由《农业图书情报》编辑部主办的2019全国图书情报青年学术论坛于1月7号在冰城哈尔滨胜利落下帷幕。此次论坛云集了来自北京大学、清华大学、中国科学院、南京大学、武汉大学、复旦大学,北京理工大学、黑龙江大学、中国农业科学院、中国科学技术信息研究所、中国医学科学院等50余家科研院所图书情报领域的专家学者。
2019年论坛主题“新兴技术、前沿追踪与最佳实践”,共22场学术报告。(专家报告请关注公众号的后续报道)。
专家简介

唐杰,清华大学计算机系教授、计算机系副主任、清华-工程院知识智能联合实验室主任、杰青。研究方向为社会网络分析、数据挖掘、机器学习和知识图谱。发表论文200余篇,引用10 000多次(个人h-指数54)。主持研发了科技情报挖掘平台AMiner,收录1.36亿科研人员、2.31亿科技文献,吸引了220个国家/地区800多万独立IP访问。担任国际权威期刊ACM TKDD的执行编辑和国际会议CIKM'16、WSDM'15程序委员会主席、KDD'18大会副主席以及IEEE TKDE、ACM TIST、IEEE TBD等期刊编委。荣获北京市科技进步一等奖、中国人工智能学会科技进步一等奖、KDD杰出贡献奖。
知识驱动的科技情报挖掘
01 情报驱动的科技服务产业
02 科技情报挖掘
03 科技情报挖掘面临的挑战
04 AMiner.cn:知识驱动的科技情报挖掘平台
报告内容
简单描述了科技服务产业的现状和科技情报挖据的挑战,并对AMiner平台进行了介绍,最后对在知识挖掘,包括知识创新研究的一些工作同大家分享。
01 情报驱动的科技服务产业
科技情报服务在科技服务产业中最近有了很大的发展。知识工程,知识挖掘已经不再是单纯的学术研究范畴,它已经开始进入产业。
到2020年,中国科技服务产业的规模可以达到8万亿元的规模。对比美国科技经济,美国科技服务业的GDP占比在过去的几年也是在快速的增长,从2002年到2014年的时间增长了80%。

02 科技情报挖掘
科技情报挖掘是在科技服务产业里面一个分支,它也处在快速发展的阶段。
情报分析往往是以文献为中心的,但是现在情况已经发生了非常大的变化,科技文献的量井喷式的发展。年论文增长量达到百万级,并且全球论文总量也达几亿规模。在这样的情况下,以人工的方式做情报整理显然是不现实的。
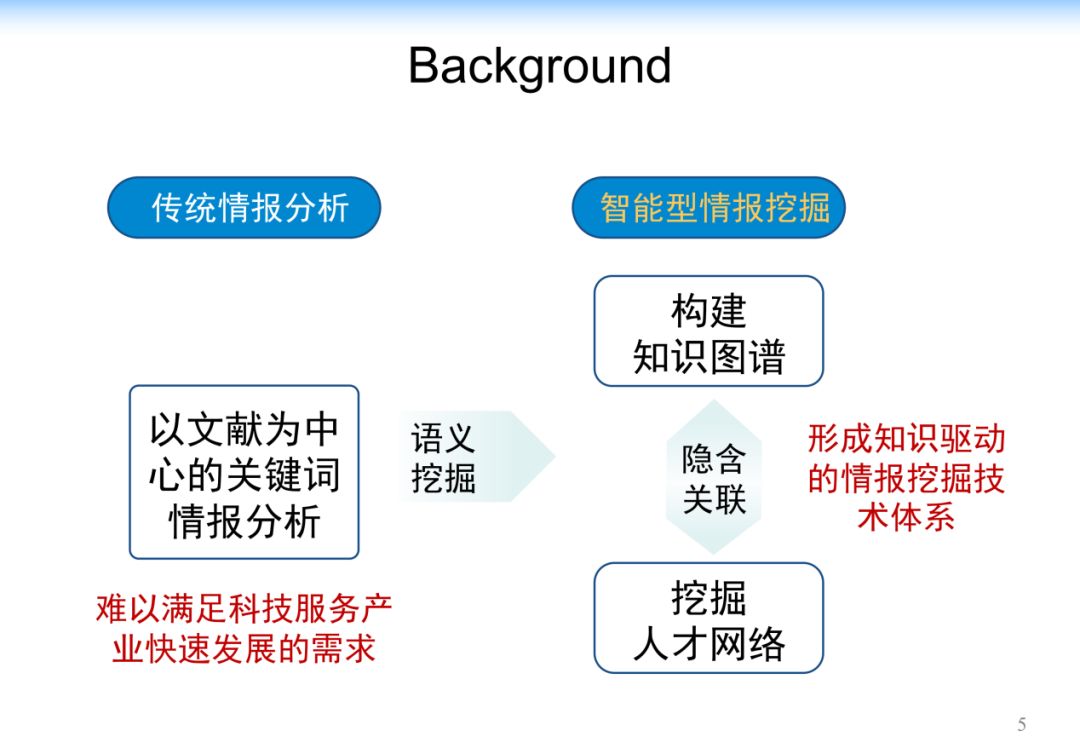
近年来,随着大数据、云计算、深度学习的发展,给智能型情报挖掘系统的发展提供了基础。通过知识图谱和人才网络,通过推理的方式发现知识图谱和人才之间的关系,从而形成知识驱动的情报挖掘技术体系,是智能型情报挖掘的目标。
03 科技情报挖掘面临的挑战
我们在挖掘知识图谱和人之间关联时,就形成了知识驱动的情报挖掘技术体系。那么在基于大数据的科技情报挖掘时,会面临什么样的挑战呢?
