选自medium,作者:Brian Srebrenik
机器之心编译,参与:Nurhachu Null、Chita
前不久,因为 AI 可以自动生成文本和图片,关于 AI 自动生成假新闻的讨论不绝于耳。有人不免担忧假新闻的泛滥,但是本文作者以子之矛攻子之盾,用机器学习来检测假新闻的源头。
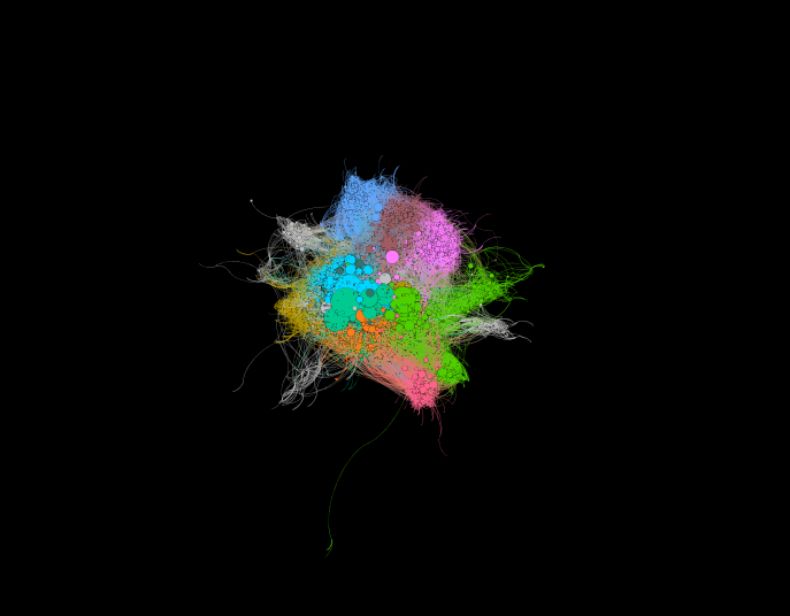
拥有超过一百万粉丝的认证用户的推特网络。圆圈(节点)代表用户,连接圆圈的线条代表一个用户「关注」另一个用户。颜色表示通过模块化聚类确定的类别。
虽然「假新闻」早在互联网时代开始之前就存在了,但如今确定新闻源头的可靠性貌似比以往任何时候都难。在做了关于这个课题的一些研究之后,作者发现图论方面正在做一些研究,来观察我们是否可以用机器学习来帮助检测假新闻的源头。作者对网络的力量以及能够从中得到的信息非常感兴趣,所以决定建立一个分类模型,以从 ego network 中寻找一些模式来检测假新闻。
什么是 ego network?
Ego Network(在人类社交网络分析中也被称为 Personal Network)由一个中心节点 Ego 和与其直接相连的节点 Alter 组成,网络中的边展示了 Ego 与 Altar 或者 Alter 之间的联系。ego network 中的每个 alter 可以有其自己的 ego network,所有的 ego network 结合起来就形成了社交网络。在这样的网络中,ego 可以是人类,或者是像商业活动中的产品和服务一样的对象。在下图中,作者可视化了推特上粉丝超过一百万的认证用户的 ego network。每个圆圈代表一个推特认证用户的节点(圈的大小与其粉丝总数相关),连接它们的线条或者边代表的是一个用户「关注」了另一个用户。这张可视化图,以及本文中的其它图都是使用 Gephi 来制作的。

考虑到这个项目的目的,作者决定分析严格经过认证的推特网络,因为有一种自然的倾向:用户更加信任被推特官方认证的信息源。
训练数据的问题:如何确定哪个节点代表假新闻的源头?
