背景
众所周知,日志是记录应用程序运行状态的一种重要工具,在业务服务中,日志更是十分重要。通常情况下,日志主要是记录关键执行点、程序执行错误时的现场信息等。系统出现故障时,运维人员一般先查看错误日志,定位故障原因。当业务流量小、逻辑复杂度低时,应用出现故障时错误日志一般较少,运维人员一般能够根据错误日志迅速定位到问题。但是,随着业务逻辑的迭代,系统接入的依赖服务不断增多,引入的组件不断增多,当系统出现故障时(如Bug被触发、依赖服务超时等等),错误日志的量级会急剧增加。极端情况下甚至出现“疯狂报错”的现象,这时候错误日志的内容会存在相互掩埋、相互影响的问题,运维人员面对报错一时难以理清逻辑,有时甚至顾此失彼,没能第一时间解决最核心的问题。
错误日志是系统报警的一种,实际生产中,运维人员能够收到的报警信息多种多样。如果在报警流出现的时候,通过处理程序,将报警进行聚类,整理出一段时间内的报警摘要,那么运维人员就可以在摘要信息的帮助下,先对当前的故障有一个大致的轮廓,再结合技术知识与业务知识定位故障的根本原因。
围绕上面描述的问题,以及对于报警聚类处理的分析假设,本文主要做了以下事情:
- 选定聚类算法,简单描述了算法的基本原理,并给出了针对报警日志聚类的一种具体的实现方案。
- 在分布式业务服务的系统下构造了三种不同实验场景,验证了算法的效果,并且对算法的不足进行分析阐述。
目标
对一段时间内的报警进行聚类处理,将具有相同根因的报警归纳为能够涵盖报警内容的泛化报警(Generalized Alarms),最终形成仅有几条泛化报警的报警摘要。如下图1所示意。
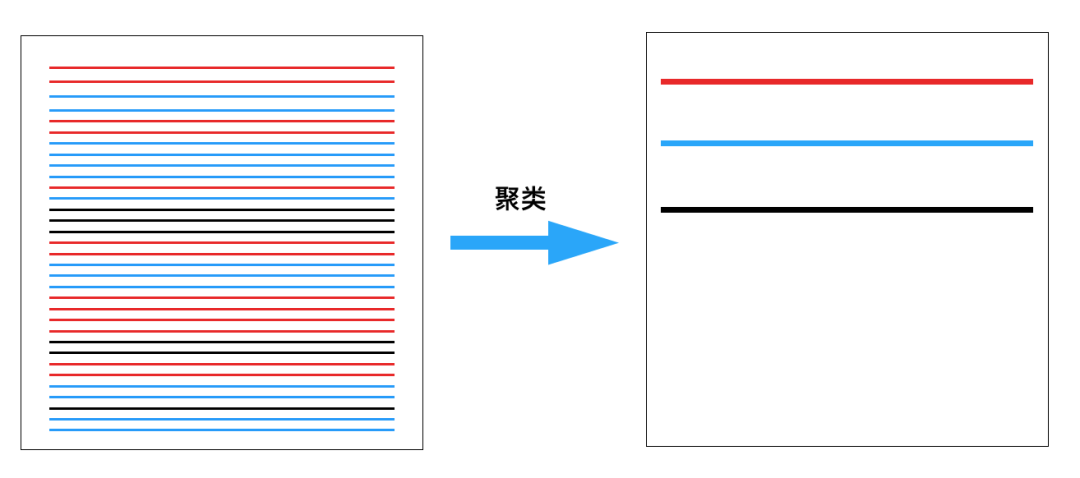
我们希望这些泛化报警既要具有很强的概括性,同时尽可能地保留细节。这样运维人员在收到报警时,便能快速定位到故障的大致方向,从而提高故障排查的效率。
设计
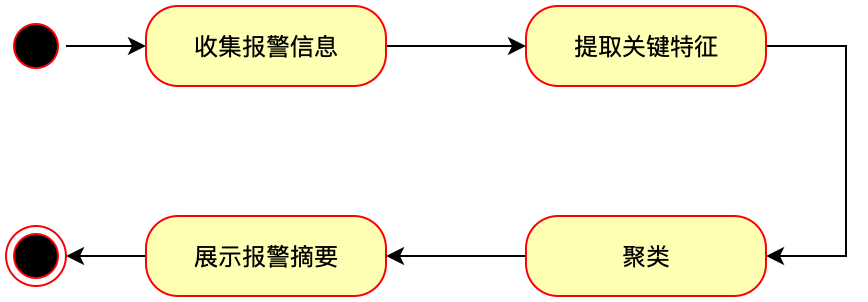
