
来源:arxiv 编辑:文强,大明
新年大手笔的不止是腾讯,谷歌近日宣布,他们实现了全球首个产品级的超大规模移动端分布式机器学习系统,目前已经能够在数千万部手机上运行。
DeepMind研究科学家Andrew Trask (他并未参与这项工作) 激动地在Twitter上说,这是2019年“年度最激动人心的论文之一”。
“谷歌公布了他们如何在数千万台手机上实现可扩展的联合学习,数据安全隐私终于成真,而谷歌是这方面的领跑者!”

Andrew Trask说的,是谷歌日前在arxiv贴出的论文,“Towards Federated Learning at Scale:System Design”,论文描述了前面所说的全球首个产品级可扩展的联合学习系统,以及该系统的高级设计和一些挑战及其解决方案。

联合学习(FL)是一种分布式机器学习方法,可以对保存在移动电话等设备上的大量分散数据进行训练,是“将代码引入数据,而不是将数据引入代码”的更加通用化的一个实现,并解决了关于隐私、所有权和数据位置等基本问题。
作者在论文中写道,“据我们所知,我们描述的系统是第一个产品级 (production-level) 的联合学习实现,主要侧重于在移动电话上运行的联合平均算法 (Federated Averaging algorithm)。
“我们的目标是将我们的系统从联合学习推广到联合计算,联合计算将遵循本文所述的相同基本原则,但不限于使用TensorFlow进行机器学习计算,而是通用的类似MapReduce的工作负载。
“我们看到的一个应用领域是联合分析(Federated Analytics),它能让我们监控大规模集群设备的统计数据,而无需将原始设备数据记录到云中。”
谷歌不愧是谷歌,先不说这一技术本身的难度和实现难度,由此带来的对智能云计算产业的冲击,也可想而知!
谷歌提出“联合学习”,实现可扩展的移动端分布式机器学习
2017年1月,统计机器学习先驱 Michael I. Jordan 在清华演讲时指出,我们需要更好更大的发布式机器学习系统。
Jordan教授表示,在计算机科学中,数据点数量的增长是“复杂性”的来源,必须通过算法或者硬件来训练,而在统计学中,数据点数量的增长是“简单性”的来源,它能让推理在总体上变得更强大,引出渐进式的结果。
“在形式层上,核心的统计学理论中缺乏计算机理论中的概念,比如‘runtime’的作用,而在核心的计算理论中又缺乏统计学概念,比如‘risk’的作用。二者之间的差异(Gap) 显而易见。”Jordan教授说。
2017年4月,谷歌在官方博客中发文,介绍了他们提出的联合学习(federated learning)。联合学习也是一种机器学习,能够让用户通过移动设备交互来训练模型。
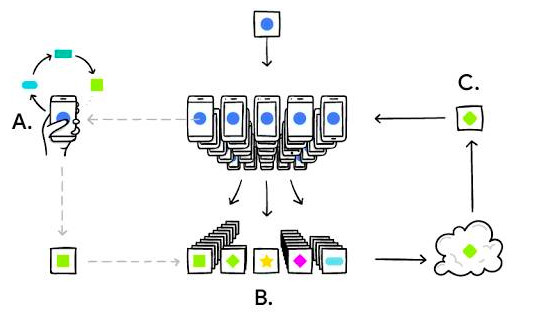
联合学习能产生更智能的模型,更低的延时和更少的功耗,同时确保用户的隐私。过程示意:(A)手机在本地根据你使用手机的方式将模型个性化,(B)许多用户的更新会集中起来,(C)在云端形成针对一个共享模型的协同更新,然后不断重复这个过程。来源:Google Blog
根据谷歌官博介绍,用户的设备会下载一个当前模型,这个模型会从手机数据中学习不断得到改善,然后将变化总结为一个小的关键更新。只有这个关键更新会以加密的方式被传到云端,之后这一更新会在云端迅速被其他用户对共享模型提交的更新平均化(averaged)。
简单说,所有的训练数据都留在用户的设备上,而且上传到云端的个别更新也不会存储到云端。谷歌研究人员表示,新方法将机器学习与云端存储数据的需求脱钩,让模型更聪明、延迟更低、更节能,而且保护用户隐私不受威胁。
这一方法还有一个间接好处:除了实现共享模型的更新,用户还能立刻使用改善后的模型,根据个人使用手机方式的不同,得到的体验也会不同。

