衫是不同的颜色。而这些并不是真正的面部特异性特征,不过系统并不知道这些是无需重点关注的变化,而当成了两个人来处理。

在上面的动图中,其实面部已经完全变了,但“源”和“样式”的明显标记显然都得到了保留,例如最底下一排图片的蓝色衬衫。为什么会这样?请注意,所有这些都是完全可变的,这里说的变量不仅仅是A + B = C,而且A和B的所有方面都可以存在/不存在,具体取决于设置的调整方式。
下面这些由计算机生成的图像都不是真人。但如果我告诉你这些图像是真人的照片,你可能也不会怀疑:

这个模型并不完美,但确实有效,而且不仅仅可用于人类,还能用于汽车、猫、风景图像的生成。
所有这些类型的图像都或多或少可以单独隔离出来,再现小型、中型和大型特征的相同范例。
基于风格的生成器架构:生成图像效果质的飞跃
英伟达研究人员介绍,新的生成器在传统的分布质量指标方面改进了最先进的技术,使得插值特性明显变好,并且更好地解决了变量隐因子问题。
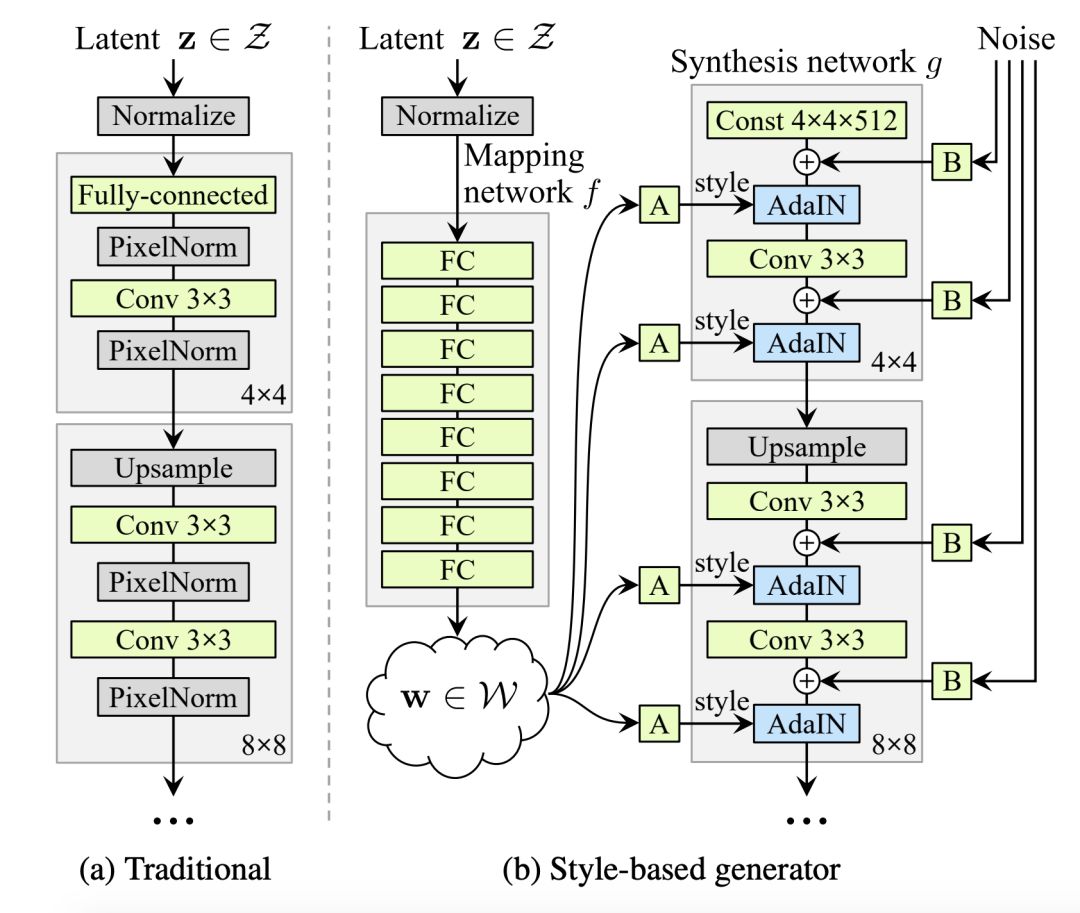
传统生成器架构和基于风格的生成器架构对比
传统方式中,隐码(latent code)是通过输入层提供给生成器的,即前馈网络的第一层(图1a)。而英伟达团队完全省略了输入层,从一个学习的常量(learned constant)开始,从而脱离了传统的设计(图1b,右)。在输入隐空间Z中,给定一个隐码z,一个非线性网络 f:Z→W首先生成w∈W(图1b,左)。
英伟达团队的发生器架构可以通过对样式进行特定尺度的修改来控制图像合成。可以将映射网络和仿射变换看作是一种从学习分布(learned distribution)中为每种样式绘制样本的方法,而将合成网络看作是一种基于样式集合生成新图像的方法。修改样式的特定子集可能只会影响图像的某些方面。
样式混合
英伟达团队采用混合正则化,其中给定比例的图像是使用两个随机隐码生成的,而不是一个在训练期间生成给定百分比的图像。
在生成这样的图像时,只需在合成网络中随机选择的一个点上,从一个隐码切换到另一个——称之为样式混合的操作。
表2显示了在训练过程中启用混合正则化是如何产生显著改进的,在测试时混合了多个延迟的场景中,改进的FID表明了这一点。