如图2所示,异常报警根因分析的设计大致分为四个部分:收集报警信息、提取报警信息的关键特征、聚类处理、展示报警摘要。
算法选择
聚类算法采用论文“Clustering Intrusion Detection Alarms to Support Root Cause Analysis” [KLAUS JULISCH, 2002]中描述的根因分析算法。该算法基于一个假设:将报警日志集群经过泛化,得到的泛化报警能够表示报警集群的主要特征。以下面的例子来说明,有如下的几条报警日志:

我们可以将这几条报警抽象为:“全部服务器 网络调用 故障”,该泛化报警包含的范围较广;也可以抽象为:“server_room_a服务器 网络调用 产品信息获取失败”和“server_room_b服务器 RPC 获取产品类型信息失败”,此时包含的范围较小。当然也可以用其他层次的抽象来表达这个报警集群。
我们可以观察到,抽象层次越高,细节越少,但是它能包含的范围就越大;反之,抽象层次越低,则可能无用信息越多,包含的范围就越小。
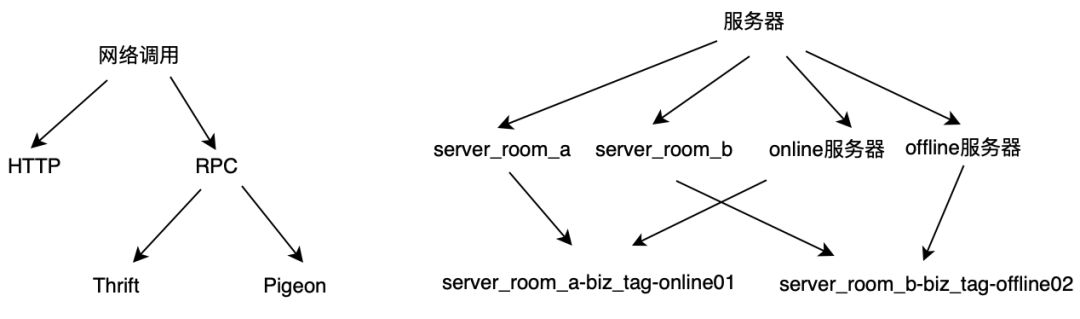
这种抽象的层次关系可以用一些有向无环图(DAG)来表达,如图3所示:
为了确定报警聚类泛化的程度,我们需要先了解一些定义:
- 属性(Attribute):构成报警日志的某一类信息,如机器、环境、时间等,文中用Ai表示。
- 值域(Domain):属性Ai的域(即取值范围),文中用Dom(Ai)表示。
- 泛化层次结构(Generalization Hierarchy):对于每个Ai都有一个对应的泛化层次结构,文中用Gi表示。
- 不相似度(Dissimilarity):定义为d(a1, a2)。它接受两个报警a1、a2作为输入,并返回一个数值量,表示这两个报警不相似的程度。与相似度相反,当d(a1, a2)较小时,表示报警a1和报警a2相似。为了计算不相似度,需要用户定义泛化层次结构。