在项目开端面临的最大问题可能就是如何确定哪个推特账户被归类为用作训练数据的虚假新闻来源。目前并没有一致的方式来确定某条新闻是不是假新闻,如果有的话,这也不会是一个首要问题了。幸运的是,作者找到了 ICWSM 2015 的一篇论文《CREDBANK: A Large-scale Social Media Corpus With Associated Credibility Annotations》所附带的 CREDBANK 数据。
总之,CREDBANK 包含了超过 6 千万条关于 1049 个真实事件的推文,每条推文都由 Amazon Mechanical Turk 的 30 名工作人员做了可信度标注(每个标注都有他们的基本理由)。CREDBANK 的主要贡献就是以一种系统、全面的方式编制了一个将社交媒体事件流和人类置信度判断连接在一起的独特数据集。
通过把这个数据集和推特社交网络数据结合起来,作者可以创建一个用于训练分类模型的数据集。该数据包含 69025 个认证用户,以及他们之间的所有联系。在这些用户中,有 66621 名被确定为真实新闻来源,有 2404 名被确认为虚假新闻源。被认定为虚假新闻源的是那些有超过 5% 的推文被 Amazon Mechanical Turk 的置信度评价者标记为低于部分准确的用户。
社交网络 EDA

这是作者所创数据集中所有新闻源的社交网络图。蓝色的点和线代表的是真信息源,红色的代表的是假信息源。

这和上面的图是同一幅图,只是仅仅显示了虚假信息源。
在收集和组织完数据(作者用了图数据库 Neo4j 来存储网络数据)以后,第一步就是对网络数据做一个初始的探索性分析。作者在初始分析中用了两个网络算法:特征向量中心性(Eigenvector Centrality)和 PageRank。特征向量中心性算法只在数据中的一个样本上运行,因为在大规模网络上计算中心性会耗费相当长的时间。
