尹萍 赵亚丽
我国平安城市建设发展迅速,利用众多的视频监控摄像头快速、准确获取场景中的人像信息对安防和公安刑侦业务十分重要。到十三五初期,我国已初步建成覆盖主要大中小城市的视频监控网。据统计,我国城镇视频监控镜头已经超过2500万个。利用视频监控进行人脸识别和行人身份识别,越来越受到公安部门的重视。
随着摄像头网络规模和数量不断增加,所监控区域的环境越来越多样,人工分析视频图像因其效率低下、需要耗用大量人力资源而越来越跟不上当前公安业务发展的需求。一方面,尽管基于人工智能技术的人脸识别在交通卡口和摄像头角度适合的情况下能够正常工作,但是多数监控中的人脸因图像质量不满足要求而无法进行识别;另一方面,利用视频监控进行案件侦破时,多数场合只能看清行人的身体部分,需要进行跨视域的连续跟踪查找。
行人再识别指的是对于某个摄像头中出现的一个行人,识别其是否在其它摄像头中再次出现。基于行人再识别的连续跟踪,有可能在某个摄像头下能够获取到可以进行自动人脸识别的图像。行人再识别是当前计算机视觉和模式识别领域中的前沿课题,对公安刑侦和安防监控具有非常重要的应用价值。近年来,虽然单个摄像头视频序列分析技术已经取得了长足的进步,其中部分已经取得了实际的应用,但是,单个摄像头无法覆盖到更广大的区域,因此分析一个地区的视频信息需要综合多个摄像头的视频序列。跨视域指各摄像头位于不同的位置和视角,其视域互不重叠,如图1所示。为解决摄像头网络下的广域行人分析,就必须首先解决跨视域多摄像头下行人再识别这一关键技术课题。近年来,跨视域多摄像头下行人再识别方法受到了相关领域科研人员越来越多的关注,同时也受到政府和公安部门越来越多的重视。
行人再识别是多摄像头视频监控系统中至关重要的一环,是一种基于视觉外观信息的目标识别方法。近年来众多的研究工作开始转向跨视域多摄像头下的行人再识别问题。这里隐含地假设行人图像是在相近的时间段内被拍摄到的,其衣服或体型没有太大的变化。
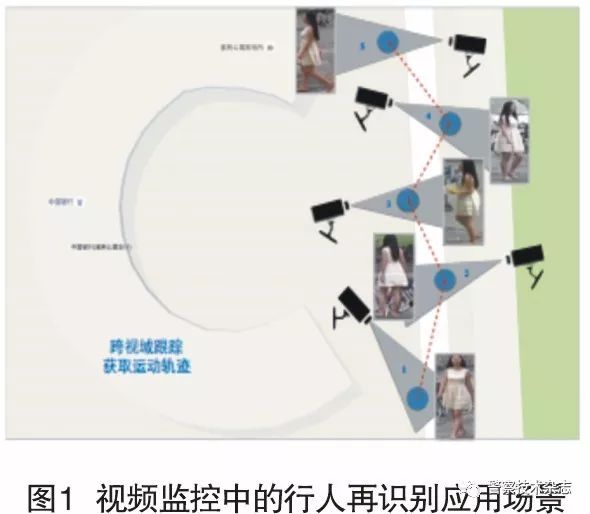
一、视频监控中的行人再识别
行人再识别的研究开始于多摄像头跟踪。在早期,行人再识别常常与多摄像头跟踪联系在一起,其行人外观模型往往与跨视域多摄像头校准集成在一起。Huang和Russell提出了一种贝叶斯公式,在给定其他摄像头视域下观察到的样本下,该方法可以估计在一个摄像头中预测物体外观的后验概率。据本文所知,第一篇使用术语“行人再识别”的多摄像头跟踪工作来自于Zajedel等人发表的题为“Keeping Track of Humans: Have I Seen this Person Before?”的论文,其旨在重新识别离开视野后并重新进入视野时的一个人。该方法为每个行人假定了一个唯一的身份标签,并定义动态贝叶斯网络以对来自跟踪序列的标签和特征之间的概率关系进行编码,而进入视野的行人的身份由近似贝叶斯推理算法计算的后验身份标签分布决定。之后,Gheissari等人在时空分割算法之后仅使用行人的视觉外观特征用于前景检测,其基于颜色和显著性格林直方图的视觉匹配算法使用了一个链式行人模型或Hessian-Affine兴趣点运算符,其实验数据集包括了44个行人,由中度视域重叠的3个摄像头捕获。这项工作标志着行人再识别领域与多摄像头跟踪领域的研究分离,而此后行人再识别开始成为一个独立的计算机视觉任务。
行人再识别主要研究使用视觉特征来匹配行人目标。良好的行人再识别方法可以在多摄像头跟踪子系统中与摄像头网络拓扑推导的时空推理信息相结合,进一步筛选所需匹配的行人候选集。行人再识别是非常具有挑战性的,因为同一个人在不同摄像头视域下捕获到的行人图像常常有着分辨率、亮度、姿态和视角等的显著变化。由于监控摄像头拍摄到的尺寸通常较小,因此大量的视觉细节(如人脸)在图像中是模糊不可区分的,而一些行人图像在外观上看起来又比较相似。因此,用于匹配图像的描述子和距离度量需要对这些摄像头之间的变化具有高度的鉴别力和鲁棒性。从技术上讲,行人再识别子系统又可以分为两个模块,即行人检测和行人检索,因为通常把行人检测模块作为单独的计算机视觉任务,所以大多数行人再识别的工作集中于行人检索模块。从计算机视觉的角度来看,行人再识别中最具挑战性的问题是如何在剧烈地外观变化下(例如照明、姿势和视域等)正确地匹配同一个人的两张行人图像,而这具有重要的应用价值。另外,不同的摄像头视域之间通常存在非常大的视角、照明条件和摄像头设置的变化,这样就给基于外观的跨视域多摄像头下人像匹配带来了巨大的挑战。
二、技术现状
