机器之心报道,参与:路、李泽南
去年引起热议、能够生成逼真图像的 BigGAN 声名鹊起,相关论文后被 ICLR 2019 收录为 Oral 论文。今天论文一作 Andrew Brock 发推称:论文更新版已上传,模型架构有所更新——网络深度是原来的 4 倍、模型参数仅为原来的一半。Andrew Brock 还表示新版 BigGAN(BigGAN-deep)相比原版训练速度更快、FID 和 IS 均优于原版,且新版 BigGAN 在一些较难类别上的表现也优于原版,如人群和人脸,尤其是在 128x128 分辨率图像上。
论文链接:https://openreview.net/pdf?id=B1xsqj09Fm
BigGAN TF Hub demo 地址:https://tfhub.dev/s?q=biggan
Colab 地址:
https://colab.research.google.com/github/tensorflow/hub/blob/master/examples/colab/biggan_generation_with_tf_hub.ipynb#scrollTo=Cd1dhL4Ykbm7
论文作者表示,BigGAN-deep 的预训练模型将会随后放出。
BigGAN 横空出世
BigGAN 在去年 9 月一经提出即引起了大量关注,被称为「史上最强 GAN 图像生成器」,其生成图像的目标和背景都高度逼真、边界自然,并且图像插值每一帧都相当真实。

这些图像都是 BigGAN 自动生成的。
该论文一经发布,就引起了著名人工智能学者 Oriol Vinyals、Ian Goodfellow 的关注。11 月,ICLR 2019 的论文评审结果出炉,这篇 BigGAN 论文获得了 8、7、10 的评分。BigGAN 的原版在 ImageNet 数据集下 Inception Score 竟然比此前最好 GAN 模型 SAGAN 提高了 100 多分(接近 2 倍)!