(1)情报信息以碎片化的形式分散在异构、多源数据中,知识获取难度大;
(2)情报网络结构复杂,交互行为动态多样,挖掘情报隐含关联关系十分困难;
(3)情报网络规模非常大、数据多维,匹配效率低是智能型情报计算的瓶颈。
全球范围内先进国家对科技情报挖掘都非常重视,美国的NSF和ARMY 2015年就超过8千万美元的投入;欧盟的第8框架H2020也有6项关于科技情报分析,共21项科学领域的项目。2018年截止到目前为止,Nature和Science杂志中已有23篇与科技大数据挖掘有关的论文。同时多个顶尖学术研究机构都建立了相关研究团队。
04 知识驱动的科技情报挖掘平台
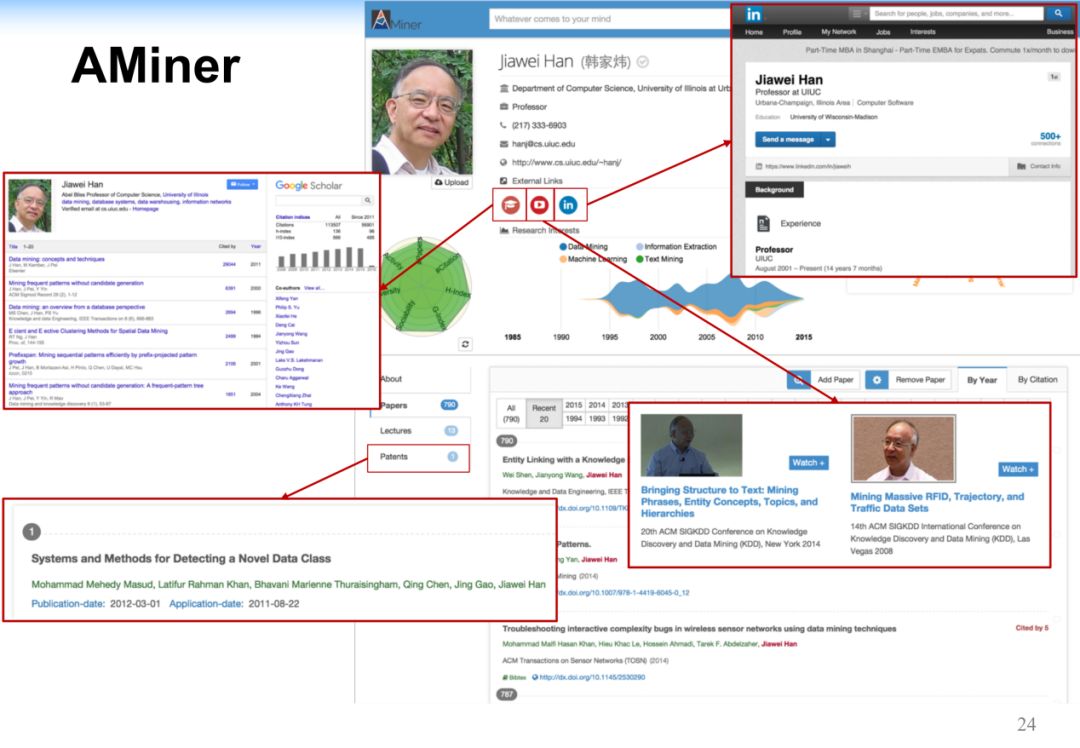
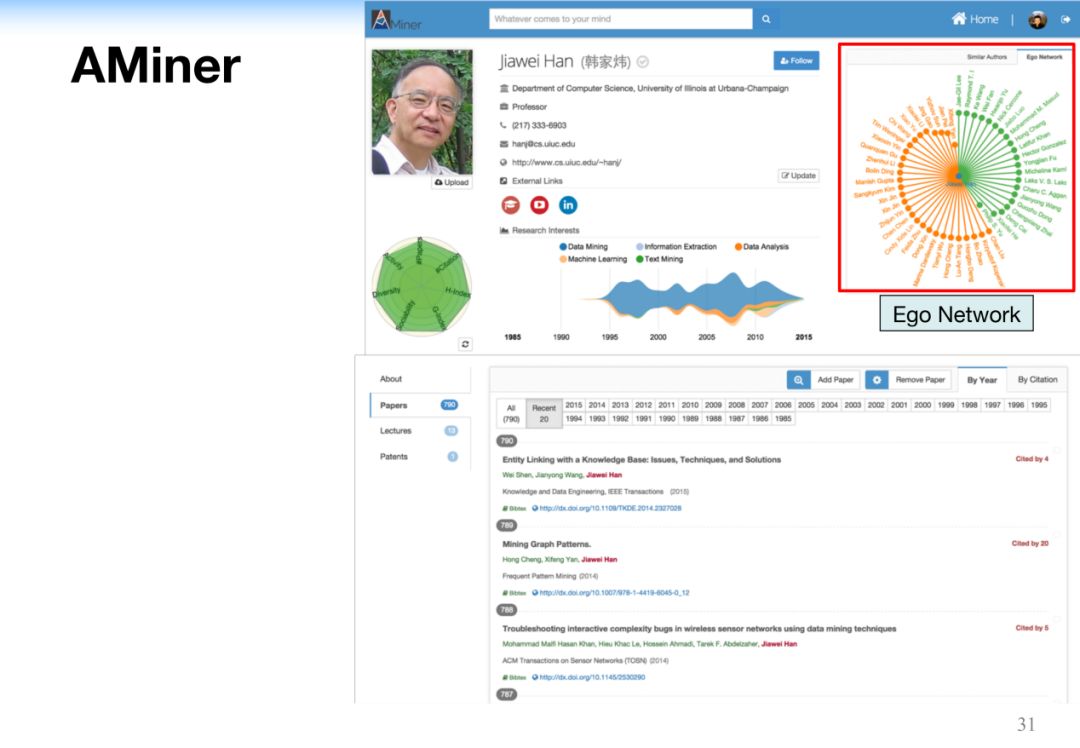
AMiner平台是我们在10多年前建立起来的学术搜索平台,大家可以通过网址www.aminer.cn访问。它主要的功能包括:
(1)知识获取,科技知识图谱构建;
(2)隐含关联,知识到情报挖掘;
(3)语义匹配,情报到智能服务。
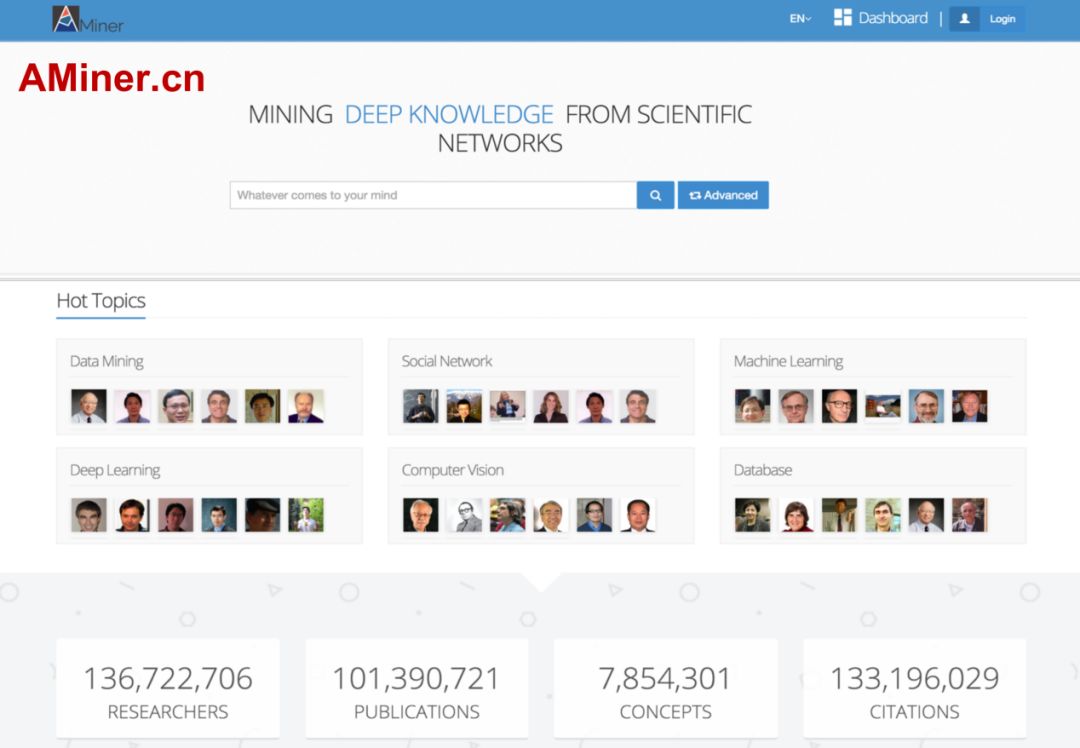
AMiner系统是以知识和专家为核心的学术搜索平台,当搜索某个领域的时候,返回的结果,包括知识图谱和领域专家列表。