为了计算d(a1, a2),我们先定义两个属性的不相似度。令x1、x2为某个属性Ai的两个不同的值,那么x1、x2的不相似度为:在泛化层次结构Gi中,通过一个公共点父节点p连接x1、x2的最短路径长度。即d(x1, x2) := min{d(x1, p) + d(x2, p) | p ∈ Gi, x1 ⊴ p, x2 ⊴ p}。例如在图3的泛化层次结构中,d("Thrift", "Pigeon") = d("RPC", "Thrift") + d("RPC", "Pigeon") = 1 + 1 = 2。
对于两个报警a1、a2,其计算方式为:
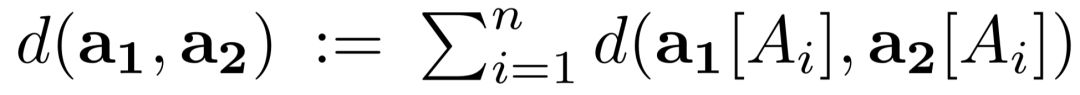
例如:a1 = ("server_room_b-biz_tag-offline02", "Thrift"), a2 = ("server_room_a-biz_tag-online01", "Pigeon"), 则d(a1, a2) = d("server_room_b-biz_tag-offline02", "server_room_a-biz_tag-online01") + d(("Thrift", "Pigeon") = d("server_room_b-biz_tag-offline02", "服务器") + d("server_room_a-biz_tag-online01", "服务器") + d("RPC", "Thrift") + d("RPC", "Pigeon") = 2 + 2 + 1 + 1 = 6。
我们用C表示报警集合,g是C的一个泛化表示,即满足∀ a ∈ C, a ⊴ g。以报警集合{"dx-trip-package-api02 Thrift get deal list error.", "dx-trip-package-api01 Thrift get deal list error."}为例,“dx服务器 thrift调用 获取产品信息失败”是一个泛化表示,“服务器 网络调用 获取产品信息失败”也是一个泛化表示。对于某个报警聚类来说,我们希望获得既能够涵盖它的集合又有最具象化的表达的泛化表示。为了解决这个问题,定义以下两个指标:
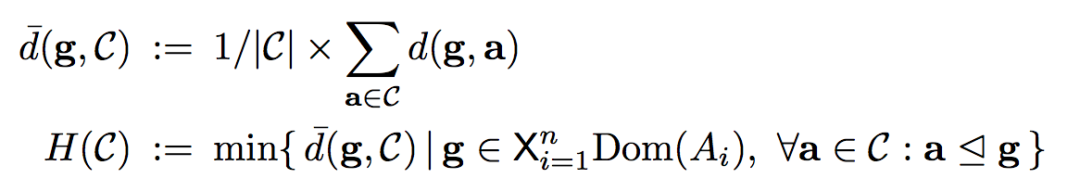
H(C)值最小时对应的g,就是我们要找的最适合的泛化表示,我们称g为C的“覆盖”(Cover)。
基于以上的概念,将报警日志聚类问题定义为:定义L为一个日志集合,min_size为一个预设的常量,Gi(i = 1, 2, 3……n) 为属性Ai的泛化层次结构,目标是找到一个L的子集C,满足 |C| >= min_size,且H(C)值最小。min_size是用来控制抽象程度的,极端情况下如果min_size与L集合的大小一样,那么我们只能使用终极抽象了,而如果min_size = 1,则每个报警日志是它自己的抽象。找到一个聚类之后,我们可以去除这些元素,然后在L剩下的集合里找其他的聚类。
不幸的是,这是个NP完全问题,因此论文提出了一种启发式算法,该算法满足|C| >= min_size,使H(C)值尽量小。
算法描述
- 算法假设所有的泛化层次结构Gi都是树,这样每个报警集群都有一个唯一的、最顶层的泛化结果。
- 将L定义为一个原始的报警日志集合,算法选择一个属性Ai,将L中所有报警的Ai值替换为Gi中Ai的父值,通过这一操作不断对报警进行泛化。
- 持续步骤2的操作,直到找到一个覆盖报警数量大于min_size的泛化报警为止。
- 输出步骤3中找到的报警。
算法伪代码如下所示:

其中第7行的启发算法为:

这里的逻辑是:如果有一个报警a满足 a[count]>= min_size,那么对于所有属性Ai , 均能满足Fi >= fi(a[Ai]) >= min_size。反过来说,如果有一个属性Ai的Fi值小于min_size,那么a[count]就不可能大于min_size。所以选择Fi值最小的属性Ai进行泛化,有助于尽快达到聚类的条件。