BigGAN 已被众多研究者们「玩坏」:如果把两种不同类型的事物合并,BigGAN 则会生成诡异的效果。
BigGAN 将正交正则化的思想引入 GAN,通过对输入先验分布 z 的适时截断大大提升了 GAN 的生成性能,通过截断隐空间来精调样本保真度和多样性的权衡。这种修改方法可以让模型在类条件的图像合成中达到当前最佳性能。
这项研究成功地将 GAN 生成图像和真实图像之间的保真度和多样性 gap 大幅降低。其主要贡献如下:
- 展示了 GAN 可以从训练规模中显著获益,并且能在参数数量很大和八倍批大小于之前最佳结果的条件下,仍然能以 2 倍到 4 倍的速度进行训练。作者引入了两种简单的生成架构变化,提高了可扩展性,并修改了正则化方案以提升条件化(conditioning),从而提升性能。
作为修改方法的副作用,该模型变得服从「截断技巧」,这是一种简单的采样技术,允许对样本多样性和保真度进行精细控制。
发现大规模 GAN 带来的不稳定性,并对其进行经验描述。从这种分析中获得的洞察表明,将一种新型的和已有的技术结合可以减少这种不稳定性,但要实现完全的训练稳定性必须以显著降低性能为代价。
BigGAN vs. BigGAN-deep
目前,这篇论文已经出了更新版,模型架构也有所改进,新版模型名为 BigGAN-deep,从名字中我们可以猜测出二者在深度方面似乎有所区别。
在 128x128 分辨率的 ImageNet 上训练时,BigGAN 可以达到 166.3 的 Inception 分数(IS),以及 9.6 的 Frechet Inception 距离(FID);而 BigGAN-deep 可达到 166.5 的 IS,7.4 的 FID,均优于原版 BigGAN。
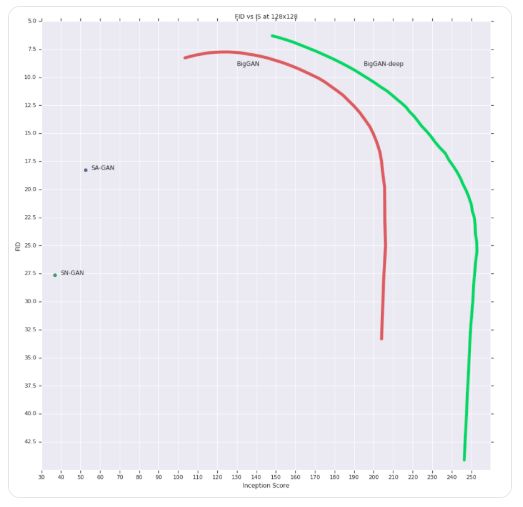
BigGAN-deep 与 BigGAN 在 128×128 图像上的 IS 和 FID 对比。
那么 BigGAN-deep 相比于 BigGAN 有何不同呢?
- 深度增加:BigGAN-deep 的深度是 BigGAN 的 4 倍;
参数减少:BigGAN-deep 基于带有 bottleneck 的残差块;
训练速度变快
性能改进:FID 和 IS 均优于原版。在 128x128 分辨率的 ImageNet 图像上,BigGAN-deep 的 IS 高出 BigGAN 两个百分点,而 FID 比 BigGAN 降低了 2.2。
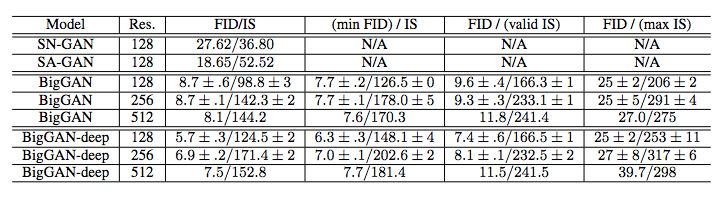
BigGAN-deep 和 BigGAN 在不同分辨率图像上的评估结果对比。
模型架构
二者的模型架构如下图所示:
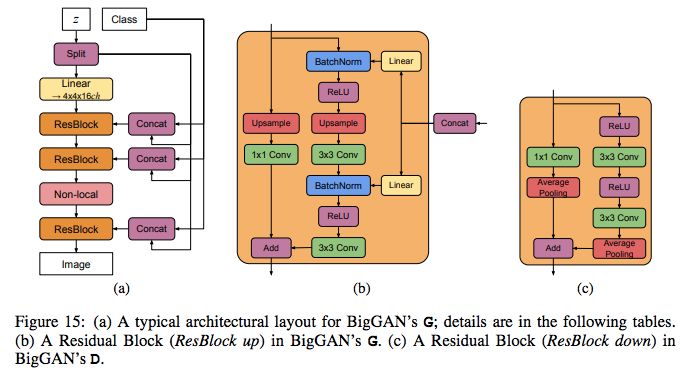
BigGAN 模型架构。
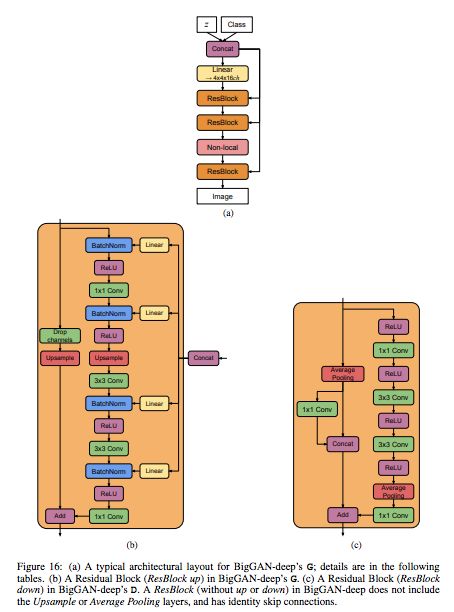
BigGAN-deep 模型架构。
从命名上我们可以看到更新版比原版多了个后缀「-deep」。据作者介绍,BigGAN-deep 的深度是原来的 4 倍。从模型架构上来看,BigGAN 模型使用 ResNet 架构,在生成器 G 中使用了单个共享类别嵌入,对 latent vector z 应用了跳过连接(skip-z)。具体来说,研究者使用了层级潜在空间,使得 latent vector z 按照通道维度被分割为同等大小的块(该研究案例中是 20-D),每个块被级联到共享类别嵌入,并传输到对应的残差块作为条件向量。每个残差块的条件向量被线性投影,以为残差块 BatchNorm 层生成每个样本的 gain 和偏差。偏差投影以零为中心,而 gain 投影以 1 为中心。由于残差块依赖于图像分辨率,因此 z 对于 128 × 128 图像的完整维度是 120,对 256 × 256 图像的完整维度是 140,对 512 × 512 图像的完整维度是 160。
BigGAN-deep 和 BigGAN 的区别主要体现在以下几个方面:BigGAN-deep 使用了 skip-z 条件的一个更简单的变体:作者不是先将 z 分割成块,而是将整个 z 与类别嵌入连接起来,并通过跳过连接将得到的向量传递给每个残差块。BigGAN-deep 基于带有 bottleneck 的残差块,它合并了两个额外的 1 × 1 卷积:第一个卷积将通道数缩减为原来的 1/4,比之前的 3 × 3 卷积开销要小;第二个卷积产生所需数量的输出通道。无论何时通道的数量需要改变,BigGAN 在跳过连接中都依赖 1 × 1 卷积,但 BigGAN-deep 则选择了不同的策略,以在跳过连接中保持 identity。G 中的通道数需要减少,因此研究者保留第一组通道舍弃其他通道,以使最终通道数符合要求。D 中的通道数需要增加,因此研究者将输入通道原封不动地馈入 D,并将其与 1 × 1 卷积生成的其余通道级联起来。至于网络配置,判别器是生成器的完美反映。该模型中对每个分辨率使用两个模块(BigGAN 使用 1 个),因此 BigGAN-deep 的深度是 BigGAN 的 4 倍。尽管深度有所增加,但 BigGAN-deep 的参数却远远少于 BigGAN,这主要是因为前者残差块的瓶颈结构。例如,128 × 128 BigGAN-deep G 和 D 分别具备 50.4M 和 34.6M 个参数,而对应的原版 BigGAN 分别具备 70.4M 和 88.0M 个参数。所有 BigGAN-deep 模型在 64 × 64 分辨率、通道宽度乘数 ch = 128、z ∈ R^128 时使用注意力。
BigGAN-deep 效果
目前 BigGAN-deep 尚未开源,但作者已经把新模型的生成图像样本放在了论文所附链接中。
链接:https://drive.google.com/drive/folders/1lWC6XEPD0LT5KUnPXeve_kWeY-FxH002


声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