表2
图3给出了在不同尺度上混合两个潜码合成图像的例子。可以看到,样式的每个子集控制图像的高级属性。

图3
随机变化
人类肖像中有许多方面可以被视为随机的,例如毛发,雀斑或皮肤毛孔的确切位置。只要它们遵循正确的分布,任何这些属性都可以随机化而不影响对图像的感知。
图4显示了相同底层图像的随机实现,这些图像是使用具有不同噪声实现的生成器生成的。

图4
可以看到,噪声只影响随机属性,使整体组成和身份等高级属性保持不变。
图5进一步说明了将随机变化应用于不同子层的效果。

图5
整体效应与随机性的分离
在基于样式的生成器中,样式会影响整个图像,因为完整的特征图像会被缩放并带有相同的值。
因此,可以相干地控制姿态、灯光或背景风格等全局效果。同时,噪声被独立地添加到每个像素上,因此非常适合于控制随机变化。
如果网络试图控制例如使用噪声的摆姿,这将导致空间不一致的决定,然后将受到鉴别器的“惩罚”。因此,网络学会了在没有明确指导的情况下,适当地使用全局和本地通道(channel)。
两种自动化方法,任何生成器都能升级
为了量化插值质量和分离,英伟达提出了两种新的自动化方法,适用于任何生成器体系架构。
研究人员还发布了一个新的面部图像数据集:数据收集自Flickr上的7万张面部图像,数据已经对齐和裁剪。研究人员使用亚马逊Mechanical Turk来清除雕像、绘画和其他异常图像。
鉴于目前此类项目所使用的标准数据集主要是名人走红毯的照片,本数据集应该能够提供变化更丰富的面部图像组合。
这些数据集不久后即将开放下载。
GAN 2.0已经如此,GAN 3.0将会如何?
使用基于风格的生成器的GAN,在各个方面都优于传统的GAN,可以说是 GAN 2.0。
英伟达团队相信,对高阶属性与随机效应分离的研究,以及中间隐空间( intermediate latent space)的线性,将会对提高GAN合成的理解和可控性有很大的帮助。
可以注意到,平均路径长度度量可以很容易地用作训练中的正则化器,也许线性可分度量的某些变体也可以作为一个正则化器。
除了人像,GAN 2.0还可以生成房间、汽车等各种场景。有了这个利器,以后何愁图像数据集?
看着这些计算机生成的“人”,是如此的真实但又虚拟。爱上一个不存在的人,似乎完全合情合理。
总的来说,在训练期间直接塑造中间隐空间( intermediate latent space)的方法将为未来的工作提供有趣的途径。
所以,期待一下全新的判别器架构,届时得到的GAN 3.0,会如何冲击我们的视觉和认知呢?
参考链接:
https://techcrunch.com/2018/12/13/these-face-generating-systems-are-getting-rather-too-creepily-good-for-my-liking/
https://arxiv.org/pdf/1812.04948.pdf
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