Open Services——语义搜索。
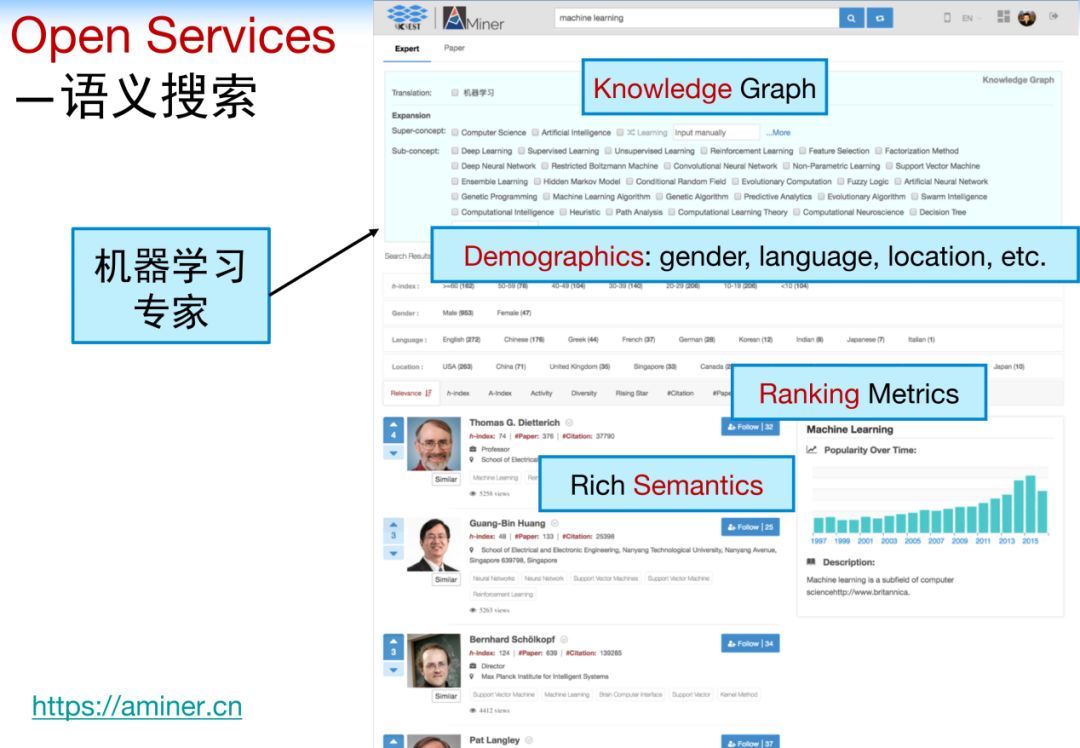
以上图搜索“machine learning”为例,首先显示出机器学习的知识图谱体系,包括上位词和下位词。方便大家快速的确定领域,找到细分的兴趣点,比如深度学习,监督学习,强化学习等。也就是说,我们在匹配用户搜索概念的初衷时,帮他去发现真正搜索目的。
同时,快速过滤的功能,包括语言、国家、H指数范围等。为了方便的找到目标的学者,还可以快速的根据h指数、引用数、论文数等排序。
4.1 Open Report——技术发展报告

