
摘要:用户在设置密码时总是会以某一种形式来组合密码,使得密码猜测成为新的研究方向。目前成熟的技术是基于统计概率的方法,运算量大,耗时长。随着深度学习的兴起,运用递归神经网络生成密码的技术被证明是更加有效的。然而,目前基于深度学习的研究仅仅针对单一数据集,数据量受限,使得跨数据集的命中率不高。因此,提出了基于单数据集的密码生成模型PL(PCFG+LSTM)。相比LSTM,PL提升单数据集的命中率16%~30%。此外,提出了基于多数据集的对抗生成模型GENPass,相比简单混合多个数据集,命中率提升超过20%。
0 引 言
密码是目前身份认证的主流手段,且在短期内不会被取代。出于方便,用户通常不会设置复杂、不便于记忆的密码。因此,可以认为密码是存在某种规律性的[1]。由于对于密码保护的疏忽,目前已经发生了多起大规模的密码泄露事件。本文对于密码的分析,均是基于历史上国内外各个网站的泄漏密码。
目前比较成熟的密码猜测技术主要是马尔科夫模型(Markov models)[2]和概率上下文无关文法(Probabilistic Context-Free Grammars)[3]。这两种技术都是依据概率模型,存在计算量庞大、耗时长的问题。递归神经网络(Recurrent Neural Network)[4]是分析文本的常用方法。Melicher等人证实,基于神经网络的训练效率被证实要优于常用的概率模型方法[5]。然而,Melicher的研究中,针对单数据集对密码的格式、长度进行了约束,因此应用范围有限。文献[6]中提出基于对抗生成网络(Generative Adversarial Network)的模型passGAN,进一步提升了密码生成能力。然而,和Melicher的研究相同,passGAN只能提升单数据集的测试命中率,在跨数据集的测试中表现较差。
本文提出一种基于多数据集的密码生成模型GENPass(Generating General Passwords)。GENPass的目标是生成具有泛化特征的密码字典,从而提高对于未知密码集的命中率。GENPass可以同时提升单数据集和多数据集的命中率。单数据集的命中率由PL(PCFG+LSTM)保证。密码首先依据PCFG的策略进行标签替换,替换后的标签序列再进行LSTM训练,最后再将标签通过随机采样替换回密码。基于PL模型,本文提出GENPass模型来提升多数据集的命中率。GENPass运用对抗生成来消除不同数据集之间的专有特征,保留泛化特征,从而保证生成的密码具有普遍性。
本文的贡献主要有以下两个方面:
(1)提出PL(PCFG+LSTM)模型,将密码训练由以字符为单位提升到以单词为单位,从而大大提升单数据集的命中率;
(2)提出GENPass模型,将训练集的数量由一个变为多个,基于多数据集学习泛化的密码特征,从而提升对于未知数据集的测试命中率。
1 背景
本章节首先介绍传统的密码猜测方法并分析这些方法的优缺点,随后介绍近几年深度学习在该领域的应用以及发展。
1.1 传统密码猜测方法
通常密码不会以明文的形式传输与存储[7],对密码进行哈希运算是常用的操作。Hashcat[8]和John the Ripper(JtR)[9]是两个针对哈希码破解的常用工具。这两个工具能够借助GPU提高哈希码的计算速度,但要破解出密码必须基于一个已知的密码字典,通过暴力匹配字典中的每一个密码找出目标密码。换而言之,如果目标密码不在字典中,将无法破解出信息。因此,这两个工具提供了一些密码变异的方法来扩大字典,如增加、修改、删除几位字符等操作。然而,这些操作并不智能,实际应用效果不明显。
基于马尔科夫模型的密码猜测在2005年最早提出[10]。马尔科夫模型的核心概念是用空间换时间,通过大量的统计信息,依据前文推测下一个字符出现的概率。
基于概率上下文无关文法(Probabilistic Context-Free Grammars)的密码猜测在2009年被提出[11],可以认为是马尔科夫模型的一种优化。用户在设置密码时通常不会使用随机的字符序列,一般都是有意义的字符串,这些字符串在生成时可以被看成一个整体。原始密码被标签替换,L代表字母,D代表数字,S代表特殊符号,每个标签后的数字表示长度。例如,“password123#”被替换成“L8 D3 S1”。经过替换后的标签串运用马尔科夫模型进行训练。在生成阶段,每次生成一个标签,然后在标签对应的字符串中随机选择一个输出。这种思想被进一步推广到针对个人信息的密码猜测[12-13],将用户的手机号、生日等信息看做一个整体用标签来替换。然而,这种方案并没有改变马尔科夫模型的弊端,依然存在计算量大、存储量大的问题。
1.2 神经网络的发展
递归神经网络模型(RNN)[4]在自然语言处理领域中已有广泛的使用,可以根据时间序列数据进行建模,从而处理数据,如文本预测、语义分析等。
传统递归神经网络模型存在梯度爆炸的缺陷[14],即在长度过长的情况下,模型的训练能力下降。一个训练文本中,如果具有关联性的两个词在文本中相隔较远,则模型无法找到其关联性。这一问题又称长时依赖问题。LSTM模型[15]是传统递归神经网络的一种变形,可以有效解决长时依赖问题。LSTM在RNN模型的基础上添加了一个“门”概念,通过“门”来控制是否遗忘或记忆之前的信息,从而解决长文本导致的梯度爆炸问题。
LSTM具体公式如下:



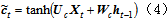


LSTM模型的单元(简称细胞)中,it 、ft 和ot 分别是记忆门、遗忘门和输出门;每个细胞的输出有两个值,ct 表示细胞状态,ht 表示细胞输出。其中,⋅为向量内积,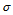 为sigmoid函数。遗忘门的作用是通过来决定什么样的信息会被抛弃。记忆门的作用是决定什么样的信息会被留下。LSTM模型通过遗忘门和记忆门的设计减少梯度爆炸问题,解决传统RNN中的长时依赖问题。
为sigmoid函数。遗忘门的作用是通过来决定什么样的信息会被抛弃。记忆门的作用是决定什么样的信息会被留下。LSTM模型通过遗忘门和记忆门的设计减少梯度爆炸问题,解决传统RNN中的长时依赖问题。
对抗生成网络(Generative Adversarial Network,GAN)[16]是深度学习领域的又一个突破。GAN由一个生成器G和辨别器D组成,生成器G不断生成假数据,由辨别器D来判断数据是由G生成的假数据还是真数据。通过不断的对抗训练,使得D无法辨别G生成的数据的真假。GAN已经在图像领域取得了非常大的成就,然而并不能直接应用于文本的生成。因此,本文借鉴GAN的对抗生成思想,来实现多数据集的密码生成。
1.3 基于神经网络的密码猜测
基于神经网络的密码猜测开始于2016年Melicher等人提出运用LSTM来生成密码[5],文中证明神经网络能够更快、更准地猜测密码。然而,Melicher等人限制了密码的格式,使得生成的密码不具有广泛性。2017年,Hitaj等人提出PassGAN[6],运用GAN来生成密码。实验结果表明,PassGAN能够生成一些传统工具无法生成的密码。然而,这些密码并不一定匹配真实用户的习惯,在命中率的测试上,与传统方式相比并没有明显优势。在目前已有的基于神经网络的密码猜测方法中,重点均放在了提高单数据集的命中率。而实际环境中更多的是跨域攻击,因此跨数据集的数据更为重要。本文将重点放在跨数据集的数据方面,与已有的工作有明显不同。
2 系统概述
本章节将介绍文本解决的主要问题,并详细描述为了解决这些问题而设计的PL(PCFG+LSTM)和GENPass模型结构。
2.1 问题描述
研究密码猜测并不是为了破解特定密码,而是从宏观上提高训练和测试集之间的重合度。密码猜测有两种类型的测试:一种称为同站测试,其训练集和测试集是相同的;另一种称为跨站测试,其训练集和测试集是不同的。在背景介绍中已经提到,以前的研究工作都意在提高同站测试的命中率,其在跨站测试中的表现很差。然而,跨站攻击是黑客破解数据库的主要手段,这方面的技术能力需要提高。此外,历史上已经发生了多起密码泄露事件,但是每个数据集对于深度学习模型来说都不够大,不足以学习到足够的用户习惯。
工作中试图从多个数据集中生成“泛化”密码字典,以提高跨站测试中密码猜测的性能。所谓泛化,是指生成的密码具有通用性,通过学习多个数据集来获取其中共同的特征,而非各个数据集中特有的一些特征。跨站测试的目标是针对一个未知的数据集提高命中率,因此某个数据集特有的特征不利于提高跨站测试中的命中率,只有通用的特征才能提高命中率。GENPass的结构设计就是为了消除不同数据集中的特有特征,利用分类器过滤有明显偏向的密码。例如,某个密码被分类器判定为明显属于A数据集,则认为其包含A数据集的特有特征。如果分类器无法判定某个密码属于A数据集还是B数据集,则认为其包含A和B的共有特征。
2.2 PL(PCFG+LSTM)
因为密码总是有意义的几段字符的组合,PCFG将密码划分为几个不同的部分。例如,“password123”可以分为两个标签“L8”和“D3”。之前的研究表明,这会提高猜测的准确性。同时,神经网络可以检测到标签之间隐藏的关系,这是马尔科夫模型无法检测到的。因此,本文将这两种方法结合,提出了一种新模型——PL模型。
2.2.1 预处理
密码首先被编码为几个标签,每个标签由一个字符(L、D、S)和一个数字组成。其中,L代表字符,D代表数字,S代表特殊字符,数字代表序列的长度。例如,“$Password123”将表示为“S1 L8 N3”,详细规则显示在表1中。预处理密码时会生成一个表,同于统计每个字符串出现的次数。例如,统计了Myspace中的所有L8字符串,发现“password”出现了58次,“iloveyou”出现了56次,依此类推。这个表格的统计数据将会在权重选择中使用。

