来源:Medium
编辑:小智
最近京东金融App被发现私自上传用户的银行app截图,被迫公开致歉。
京东app获取用户的资产信息的目的之一,是想针对特定用户进行定制化的推荐。只不过这样的做法涉嫌侵犯用户隐私,存在极大的安全隐患。
通常来讲,像京东、淘宝、亚马逊、Netflix这样的电商公司,都需要掌握一定的用户隐私信息,从而能够让推荐系统做到投用户之所好。
早期简单的推荐系统,比如亚马逊、京东等,会根据用户购买的历史,推荐拥有类似标签的商品。
然而对于消费者来说,除非是需要重复购买的耗材类产品,否则很少会再去购买功能相似的商品,这样的推荐系统显然是远远不能满足购物需求的。
协同过滤是迄今为止最成功的推荐算法之一,广泛应用于电子商务、社交网络、影音阅读等涉及到信息检索的领域。
使用协同过滤将用户喜好抽象成数学问题
将个性化推荐抽象成一个逻辑清晰的数学问题,而不需要涉及到变幻莫测的心理学,极大的降低了推荐系统的设计成本,提高了鲁棒性。
协同过滤的原理,首先是找出和你喜好、订单等有交集的其他用户。比如你们的订单中,有80%以上的商品重合率,阅读过的书籍中有10本都标记了喜欢等等。
通过多个维度把用户进行分类,就可以使用同类的群体用户的数据,针对单个用户进行推荐。
协同过滤算法分为两类,基于用户(User-based)的协同过滤,和基于邻居的协同过滤(Neighbor-based Collaborative Filtering)。前者是人以类聚,后者是物以群分。
由此可见,协同过滤算法严重依赖两个因素:大量的有关用户喜好的历史数据,以及大量的单一产品的评价数据。
总之,数据越丰富,推荐越精准。但这对小样本数是非常不友好的,在冷启动的时候(比如新用户完全没有产生任何历史数据),该如何构建推荐系统呢?
常见的解决方案涉及分析元数据,或给新用户通过几个问题来了解他们的初始偏好。
协同过滤算法的实现方式
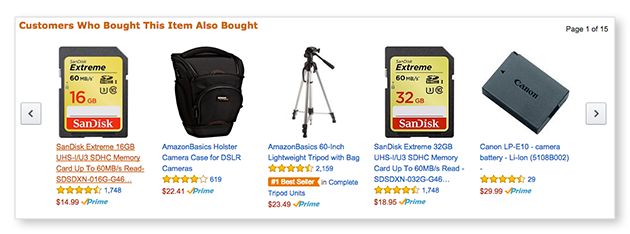
我们使用电影评分作为示例。根据用户对电影的分数构建一个用户表来对其进行可视化:

上表中,每行代表一个用户,每列代表一部电影。交叉引用揭示用户和电影评分之间的对应关系(满分为5分,0分表示“未观看”)。
我们的目标是预测出是否应该向没看过该电影、对应评分为0的用户,推荐这部电影。对应到表中,这个问题就转化为“预测用户会给电影打几分”。
在具体实现中,就是给分数为0的表格填上分数,这个分数就是预测的用户评分。如果分数高,就向用户推荐;不高就不推荐。
接下来我们设2个嵌入矩阵:用户矩阵W_u,和电影矩阵W_m。每个矩阵将用e维向量填充,e是数组的大小。
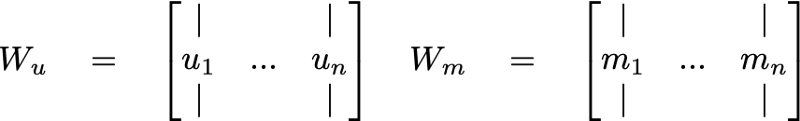
我们在两个矩阵中,使用完全随机数,得到两个随机的矩阵。两者相乘得到第三个完全随机的矩阵。
将这个矩阵和原始表进行对比,从而找到一个损失函数。这基本上是衡量预测评级与实际评级相差多远的指标。接着使用反向传播和梯度下降来优化两个矩阵以获得正确的值。
为什么可以通过冰冷的数学预测出我们的喜好?
上述构建的矩阵基本上是矢量堆栈。每个用户一个向量,每个电影一个向量。
每个向量表示对应的用户是什么类型的人。它将用户的喜好、想法和感受,联通希望和恐惧,封装成一个毫无情感的numpy.array[]数组。
为了更好地理解这一点,让我们放大一个特定的用户向量,假设e = 3:
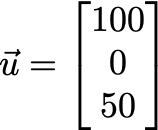
这里,矢量的三个分量是[100, 0, 50] 。 每个组件代表用户的一些特征,机器通过查看ta之前的评级来学习。
假设这三个组件具有以下含义:

我们可以解读出,这个用户显然喜欢动作片,对浪漫电影不是很喜欢,也喜欢喜剧电影,但不像动作电影那么多。
这就是机器学习模型理解人类的复杂性的方式:将其嵌入到e维向量空间中,然后相乘。
e越大,捕获的用户数据就越多,计算所花费时间也就越长。
接着我们就可以再来使用基于邻居的算法,找出电影的属性,再去和用户喜好对比。
假设我们有一部电影m,它的矩阵是这样

解释成人话就是
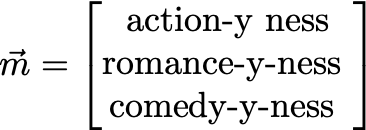
所以m应该是一部浪漫喜剧电影,用户u可能就不会喜欢。
算法之美,人性之美
协同过滤将我们人类的情感感念,喜欢、讨厌、恐惧、激动等等,全部转化成一个个的毫无波澜的矢量矩阵。
两个矩阵只是简单的相乘,就能预测一个人的喜好,简直不可思议!在不知道的地方,我们都是同一线性向量空间的元素。
那个地方,有美。
查看英文原版:https://medium.freecodecamp.org/how-companies-use-collaborative-filtering-to-learn-exactly-what-you-want-a3fc58e22ad9
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