联合学习仅当用户设备处于闲置或充电状态,并且使用无线网路的时候才发生,对用户在移动端的使用体验不会造成负面影响。来源:Google Blog
谷歌的研究人员开发了一个成熟的技术堆栈,确保联合学习训练仅当用户设备处于闲置或充电状态,并且使用无线网路的时候才发生。因此,具体的训练对手机用户体验基本没有什么影响。
当时,谷歌研究人员表示,他们正在安卓的谷歌键盘Gboard上测试联合学习。例如,当键盘给出一个建议问询时,手机就会在本地存储相关信息,比如当前的文本,以及你是否点击了相关建议。
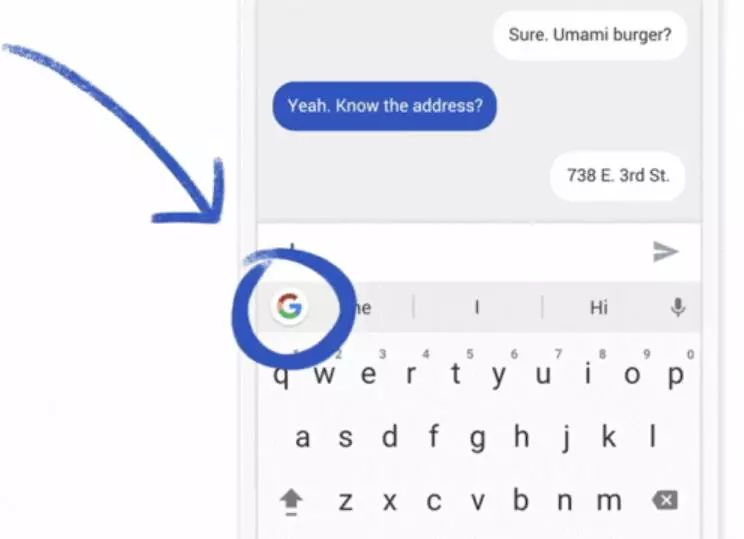
联合学习会在设备上处理这一过程,并对键盘问询建议的迭代提出改善建议。来源:Google Blog采用同步训练算法,在数千万台手机上实现模型训练和更新
现在,两年过去,谷歌已经实现了首个产品级的联合学习系统,并发布论文描述了这一系统的高级设计理念和现存挑战。
像刚刚提到的安卓手机谷歌键盘查询建议,也已经实现了大规模应用。
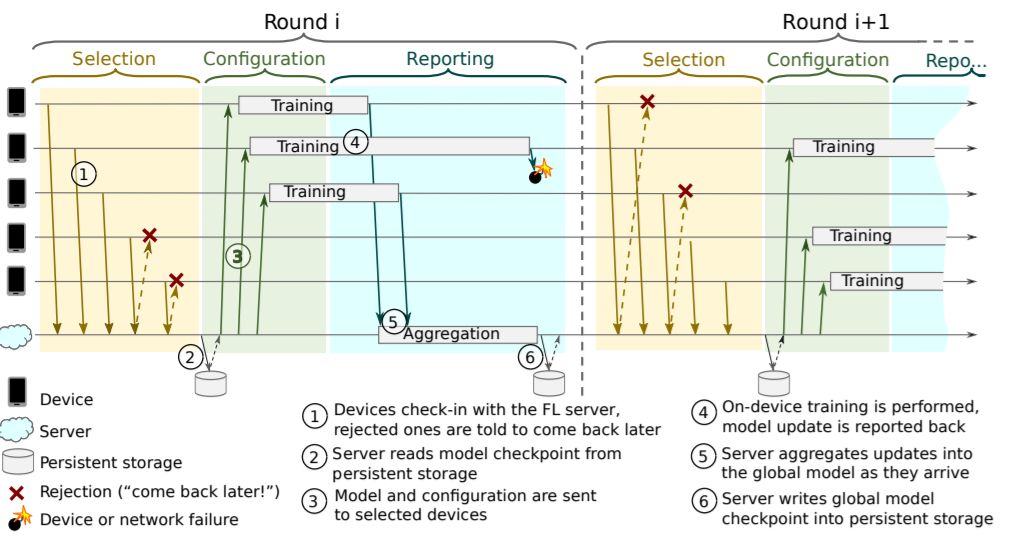
图1:联合学习流程
谷歌研究人员在论文中写道,联合学习基础架构的基本设计决策的关键问题,是重点关注异步还是同步训练算法。虽然之前很多关于深度学习的成果都采用了异步训练方式,但最近出现了采用大批量同步训练的趋势。
再考虑到能够增强联合学习中保护隐私的方法,包括差异化隐私策略(McMahan等,2018)和安全聚合(Bonawitz等,2017),这些方法基本上需要一些固定设备上的同步后的概念,让学习算法的服务器端可以仅消耗来自众多用户的更新信息的简单聚合。
因此,谷歌研究人员选择采用同步训练方式。“我们的系统可以运行大批量SGD式算法和联合平均算法,这是我们在生产中运行的主要算法”,算法的伪代码如下:

论文描述的系统使用TensorFlow训练深度神经网络,对存储在手机上的数据进行训练。用联合平均算法对训练数据权重在云中相结合,构建一个全局模型,推送回手机上运行推理过程。安全聚合的实现能够确保在全球范围内,来自电话的个人更新是无法被窥视的。该系统已推向大规模应用,比如手机键盘上。
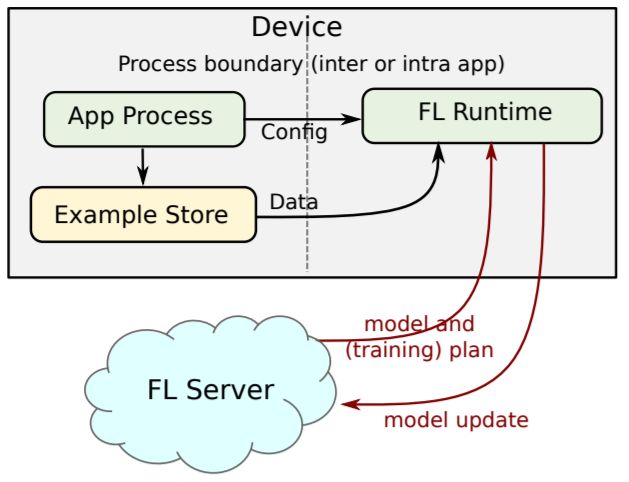
图2:设备架构
解决多个实际问题,预计未来设备应用数量达数十亿规模
谷歌研究人员表示,他们的方法解决了许多实际问题:即以复杂方式(如时区依赖性)解决了与本地数据分布相关的设备的可用性问题,应对不可靠的设备连接和执行中断问题,在可用性存在差异的设备上对lock-step执行的编排问题,以及设备存储空间和计算资源受限等问题。
这些问题在通信协议、设备和服务器级别都能得到解决。
“我们的研究已经足够成熟,可以将系统部署到生产环境中,并解决数千万个真实设备的应用学习问题;我们预计未来的设备应用数量将达到数十亿的规模。”

图3:联合学习服务器架构中的构成要素
联合学习方法在设备上的数据比服务器上存在的数据(比如设备首先生成数据)相关性更高、对隐私更敏感,或者不希望或不可能将数据传输到服务器的情况下是最佳的应用场景。联合学习的目前多用于监督学习任务,通常利用的是从用户活动中推断出的标签(比如点击操作或键入的单词等)。
设备上项目排名
移动应用程序中机器学习的一个常见用途,是从设备上的库存中选择和排序项目。例如,应用程序可以公开用于信息检索或应用内导航的搜索机制,例如在Google Pixel设备上的搜索设置(ai.google,2018)。在设备上对搜索结果进行排序,可以免去对服务器的成本高昂的呼叫(原因可能是延迟、带宽限制或高功耗),而且,关于搜索查询和用户选择的任何潜在的隐私信息仍然保留在设备上。每个用户与排名特征的交互可以作为标记数据点,可以在完整排序的项目列表中观察用户与其优先选项的交互信息。
移动设备键盘输入内容建议
可以通过为用户输入的相关内容提供建议(比如与输入文本相关的搜索查询)来提升对用户的价值。联合学习可用于训练机器学习模型来触发建议功能,并对可在当前上下文中建议的项目进行排名。谷歌的Gboard移动键盘团队就在使用我们的联合学习系统,并采用了这种方法。
下一词预测
Gboard还使用我们的联合学习平台训练递归神经网络(RNN)用于下一词预测。该模型具有约140万个参数,在经过5天的训练后,处理了来自150万用户的6亿个句子后,在3000轮联合学习后实现收敛(每轮大约需要2-3分钟)。该模型将基线n-gram模型最高召回率从13.0%提高到16.4%,并且其性能与经过1.2亿步服务器训练的RNN的性能相当。在实时对比实验中,联合学习模型的性能优于n-gram和服务器训练的RNN模型。
结语
在论文中,谷歌研究人员详细展示了在安卓手机上对此类算法的系统设计。
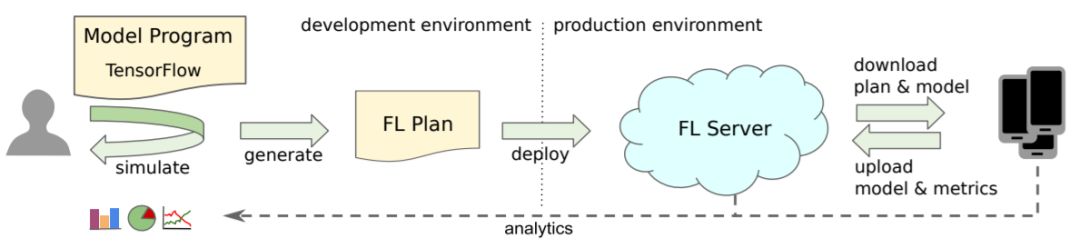
图4:建模工程师的工作流程
同时,他们也指出,“这项研究目前仍处于早期阶段,我们没有解决所有问题,也无法全面讨论所有必需的组件。
“我们在本文中要做的是,描述系统的主要组成部分以及面临的挑战,确定哪些问题没有解决,希望这些工作能够对更进一步的系统研究有所启发。”
论文链接:https://arxiv.org/pdf/1902.01046.pdf
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