行人再识别由于受到不同摄像头所处的角度、光照等环境的影响,会导致尺度、光照和角度的变化,同一个行人在不同摄像头中的图像中,表观会有一定程度的变化,有时不同行人的特征可能比同一个人的外貌特征更相似,这是难点所在。针对这些问题,行人再识别领域的研究工作主要采用研究行人对象的特征表示方法,提取更具有鲁棒性的鉴别特征对行人进行表示,以及采用距离度量学习方法,通过学习一个有判别力的距离度量函数,使得同一个人的图像间距离小于不同行人图像间的距离。有的研究者也开始尝试采用深度学习的方法,通过深度神经网络提取行人的图像特征。
基于图像的行人再识别技术,其核心目标是为一张指定的行人图像找到包含N张行人图像的候选集中与之最相似的行人图像。为了将不同身份的行人区别出来,行人再识别需要提取有鉴别力的行人特征描述子。在日常生活中,人类通常根据服饰识别是否是同一个行人,而在智能多摄像头监控系统中,行人外观通常由于照明、行走姿势、摄像头视域的变化而剧烈变化。如何在剧烈的外观变化下提取鲁棒的描述子,是一个非常具有挑战性的问题。颜色是在行人描述子中最常用的鉴别性特征,同时,加入纹理特征。基本方法是将行人前景从背景中分割出来,并为每个身体和身体部件计算一个对称轴。基于身体不同部分计算加权颜色直方图(Weighted Color Histogram,简称为WH)其中,WH 为对称轴附近的像素分配较大的权重,并为每个身体部件生成一个颜色直方图;MSCR检测稳定的颜色区域,并提取颜色、面积和质心等特征;Gray和Tao在亮度通道上使用8个颜色通道(RGB、HS和YCbCr)和21个纹理滤波器,并且将行人图像划为水平条。许多后来的工作采用与该方法相同的特征集[6-8]。近几年来,手工设计的行人描述子与上述早期工作相比或多或少保持了相似的设计思路。主要将行人图像划分为以5个像素为步长密集采样的10×10区块,从每个区块中提取32维LAB颜色直方图和128维SIFT描述子,接着使用邻接约束搜索从候选集图像中查找与查询图像区块具有相同高度的最佳匹配水平条。
除了直接使用底层颜色和纹理特征之外,另一类方法是基于属性的特征,属性特征可以被视为中间层表示。人们认为与底层描述子相比,属性特征对于图像变换更加鲁棒。例如,有的研究者在VIPeR数据集上标注与服饰和软生物特征相关的15个二进制属性,接着底层颜色和纹理特征被用于训练属性分类器,一些最近的工作借用外部数据进行属性学习。Su等人将同一个行人在不同摄像头下的二进制语义属性嵌入到连续的底层属性空间中,使得属性向量对于匹配更具鉴别力。Shi等人提出从现有的时装摄影数据集学习一些属性,其中包括颜色、纹理和类别标签,这些属性直接用于行人再识别,得到了较好的结果。
三、常用数据集
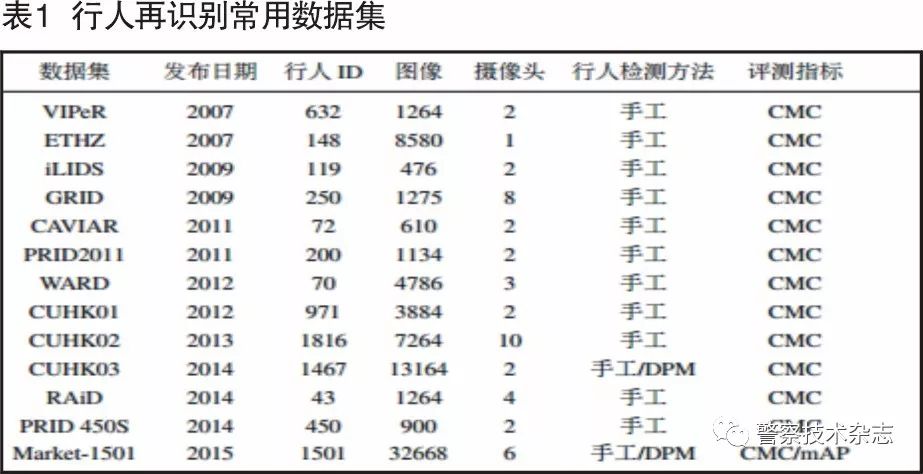
表1总结了目前行人再识别常用的一些数据集。这些数据集反映了各种场景,例如,GRID数据集收集于地下车站,iLIDS收集于机场到达大厅,CUHK01,CUHK02,CUHK03和Market-1501收集于大学校园。本文重点介绍下列几个数据集。
1. VIPeR数据集
VIPeR数据集是目前最广泛采用的基准测试数据集,它总共包含1264张图像,从户外环境的两个不同的摄像头中捕获。该数据集包括632个行人,每个行人有两张图像。VIPeR广泛用于评估行人识别外观模型,并且非常具有挑战性,因为其行人图像在视域、姿态、分辨率和光照方面的变化很大。在此数据集中,所有图像均归一化为128×48的像素分辨率。一般的评测方法如下,将该数据集随机分为2个数量相等的部分,一个用于训练,另一个用于测试。在一次试验中,一个摄像头中的图像依次作为查询图像和另一个摄像头上的候选集图像做匹配,如此重复10次试验并计算平均结果作为最终结果。VIPeR数据集中的一些示例图像如图2所示。

2. ETHZ数据集
ETHZ数据集包括从移动摄像头捕获的三个视频序列,并且随着行人外观、摄像头分辨率、照明和重度遮挡的一系列变化而变化。该数据集结构如下:SEQ.#1包含83个行人(4857张图像);SEQ.#2包含35个行人(1936张图像);SEQ.#3包含28个行人(1762张图像)。在原始ETHZ数据集中,图像样本被归一化为64×32的像素分辨率。一般的评测方法也包括10次随机试验,每一次试验为每个行人选择一张图像构成候选集,剩下的则是查询图像。10次试验得到的平均结果作为最终结果。
3. PRID 450S数据集