此外,关于min_size的选择,如果选择了一个过大的min_size,那么会迫使算法合并具有不同根源的报警。另一方面,如果过小,那么聚类可能会提前结束,具有相同根源的报警可能会出现在不同的聚类中。
因此,设置一个初始值,可以记作ms0。定义一个较小的值 ℇ(0 < ℇ < 1),当min_size取值为ms0、ms0 * (1 - ℇ)、ms0 * (1 + ℇ)时的聚类结果相同时,我们就说此时聚类是ℇ-鲁棒的。如果不相同,则使ms1 = ms0 * (1 - ℇ),重复这个测试,直到找到一个鲁棒的最小值。
需要注意的是,ℇ-鲁棒性与特定的报警日志相关。因此,给定的最小值,可能相对于一个报警日志来说是鲁棒的,而对于另一个报警日志来说是不鲁棒的。
实现
1. 提取报警特征
根据线上问题排查的经验,运维人员通常关注的指标包括时间、机器(机房、环境)、异常来源、报警日志文本提示、故障所在位置(代码行数、接口、类)、Case相关的特殊ID(订单号、产品编号、用户ID等等)等。
但是,我们的实际应用场景都是线上准实时场景,时间间隔比较短,因此我们不需要关注时间。同时,Case相关的特殊ID不符合我们希望获得一个抽象描述的要求,因此也无需关注此项指标。
综上,我们选择的特征包括:机房、环境、异常来源、报警日志文本关键内容、故障所在位置(接口、类)共5个。
2. 算法实现
(1) 提取关键特征
我们的数据来源是日志中心已经格式化过的报警日志信息,这些信息主要包含:报警日志产生的时间、服务标记、在代码中的位置、日志内容等。
故障所在位置
优先查找是否有异常堆栈,如存在则查找第一个本地代码的位置;如果不存在,则取日志打印位置。
异常来源
获得故障所在位置后,优先使用此信息确定异常报警的来源(需要预先定义词典支持);如不能获取,则在日志内容中根据关键字匹配(需要预先定义词典支持)。
报警日志文本关键内容