2.2.2 生成
将预处理后的密码即标签序列送入LSTM模型中进行训练,并通过LSTM模型生成标签。LSTM的结构与Melicher等人[5]使用的网络结构相同。
2.2.3 权重选择
当确定下一个标签时,将根据预处理期间生成的表格选择一个字符串进行替换。实验表明,如果每次选择最高权重输出,则会生成大量重复密码。所以,通过随机采样选择字符串。这种随机采样可以确保选择的字符串有较高的概率,但又不会出现大量重复的情况。
2.3 GENPass
由于不同的密码数据集具有不同的特征和不同的长度,因此简单的混合多个数据集反而会混淆特征,使得模型难以学习到通用的特征。实验结果也证实了这一推论。为了解决多数据集的训练问题,设计了GENPass-pro模型,总体设计如图1所示。

2.3.1 n 个PL模型的独立预测
共有n 个PL模型,分别学习不同的密码库,并分别训练每个模型。因此,给定输入,模型可以输出具有其自身特征的结果。
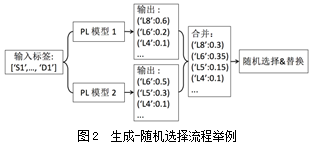
2.3.2 带权重的随机选择过程
假设概率分布p 表示每个数据集的权重,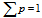 ,不同PL模型的输出概率分布应乘以该数据集的权重。图2假设两个模型的权重相同,则两个输出在合并时需要乘以0.5的权重,然后进行随机选择。选择过程采用随机采样,确保高权重的标签被高概率选择。替换同样采用随机采样,依据预处理时各个字符串的出现频率。
,不同PL模型的输出概率分布应乘以该数据集的权重。图2假设两个模型的权重相同,则两个输出在合并时需要乘以0.5的权重,然后进行随机选择。选择过程采用随机采样,确保高权重的标签被高概率选择。替换同样采用随机采样,依据预处理时各个字符串的出现频率。
2.3.3 分类器
分类器是由原始密码训练的CNN分类。分类器的结构采用成熟的分类模型[17]。给定密码,分类器可以给出密码来自不同数据集的概率分布。分类器处理的是生成的完整密码,而不是标签序列。只有在生成结束字符‘\n’时,一个完整的密码才会被送入分类器,并将新生成的密码与先前生成的4个密码组合在一起,作为分类器的输入。由于单个密码不足以提取特征,经过实验后认为5个密码一组作为输入是一种比较合理的方式。
2.3.4 鉴别器
辨别器的作用是判断分类器的输出,即概率分布是否接近合理分布。例如,某一个密码的特征非常偏向某一个数据集,则认为这个密码具有特定特征而非普遍特征。引入Kullback-Leibler散度[18]来描绘两个分布之间的距离,KL散度为:
训练过程中,使用梯度下降使P 接近Q 。分配P 首先是随机生成的。每次迭代中,GENPass生成10个新密码。这些密码被送到分类器,结果记录为Qi(i=1,2,…,10) 。将这些结果的平均值表示为分类器Q 的输出,使用KL散度作为损失函数。通过梯度下降法来更新P ,使得P 快速接近Q 。认为当损失小于0.001时,分布是稳定的。当训练完成后,P 的值确定下来。经过实验,设定通过的标准是P 与Q 的KL散度是小于0.1。
图3是分类器到辨别器的整个流程举例说明。假设新生成的密码S 为“abcdef1@34”。它会和之前生成并通过辨别器的4个密码组合在一起,作为分类器的输入。分类器会输出一个分布Q ,假设Q 为(0.4,0.6),P 为(0.4,0.6),则KL散度为0,则S 可以输出;若Q 为(0.1,0.9),则KL散度超过0.1,S 被丢弃。