特征向量中心性是对一个节点在网络中的影响力的度量。基于以下概念将相对分数赋给网络中的所有节点:与高分节点的连接对所讨论节点的分数贡献比与低分节点的相等连接更多。高特征向量得分意味着该节点连接了许多高分节点。
PageRank 被广泛视为检测图中具有影响的节点的一种方式。它与其他的中心性算法不同,因为一个节点的影响要依赖于其邻近节点的影响。
来源: https://github.com/neo4j-graph-analytics/graph-algorithms-notebooks
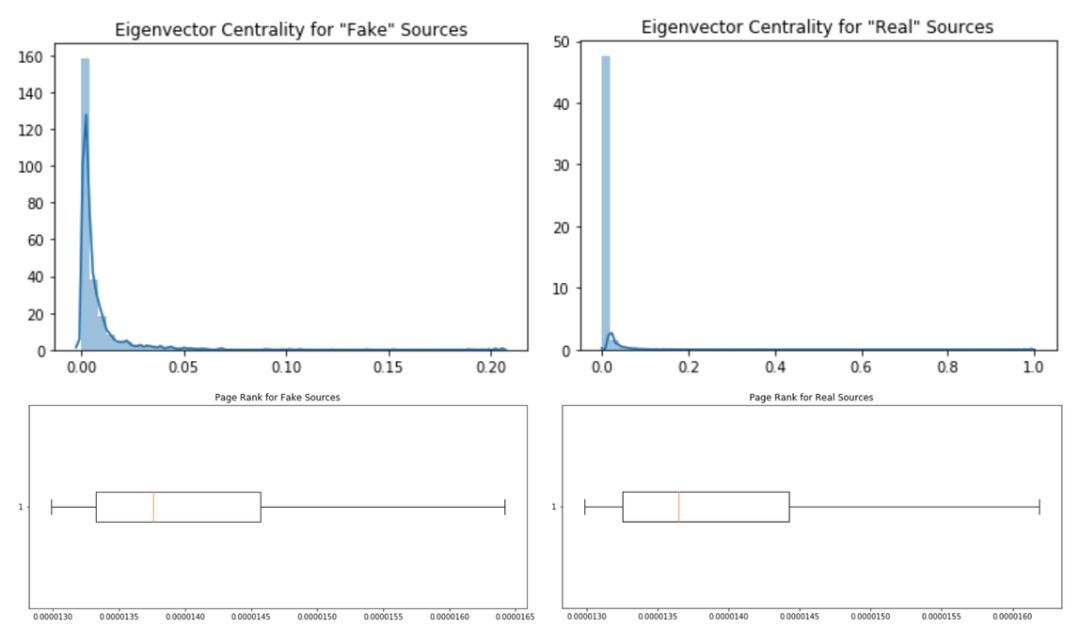
我使用 Python 库 NetworkX 对这些算法的实现来确定上面展示的统计量。
正如你所看到的,尽管真实信息源的特征向量中心性有更大的扩展,但是总体上二者非常相似。因此必须寻找其他方法来区分这两类节点。
通过 Louvain 社区发现(Community Detection)算法进行聚类
Louvain 的社区发现方法是一个用于检测网络中的社区的算法。它最大化了每个社区的模块化得分,其中模块化通过评估它们在随机网络中的连接程度来量化节点到社区的分配质量。
作者决定在其网络数据上运行这个算法来看看虚假信息源是否被放在了同一类别。在下面的第一张图中,他可视化了整个网络图,每个节点都被标记为了它被分配的类别的颜色。第二张图仅包含了虚假信息源。
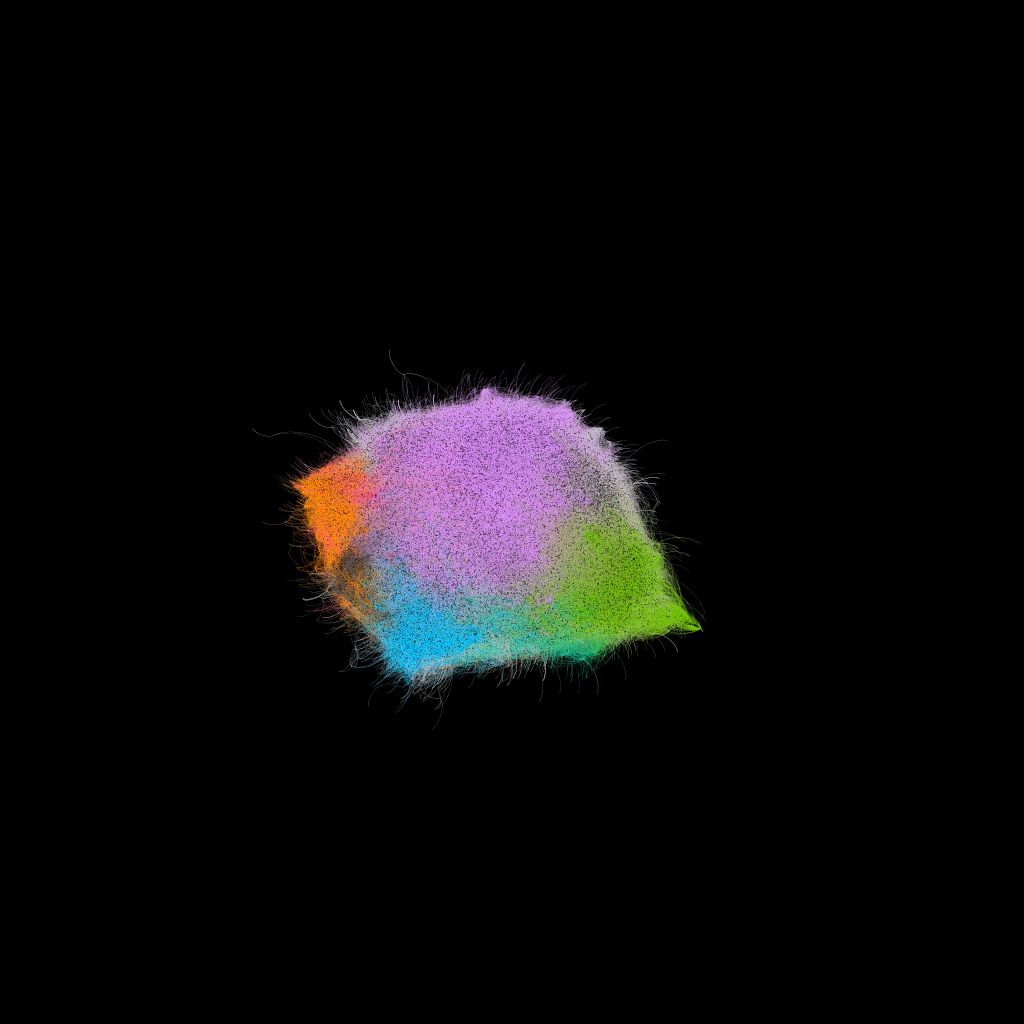

貌似绝大多数虚假信息源都被放在了紫色和绿色的类别中,并且,显而易见所有的虚假消息源都主要分布在图中的一个区域。这确实很好地消除了 25838 个真实信息源(通过这种聚类方法将 25838 个节点放置在没有任何虚假来源的类中),但仍然不足以完全隔离虚假新闻源。为此,作者决定尝试 node2vec。