在AMiner人工智能引擎的基础上,在AMiner的首页上,2018年发布了14篇研究报告,这些报告部分内容是通过人工智能自动生成的。
4.2 AMiner平台系统的核心技术
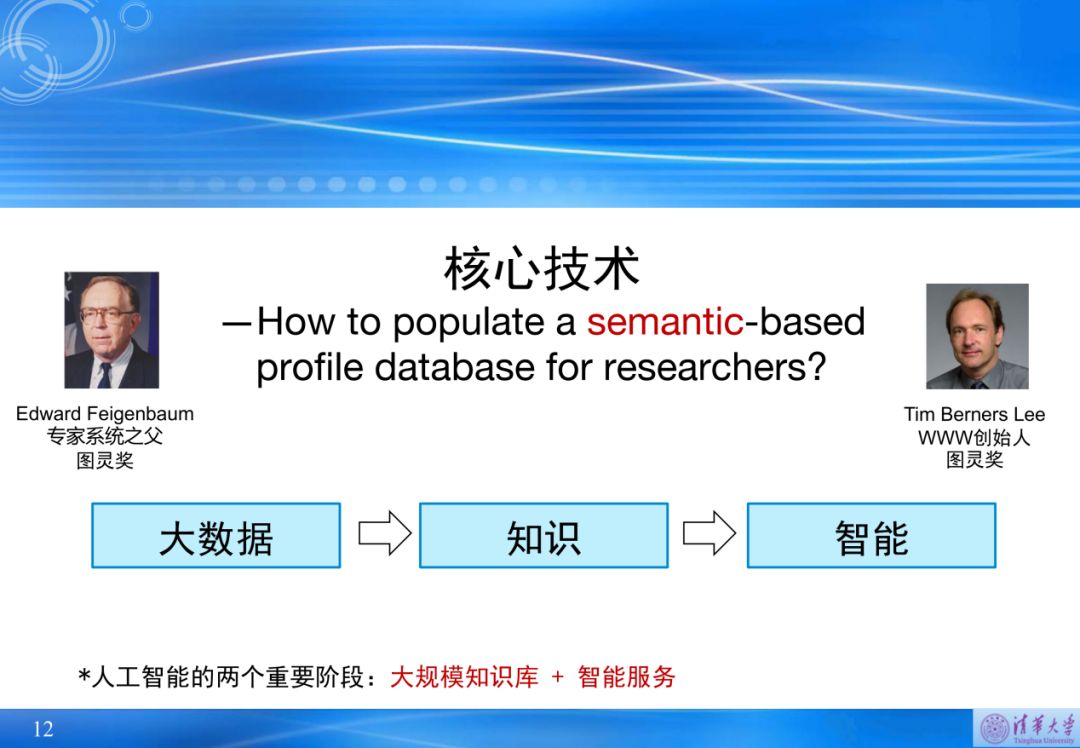
智能科技情报服务的发展,符合图灵奖的获奖者Tim Berners Lee提出来的大数据、知识和智能这三个阶段的发展。
以AI为例。以知识图谱和学者画像为基础,打造人工智能科研助手。
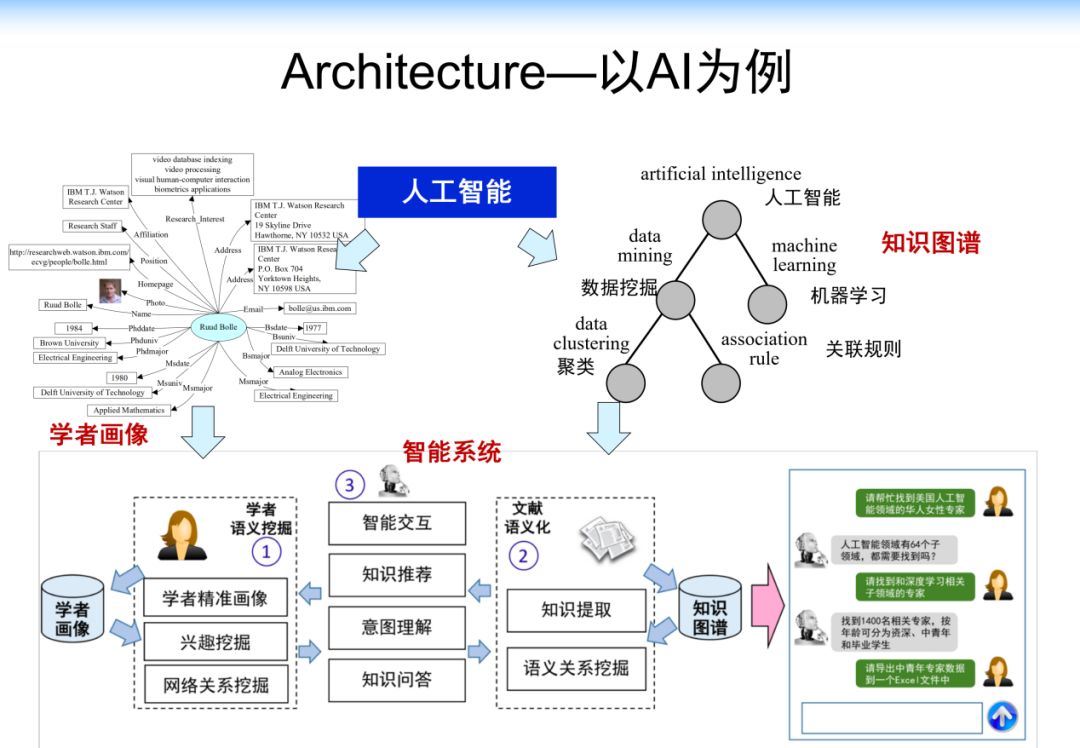
4.3 在科技情报挖掘方面的工作