优先查找是否有异常堆栈,如存在,则查找最后一个异常(通常为真正的故障原因);如不能获取,则在日志中查找是否存在“code=……,message=……” 这样形式的错误提示;如不能获取,则取日志内容的第一行内容(以换行符为界),并去除其中可能存在的Case相关的提示信息
- 提取“机房和环境”这两个指标比较简单,在此不做赘述。
(2) 聚类算法
算法的执行,我们以图4来表示。
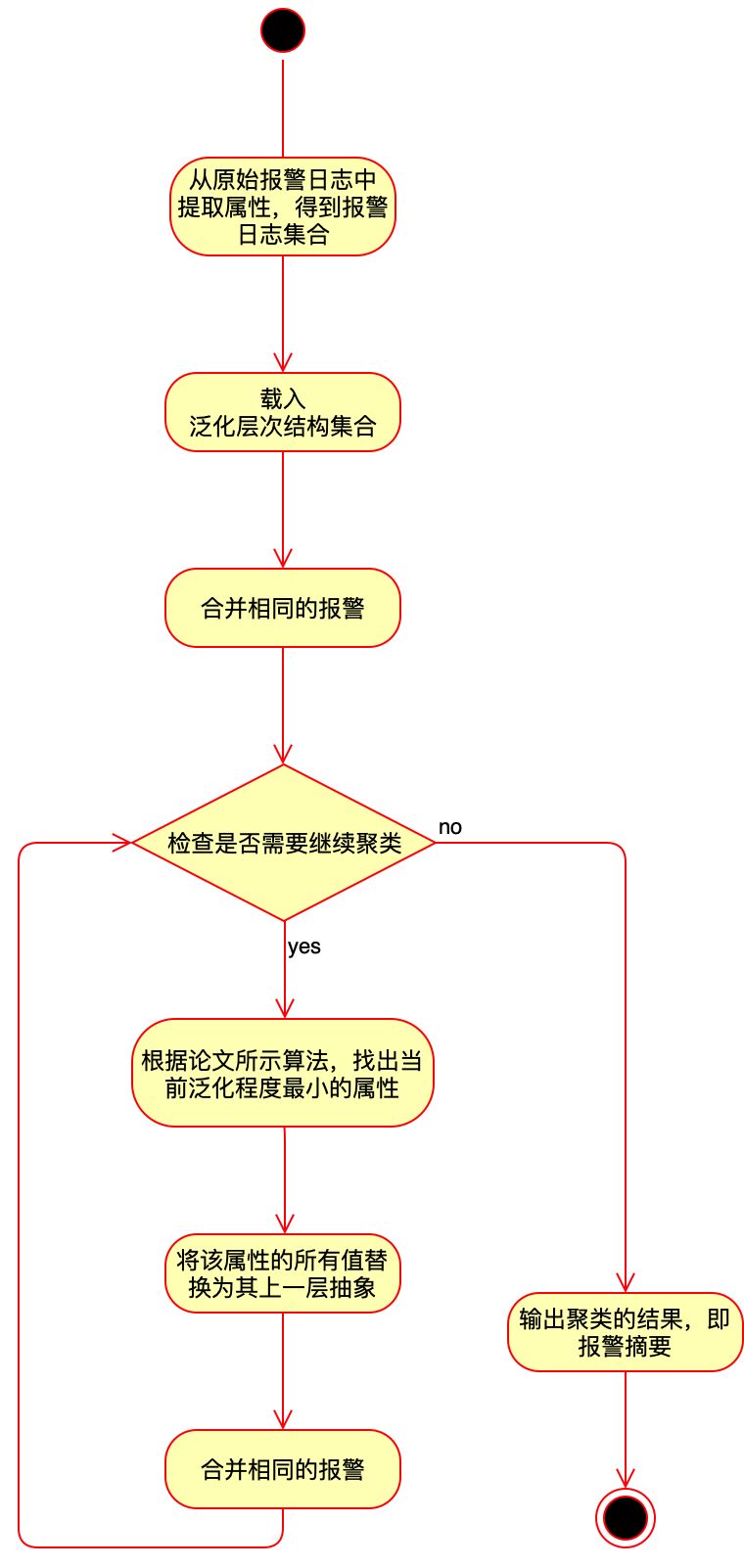
(3) min_size 选择
考虑到日志数据中可能包含种类极多,且根据小规模数据实验表明,min_size = 1/5 * 报警日志数量时,算法已经有较好的表现,再高会增加过度聚合的风险,因此我们取min_size = 1/5 * 报警日志数量,ℇ参考论文中的实验,取0.05。
(4) 聚类停止条件
考虑到部分场景下,报警日志可能较少,因此min_size的值也较少,此时聚类已无太大意义,因此设定聚类停止条件为:聚类结果的报警摘要数量小于等于20或已经存在某个类别的count值达到min_size的阈值,即停止聚类。
3. 泛化层次结构
泛化层次结构,用于记录属性的泛化关系,是泛化时向上抽象的依据,需要预先定义。
根据实验所用项目的实际使用环境,我们定义的泛化层次结构如下:
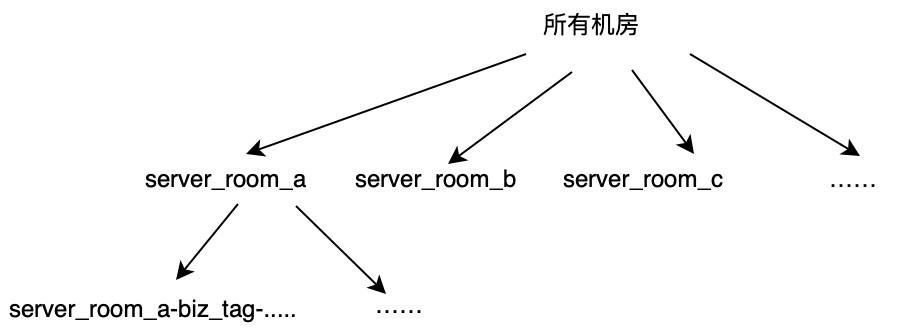
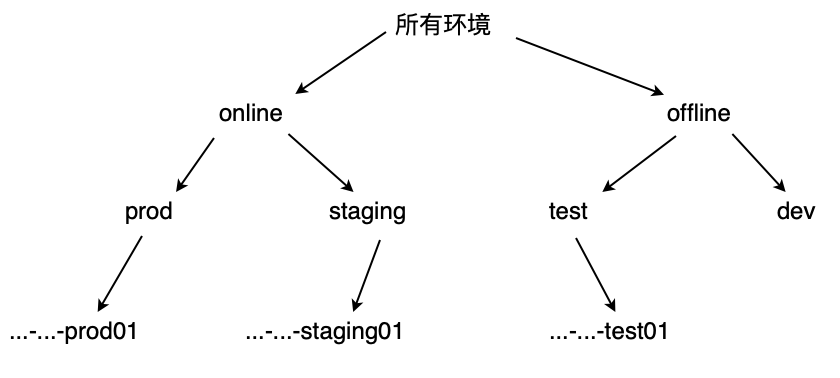

“故障所在位置”此属性无需泛化层次结构,每次泛化时直接按照包路径向上层截断,直到系统包名。
实验
以下三个实验均使用C端API系统。
1. 单依赖故障
实验材料来自于线上某业务系统真实故障时所产生的大量报警日志。
- 环境:线上
- 故障原因:产品中心线上单机故障
- 报警日志数量:939条
部分原始报警日志如图9所示,初次观察时,很难理出头绪。
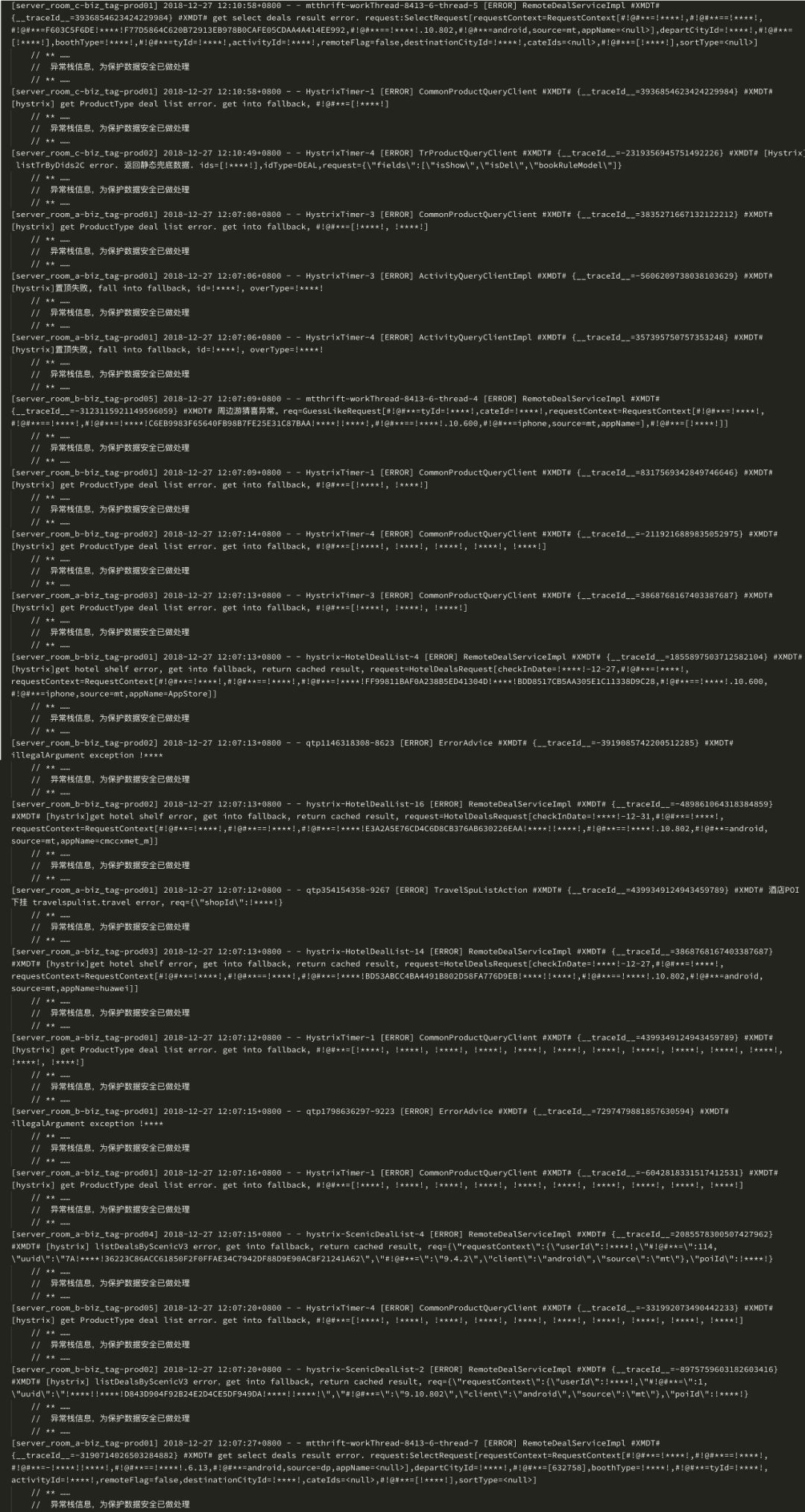