PRID 450S数据集从两个不相交的监控摄像头上总共捕获450对行人图像对。行人检测矩形框是手动标记的,原始图像分辨率为720×576像素。此外,该数据集还提供了以下区域的行人部件分割:头部、躯干、腿部、躯干处携带的物体(如果有的话)和躯干下方携带的物体(如果有的话)。类似于VIPeR,一般的评测方法将该数据集随机分为两个数量相等的部分,一个用于训练,另一个用于测试,并重复10次试验取结果的平均值。PRID450S数据集中的一些示例图像如图3所示。

4. Market-1501数据集
不同于上述三个小规模数据集,Market-1501数据集是一个大规模数据集,由清华大学研究团队构建并公开。它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的1501个行人、32668个检测到的行人矩形框。每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。另外值得一提的是,3368张查询图像的行人检测矩形框是人工绘制的,而候选集图像中的行人检测矩形框则是使用DPM检测器检测得到的。该数据集提供的固定数量的训练集和测试集均可以在单查询或多查询测试设置下使用。Market-1501数据集中的一些示例图像如图4所示。

由表1中可以看到近年来公开数据集的一些趋势:首先数据集规模越来越大。早期数据集的规模一般较小,而最近的一些诸如CUHK03数据集和Market-1501数据集,其数据规模较大,两者都有超过1000个行人身份ID和超过10000个行人矩形框,这两个数据集提供了大量的数据可用于训练深度学习模型;第二,近期数据集的行人检测矩形框开始采用诸如DPM行人检测器自动生成,而非以往那样由手工标注而成。在实际应用中,人力手工绘制候选集图像的行人矩形框往往是不可行的,而必须使用行人检测器,这可能导致检测得到的行人边界框偏离理想的位置。Li等人指出由于行人检测器错误(例如未对准),用检测器生成的矩形框与手工标注的矩形框相比通常再识别准确率会更低。采用行人检测器时不可避免会在行人候选集中加入许多误检结果。由于更多的干扰物被添加到候选集中,将导致行人再识别准确率下降。因此,研究具有诸如误检和未校准的实际缺陷的数据集是非常有益的;第三,近年来数据集使用了更多的摄像头,比如Market-1501中的每个行人最多可由6个摄像头拍摄到。这就要求度量学习方法具有良好的泛化能力,而非仅仅在某对摄像头之间仔细地调优。
四、评测指标
评估行人再识别算法时,通常使用累计匹配特性(CumulativeMatching Haracteristics,简称为CMC)曲线。CMC表示查询ID出现在候选列表中的排名位置的累积概率。无论在候选集中有多少真实匹配,只有排名最高的匹配计入CMC计算。因此,基本上只有当每个查询仅存在一个真实匹配时,CMC才是准确的评估方法。而在实践中,人们更多地关注在列表的顶部位置返回的真实匹配,因此该评估方法是可行的。
然而为了研究的完整性,当候选集中存在多个真实匹配时,研究者提出使用平均正确率均值(mean Average Precision,简称为mAP)进行评估。采用mAP的动机是一个完美的行人再识别系统应该能为一个查询图像返回候选集中所有真实匹配的行人图像。采用CMC时,如果两个系统同样有能力发现第一个真实匹配,但却有不同的召回能力,在这种情况下,CMC相比于mAP没有足够的鉴别能力。因此,mAP是一个更全面的评测指标。
五、行人再识别在视频监控中的应用及展望
行人再识别技术具有非常重要的理论意义和应用价值。What,When,Where和Who是智能视频监控系统不可或缺的四个要素。例如,我们不仅关心在地铁站内是否发生以及什么时候在什么位置发生了丢弃包裹的行为,而且也关心行为人的身份信息,希望能够利用行为人离开时的行人特征信息获得该人在监控网络中的行迹。行人再识别主要关注跨视域人物识别场景下的身份识别问题,将其中一个摄像机中的行人图像作为查询样本,将另外一个或多个摄像机中的所有行人的图像作为查询库,在查询库中检索与查询样本属于同一个人的样本,从而实现跨视域的人物身份识别。
行人再识别技术正在研发和试用过程中,因其难度较大,产品级的系统尚未投入使用。目前,公安部第一研究所采用清华大学的行人再识别技术开始在公共场所进行测试。相信在不久的将来,随着行人再识别技术的发展,该技术必将在公安和安防领域投入使用,发挥巨大的工作效益。
随着视频监控系统的普及,基于视频监控的行人再识别近年来已成为智能视频分析领域最为活跃的研究方向之一。行人再识别的任务是在不同摄像头下根据行人表观识别行人,因为视角、姿势和光照的变化,这项任务充满了挑战性。行人再识别的核心问题涉及图像的表示和匹配,而基于表观的行人再识别可以被认为是图像检索中搜索包含相同行人图像的一种应用。今后,行人再识别需要重点研究的课题包括更加准确的行人检测、行人分割、行人属性提取、以及高性能的人像匹配算法。最近基于深度学习的卷积神经网络(CNN)的工作引起了广泛的注意,在行人再识别技术中应用将能产生优越的性能,是未来主要的研究和发展方向。