Node2Vec
斯坦福大学网络分析项目 node2vec 的创建者这样说:
node2vec 框架通过优化保留目标的邻域来学习图中节点的低维表征。其目标是灵活的,并且算法通过模拟有偏差的随机游动来适应网络邻域的各种定义。具体而言,它提供了一种平衡 exploration- exploitation 权衡的方法,这反过来得到了遵循从同质到结构等价的一系列等价的表示。
基本而言,node2vec 算法让作者可以将所有节点嵌入到一个以上的维度(具体地,在这个项目中是 128 维)中,以作为给图中节点的位置设计新特征的方式。在其模型中,他使用了该算法的这种实现。
下面是其选择的一些参数:

不幸的是,即使为每个节点设计了这 128 个新特征之后,其最初尝试构建的分类模型也没有成功。由于严重的类别不均衡(不到 4%的节点是虚假源),其算法总是预测所有信息源都是真实的。因此他需要一些其他差异化功能来帮助这些分类算法。
词嵌入
node2vec 的思想实际上来自于词向量,这是一种向量化类型,它通过训练神经网络来计算文本语料的词向量,神经网络会产生高维的向量空间,而语料中的每个单词都是这个空间中的一个独特向量。在这个嵌入空间中,一个向量与其他向量的相对位置就能够捕获到语义含义。
作者决定使用每个 Twitter 用户的简要描述在循环神经网络中进行分类。网络内的嵌入层计算词嵌入向量。然后,该神经网络的输出将是 Twitter 账户的描述来自真实账户或虚假账户的概率。然后,他将结合来自 node2vec 的特性使用这些概率来构建最终的集合分类模型。以下是循环神经网络的详细信息:
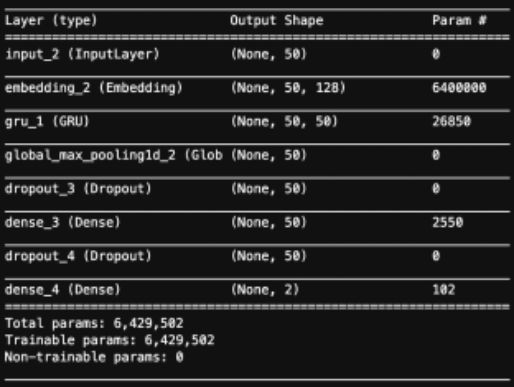
模型总结
最终分类模型
作者使用来自 node2vec 的特性和来自神经网络的概率在 SVM 和 XGBoost 上进行了网格搜索。他决定将搜索聚焦于高召回率和高精度的模型上,因为其类别非常不均衡(将所有的样本预测为「真实新闻」也会得到高达 95.6% 的准确率)。