经过聚类后的报警摘要如表1所示:
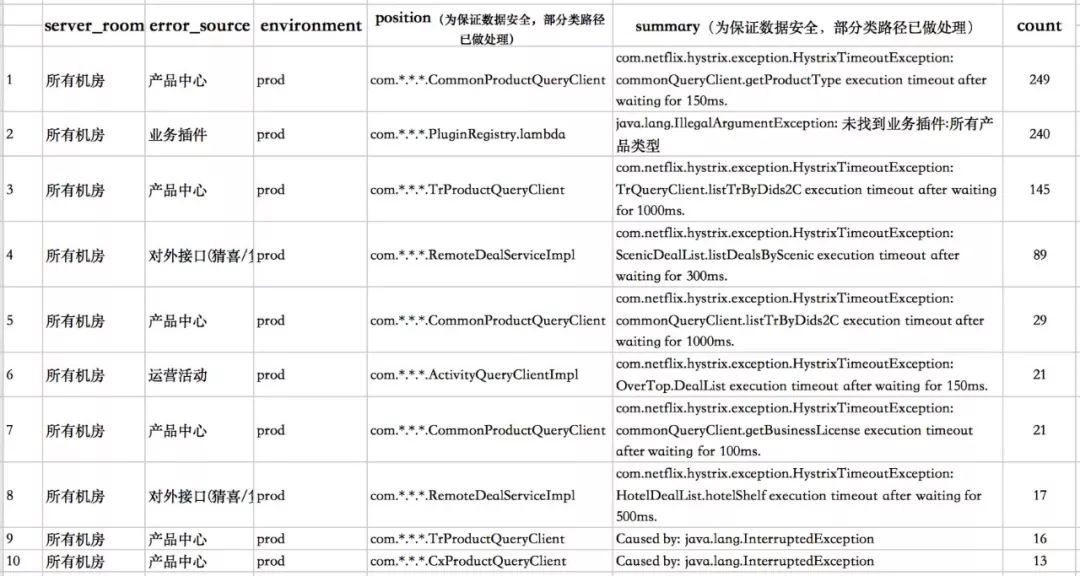
我们可以看到前三条报警摘要的Count远超其他报警摘要,并且它们指明了故障主要发生在产品中心的接口。
2. 无相关的多依赖同时故障
实验材料为利用故障注入工具,在Staging环境模拟运营置顶服务和A/B测试服务同时产生故障的场景。
- 环境:Staging(使用线上录制流量和压测平台模拟线上正常流量环境)
- 模拟故障原因:置顶与A/B测试接口大量超时
- 报警日志数量:527条
部分原始报警日志如图10所示:
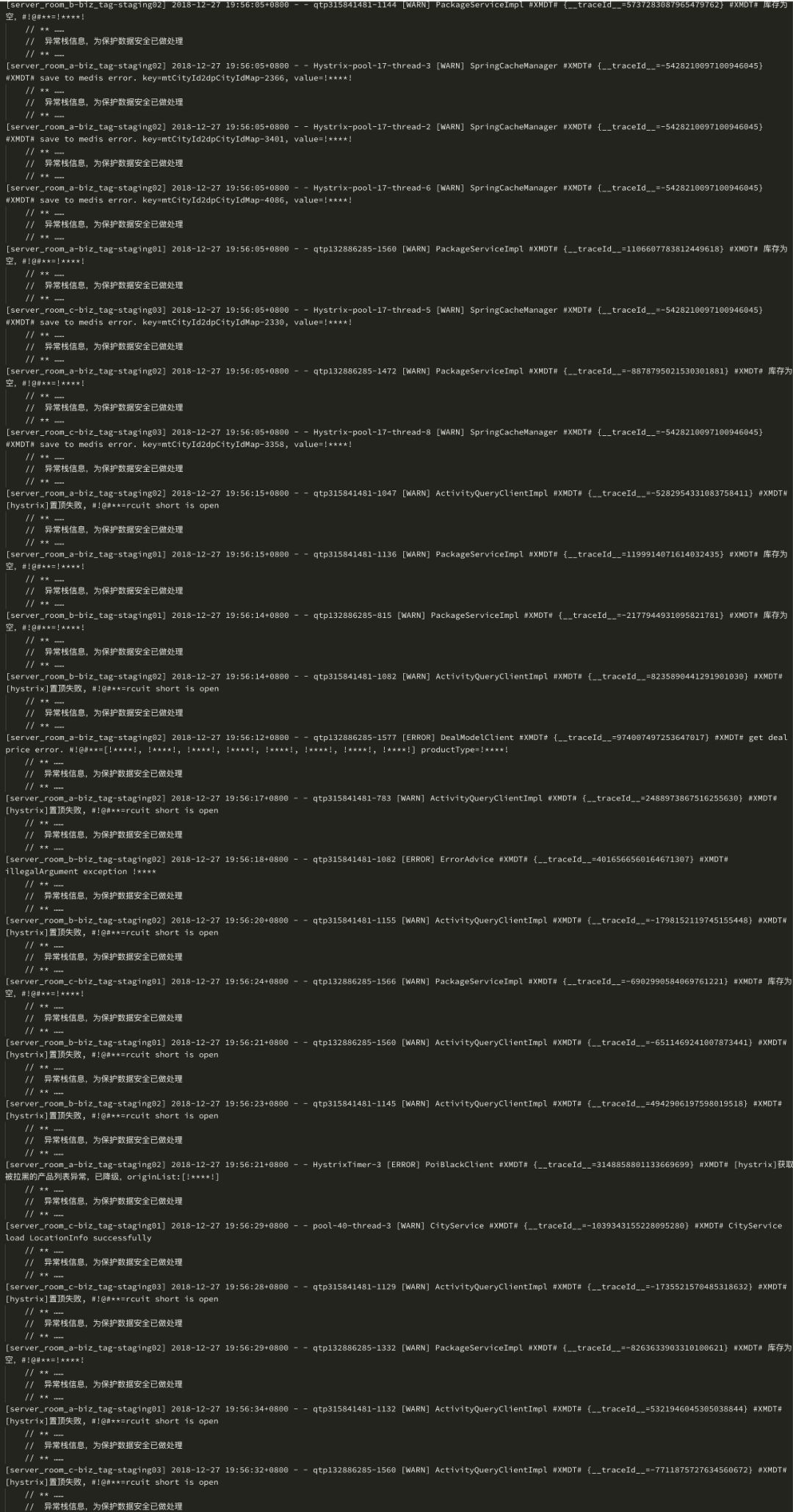
经过聚类后的报警摘要如表2所示:
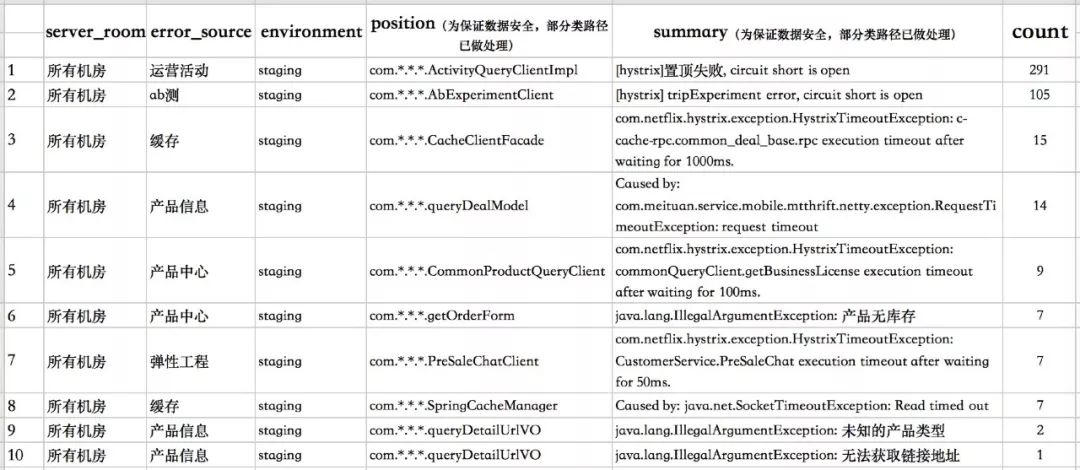
从上表可以看到,前两条报警摘要符合本次试验的预期,定位到了故障发生的原因。说明在多故障的情况下,算法也有较好的效果。
3. 中间件与相关依赖同时故障
实验材料为利用故障注入工具,在Staging环境模拟产品中心服务和缓存服务同时产生超时故障的场景。
- 环境:Staging(使用线上录制流量和压测平台模拟线上正常流量环境)
- 模拟故障原因:产品中心所有接口超时,所有缓存服务超时
- 报警日志数量:2165
部分原始报警日志如图11所示:
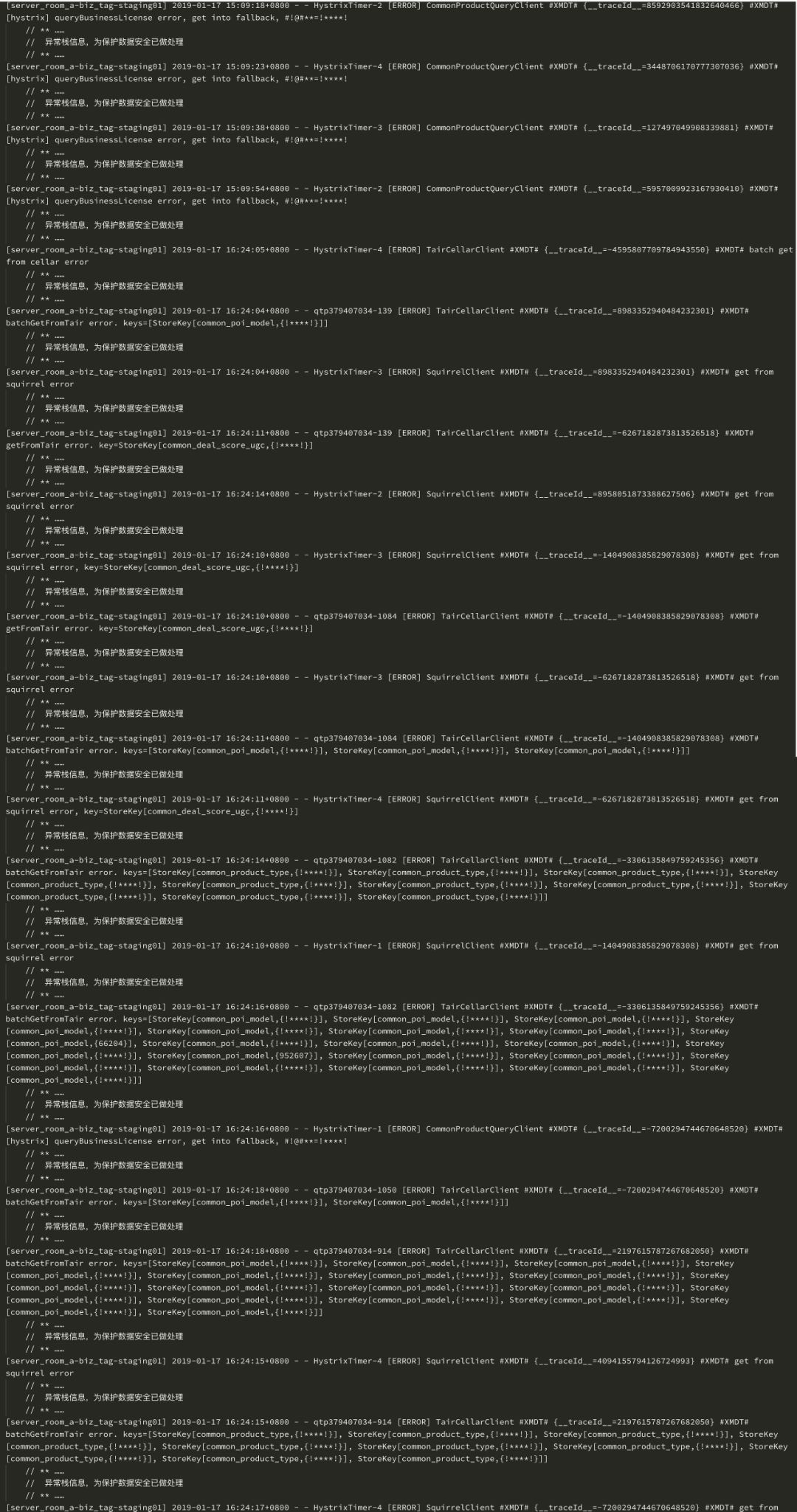
经过聚类后的报警摘要如表3所示:
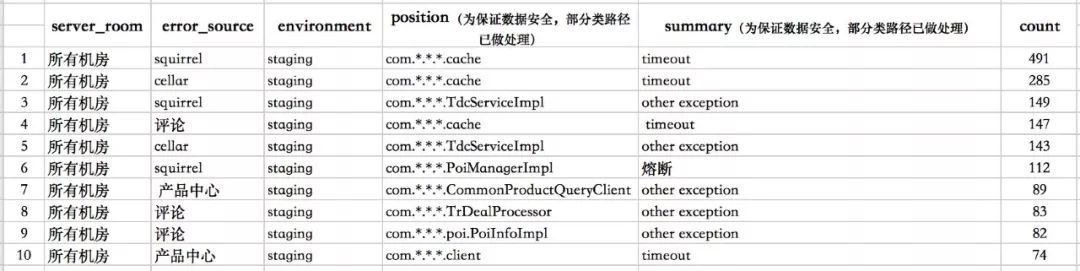
从上表可以看到,缓存(Squirrel和Cellar双缓存)超时最多,产品中心的超时相对较少,这是因为我们系统针对产品中心的部分接口做了兜底处理,当超时发生时后先查缓存,如果缓存查不到会穿透调用一个离线信息缓存系统,因此产品中心超时总体较少。