参考文献:
[1] Huang T, Russell S. Object Identification in a Bayesian Context.IJCAI, Volume 97, 1997.12761282.
[2] Zajdel W, Zivkovic Z, Krose B. Keeping Track of Humans: Have iSeen this Person Before? Robotics and Automation, 2005. ICRA 2005. Proceedingsof the 2005 IEEE International Conference on. IEEE, 2005. 20812086.
[3] Gheissari N, Sebastian T B, Hartley R. Person Reidentificationusing Spatiotemporal Appearance. Computer Vision and Pattern Recognition, 2006IEEE Computer Society Conference on,
volume 2. IEEE, 2006. 15281535.
[4] Farenzena M, Bazzani L, Perina A, et al. Person Re-Identificationby Symmetry-driven Accumulation of Local Features. Computer Vision and PatternRecognition (CVPR), 2010 IEEE Conference on. IEEE, 2010. 23602367.
[5] Gray D, Tao H. Viewpoint Invariant Pedestrian Recognition withan Ensemble of Localized Features. European Conference on Computer Vision.Springer, 2008. 262275.
[6] Prosser B, Zheng W S, Gong S, et al. Person re-identification bysupport vector ranking. BMVC, volume 2, 2010. 6.
[7] Zheng W S, Gong S, Xiang T. Reidentification by Relative DistanceComparison. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013, 35(3):653668.
[8] Ma A J, Yuen P C, Li J. Domain Transfer Support Vector Rankingfor Person Re-Identification Without Target Camera Label Information.Proceedings of the IEEE International Conference on Computer Vision, 2013.35673574.
[9] Li Z, Chang S, Liang F, et al. Learning Locally-adaptiveDecision Functions for Person Verification. Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, 2013.36103617.
[10] Chen D, Yuan Z, Chen B, et al. Similarity Learning with SpatialConstraints for Person Re-identification. Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2016. 12681277.
声明:本文来自警察技术杂志,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