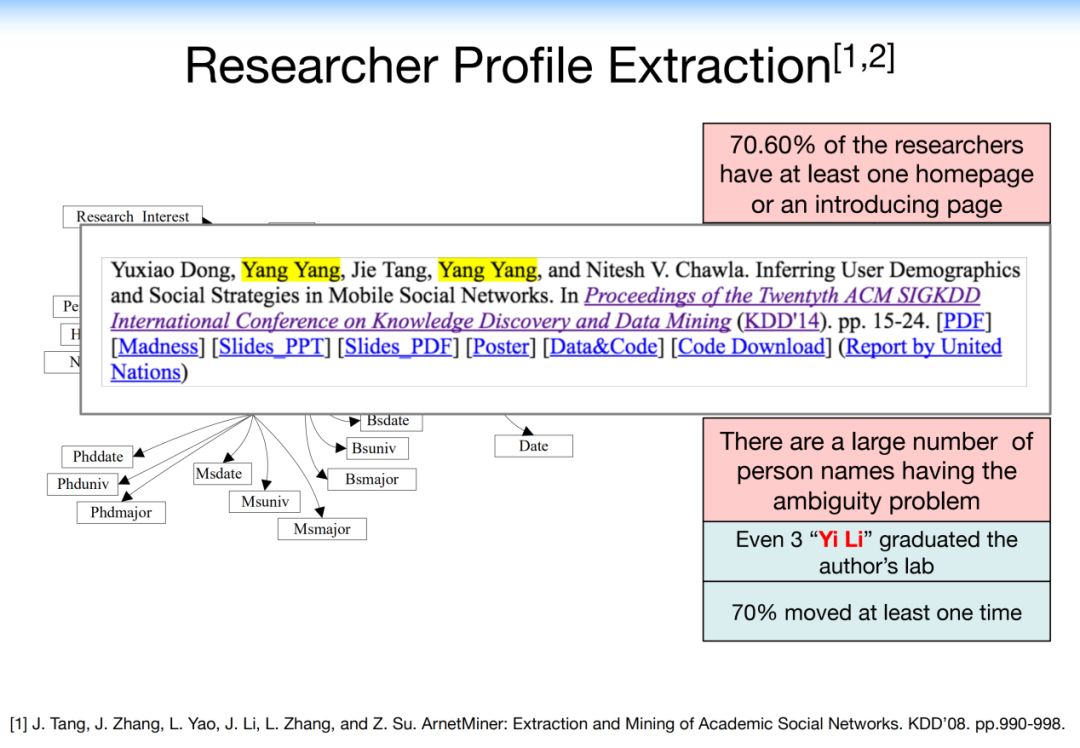
4.3.1 Researcher Profile Extraction
从Web准确提取基于语义的配置文件信息以及处理名称歧义问题。多维度的、多网络的数据集成给用户提供了非常好的用户体验。
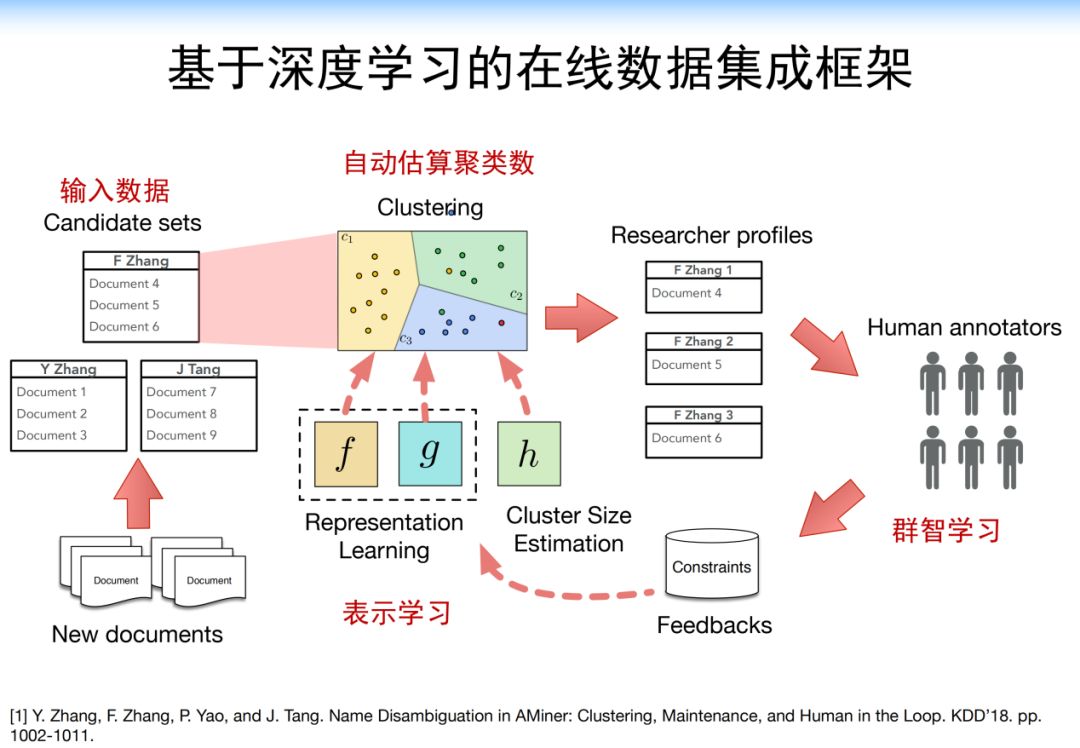

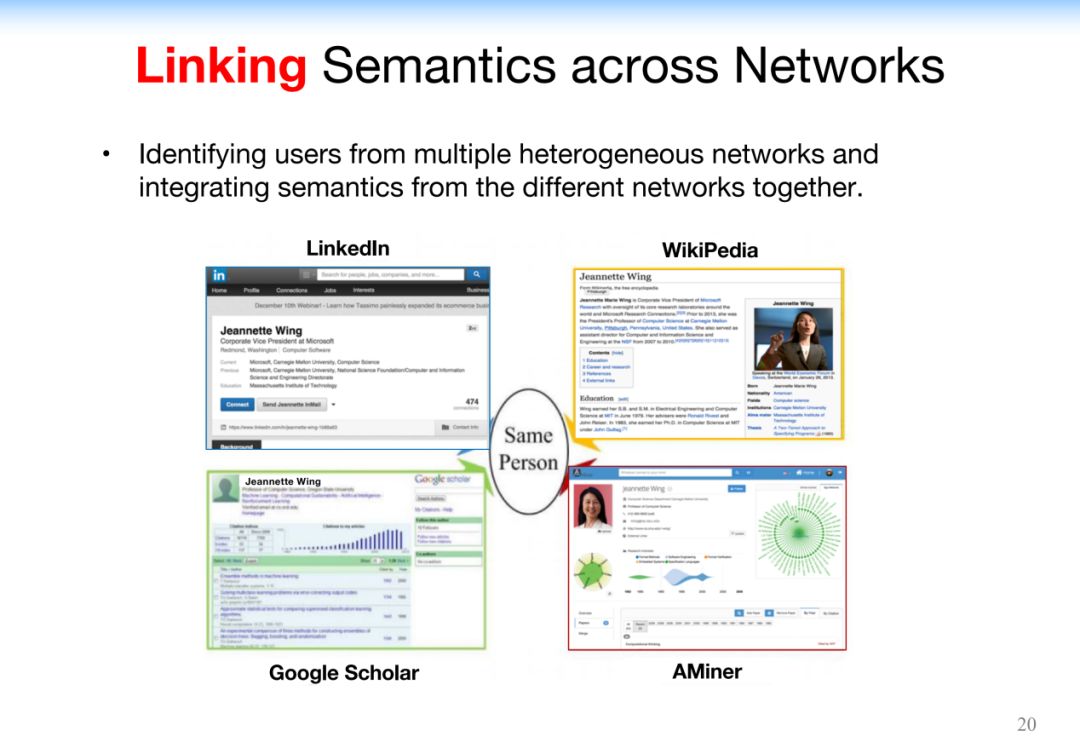

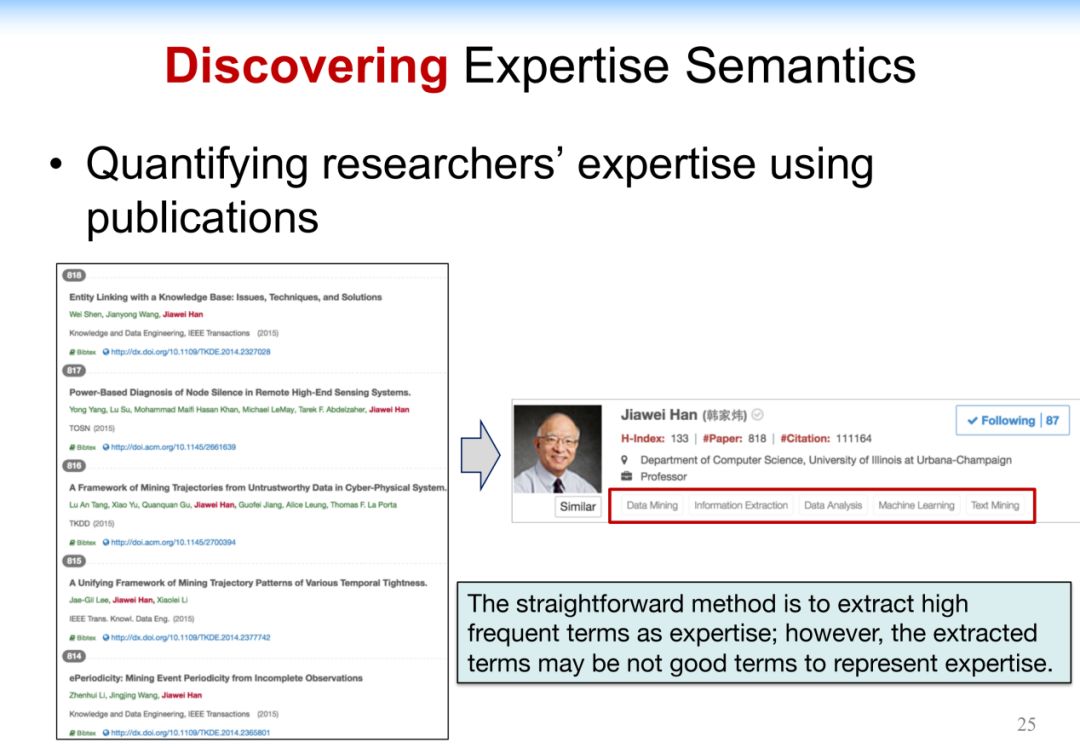
4.3.2 Discovering Expertise Semantics