综合上述三个实验得出结果,算法对于报警日志的泛化是具有一定效果。在所进行实验的三个场景中,均能够定位到关键问题。但是依然存在一些不足,报警摘要中,有的经过泛化的信息过于笼统(比如Other Exception)。
经过分析,我们发现主要的原因有:其一,对于错误信息中关键字段的提取,在一定程度上决定了向上泛化的准确度。其二,系统本身日志设计存在一定的局限性。
同时,在利用这个泛化后的报警摘要进行分析时,需要使用者具备相应领域的知识。
未来规划
本文所关注的工作,主要在于验证聚类算法效果,还有一些方向可以继续完善和优化:
- 日志内容的深度分析。本文仅对报警日志做了简单的关键字提取和人工标记,未涉及太多文本分析的内容。我们可以通过使用文本分类、文本特征向量相似度等,提高日志内容分析的准确度,提升泛化效果。
- 多种聚类算法综合使用。本文仅探讨了处理系统错误日志时表现较好的聚类算法,针对系统中多种不同类型的报警,未来也可以配合其他聚类算法(如K-Means)共同对报警进行处理,优化聚合效果。
- 自适应报警阈值。除了对报警聚类,我们还可以通过对监控指标的时序分析,动态管理报警阈值,提高告警的质量和及时性,减少误报和漏告数量。
参考资料
- Julisch, Klaus. "Clustering intrusion detection alarms to support root cause analysis." ACM transactions on information and system security (TISSEC) 6.4 (2003): 443-471.
- https://en.wikipedia.org/wiki/Cluster_analysis
作者简介
刘玚,美团点评后端工程师。2017 年加入美团点评,负责美团点评境内度假的业务开发。
千钊,美团点评后端工程师。2017 年加入美团点评,负责美团点评境内度假的业务开发。
声明:本文来自美团技术团队,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