XGBoost 和 SVM 的网格搜索结果
下图展示了为 XGBoost 和 SVM 分类器找到的最佳参数,以及最终模型的混淆矩阵:
1. XGBoost
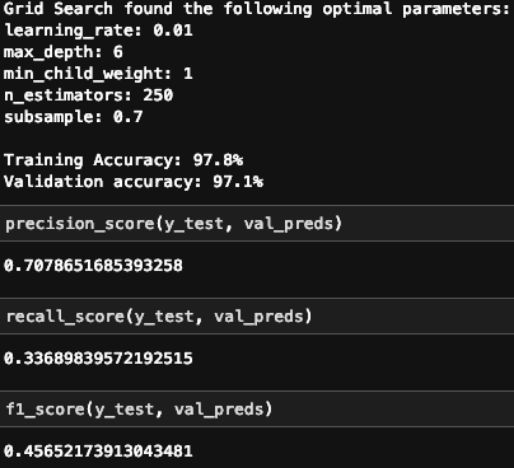
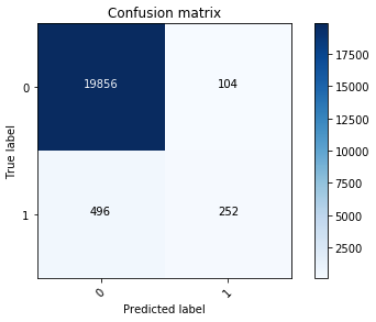
2. SVM
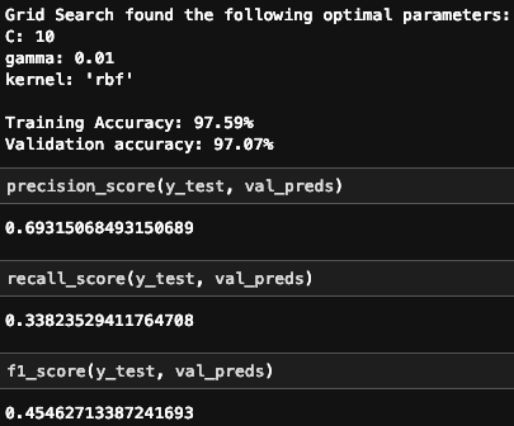
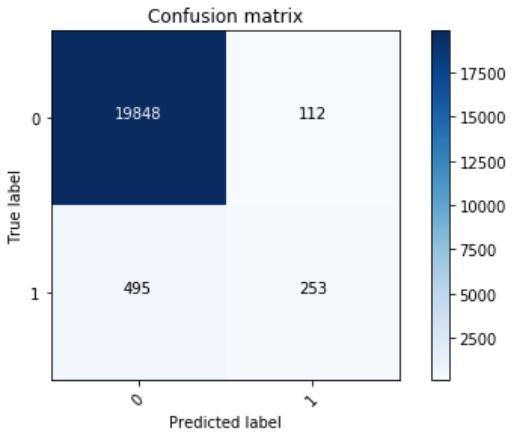
正如你在上面看到的,XGBoost 模型的精度要稍微好一些,但是 SVM 模型的召回率要稍微好一些。
结论
这些分类模型表现得相当好,尤其是考虑到严重的类别不均衡。显然,词嵌入特征对模型检测真正例(true positive)的能力有很大的影响。虽然作者想基于网络的特征严格地对节点进行分类,但似乎还不足以将这些节点区分为虚假节点。但是,作者确实认为网络分析在检测虚假新闻方面有很大的潜力。他所遇到的一些问题必须使用更大规模的网络来解决(就像其之前提到的,由于规模的原因,不能在整个网络上计算中心性),并且,数据中确实还有更多的模式有待发现。
如果你想查看作者项目的代码库及其完整的分析,可以从以下链接找到:
https://github.com/briansrebrenik/Final_Project
原文地址:https://towardsdatascience.com/ego-network-analysis-for-the-detection-of-fake-news-da6b2dfc7c7e
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