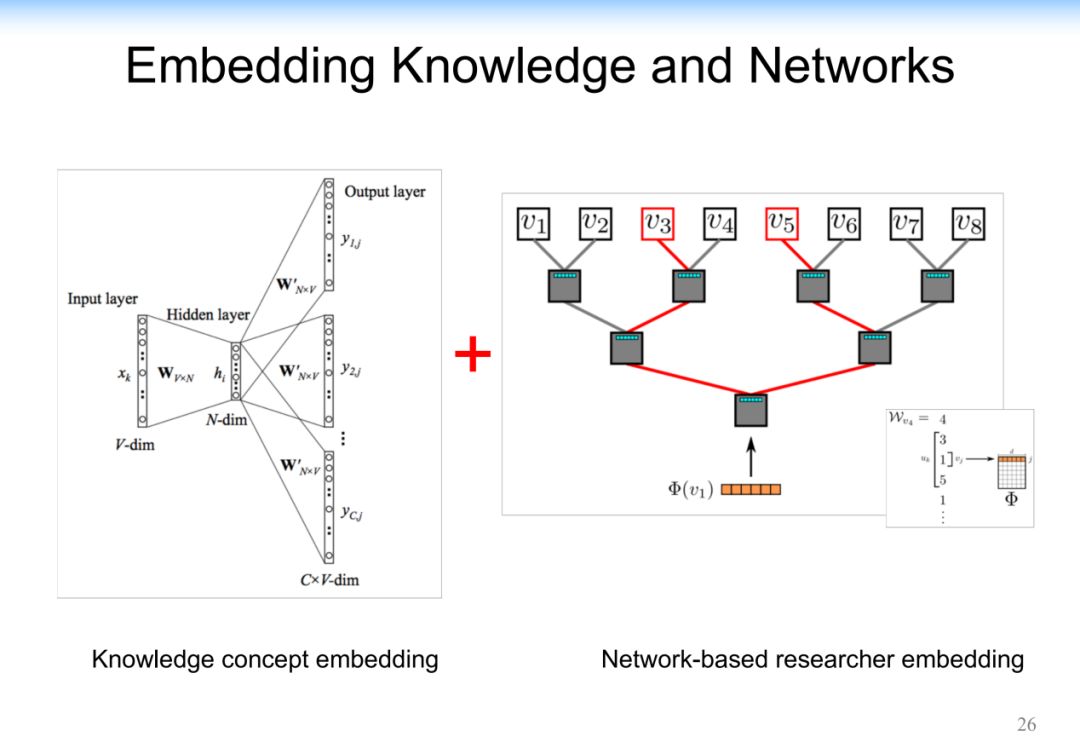
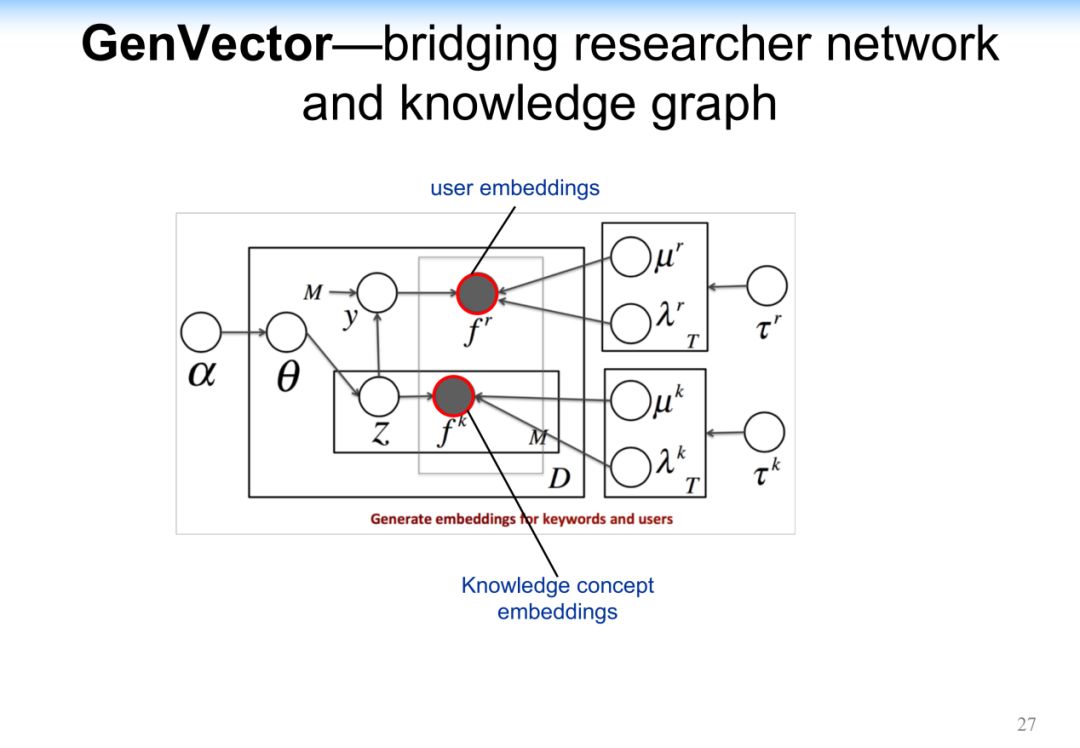
利用一些嵌入的方式精确的寻找专家的研究兴趣和研究领域。
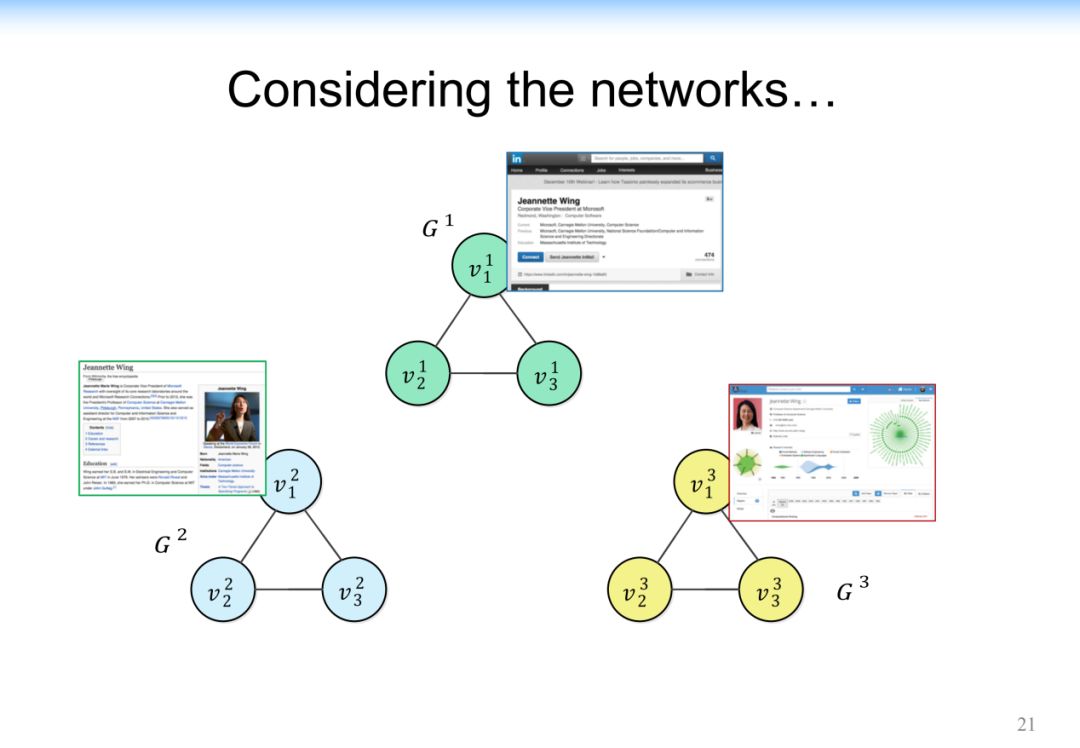
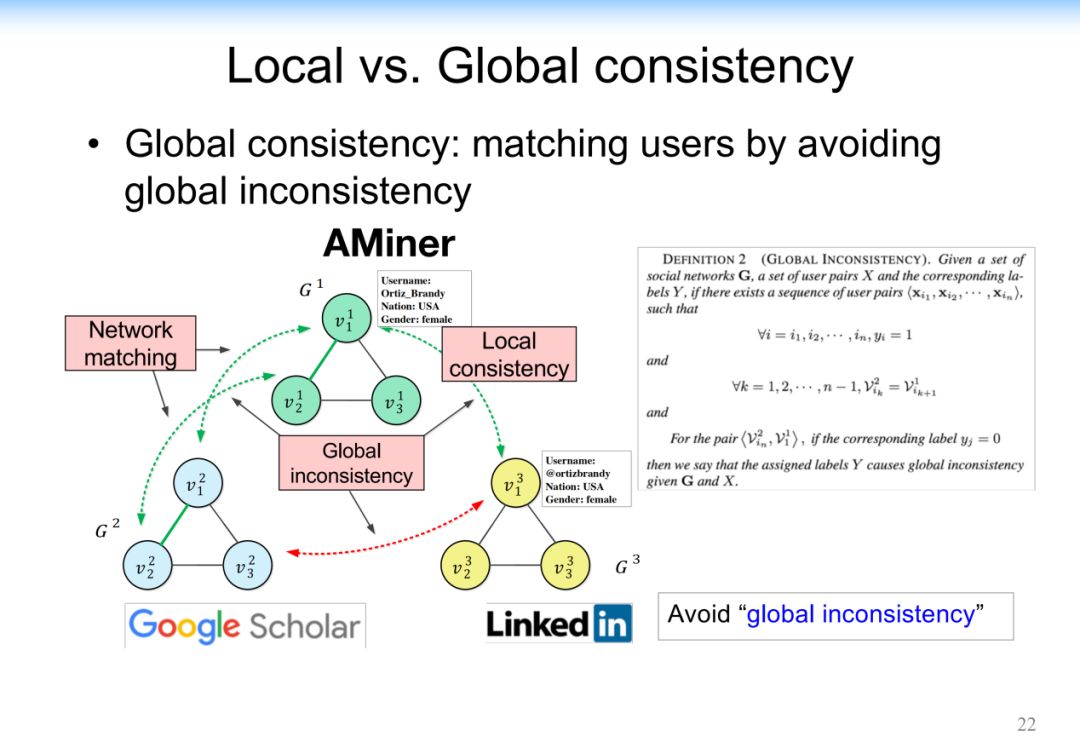
4.3.3 Discovering Network Semantics
在专家网络中通过论文、合作的时间、地点,多方位的做出一个判断,同时对他的老师和学生的身份做出预测。
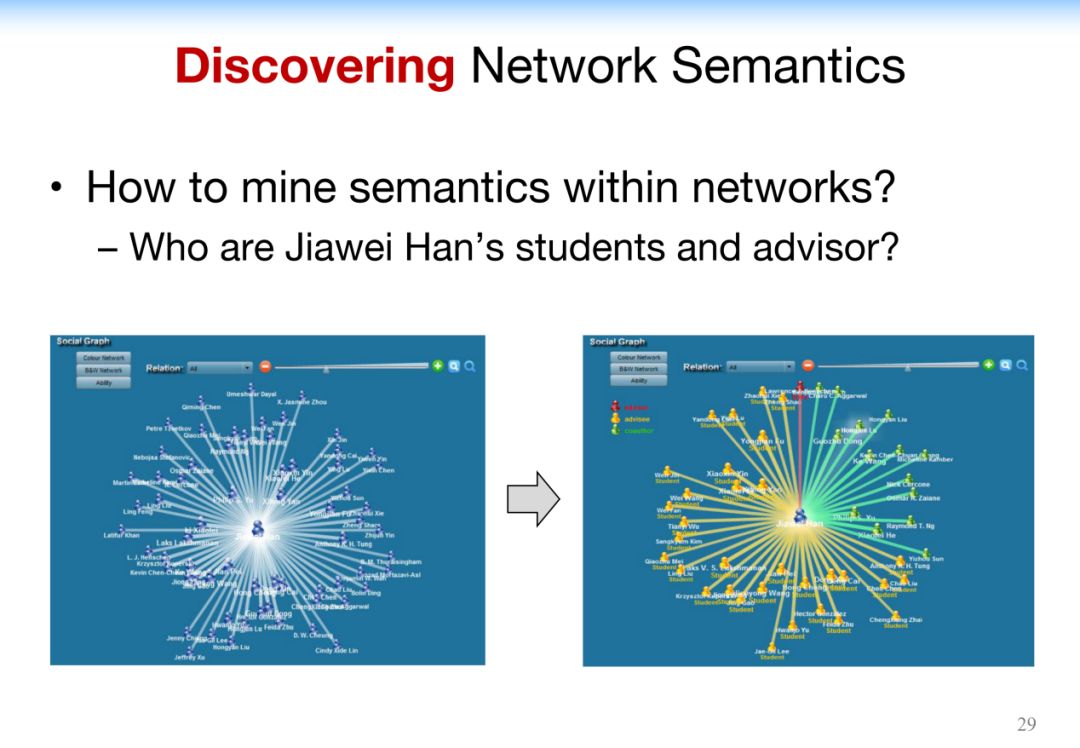
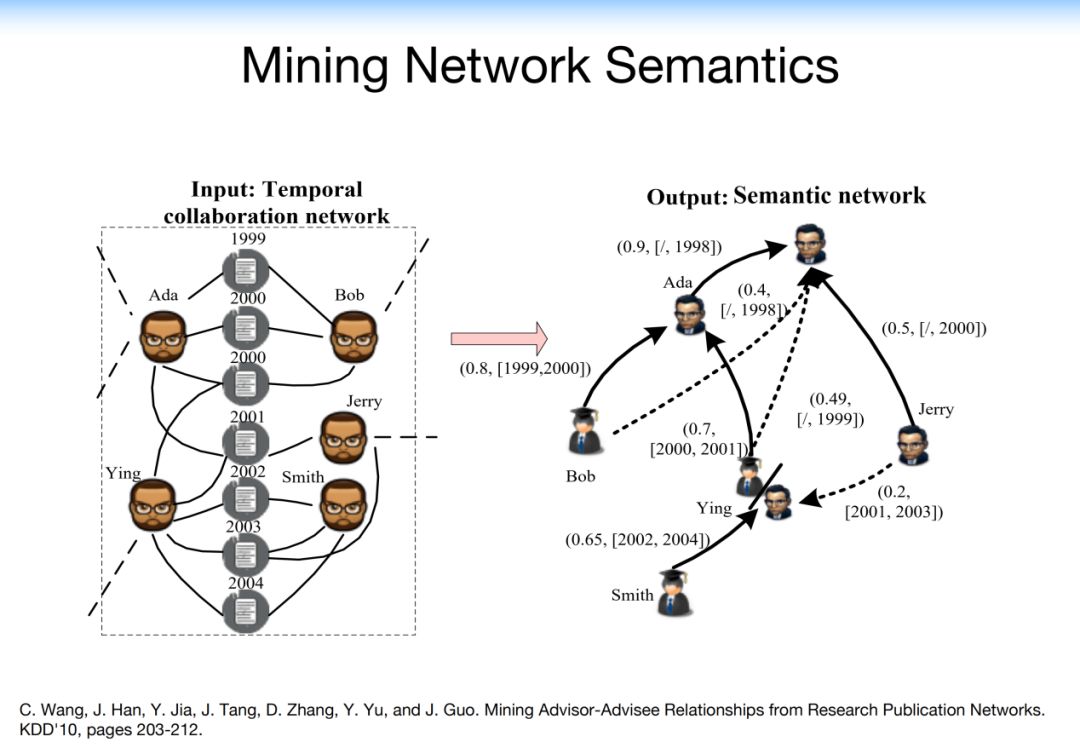
这里可以看到,系统把学生跟老师做了不同颜色的区分,当然其中还有些其他的用户,比如既不是老师,也不是学生的用户,可能只是合作者,这就形成了一个带有身份的学者网络。
最后分享一个视频,这段视频是基于在半个世纪以来全球的顶尖的学者在全球的流动情况建立的一个视频。
本文为录音整理,经本人确认授权后发表
声明:本文来自农业图书情报,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