3 实验及讨论
3.1 实验数据
实验数据均来自于历史上世界各网站的泄露密码,均是密码研究最常用的四个数据集。具体的实验数据见表2。

3.2 测试和评价
3.2.1 PL测试方案
为了测试PL模型,分别选取Myspace和phpBB作为训练集,生成若干长度的密码字典。测试分为两种形式:第一种是同站测试,即训练集和测试集的数据来自同一个数据集,其中70%作为训练数据,剩余的30%作为测试数据;第二种是跨站测试,即训练集和测试集的数据来自不同的数据集,测试集中随机选取10%的密码。评价标准为命中率,即生成的密码与测试集的交集占测试集的比例。为了消除合理的波动,同一模型将生成10组长度相同的密码字典,分别计算命中率后取平均值。
3.2.2 GENPass测试方案
为了测试GENPass模型,选取Myspace和phpBB作为训练集,RockYou和LinkedIn作为测试集。测试方法和评价标准与3.2.1中一致。此外,分别用PL和LSTM训练MySpace、phpBB,用来和GENPass作对比。额外的,运用PL训练Myspace和phpBB直接混合后的数据集作为对比数据。
3.3 PL模型评价
分别用PL和LSTM训练Myspace和phpBB,并进行了同站测试,结果如图4所示。其中,PL(Myspace)表示用PL来训练Myspace数据集得到的结果,其余同理。从图4可以明显发现,PL模型的命中率要明显高于LSTM。尽管随着生成密码的数量增加,两者的准确率会最终接近相同,但PL可以生成更少的数据来获得相同的命中率。例如,用LSTM来训练Myspace,需要生成1012个密码才能达到50%的准确率,而PL模型仅需要生成107个密码。

在跨站测试中,分别用PL和LSTM训练Myspace和phpBB,四个模型再分别生成数据,对RockYou和LinkedIn计算命中率。表3展示了生成密码量在106和107时的数据。

跨站测试的准确率要明显低于同站测试,因为各个数据集的特征都不相同,而仅训练一个数据集不足以猜测其他数据集。从实验结果可以看到,PL要比LSTM的准确率高16%~30%,表明用户习惯设置有意义的字符串的现象在各个数据集中通用,且PL模型在这方面能够比LSTM更优秀。
3.4 GENPass模型评价
GENPass基于多数据集生成密码。首先根据式(7)迭代计算Myspace和phpBB之间的概率分布 。迭代的过程如图5所示,横坐标为训练次数,纵坐标为KL散度。经过约450次迭代,KL散度值趋于稳定,最终得到Myspace和phpBB之间的分布为(30.004%,69.996%),表明phpBB的权重更重。同站测试中发现,phpBB的特征相对分散,而Myspace的特征比较集中,导致在生成相同数量密码的情况下,Myspace的命中率普遍高于phpBB。因此,在多数据集情形下,为了能够汲取更多phpBB的特征,应当给予其更大的关注。
图6和图7展现了GENPass与其他模型的性能对比。其中,PL(Myspace)-RockYou表示用PL模型训练Myspace生成的密码集来测试RockYou,其余同理。可以看到,GENPass的表现几乎一直是最佳的,用PL单独训练Myspace得到的结果次之,说明Myspace具有较好的特征,与其他数据集重合度比较高。直接将Myspace和phpBB混合后训练,得到的命中率更低,说明盲目增大数据量而没有辨别的学习,结果适得其反。结果显示,使用GENPass可以比简单混合两个训练集提升超过20%的命中率。
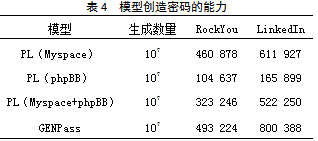
最后,衡量GENPass创造有效密码的能力,结果如表4所示。以第一行为例,表示用Myspace作为训练集,运用PL模型来训练,生成107长度的密码字典,其中有460 878个不在Myspace中但却出现在RockYou中,有611 927个不在Myspace中但出现在了LinkedIn中。这说明了模型创造有效密码的能力,即生成的密码不在训练集中但出现在了跨站测试集中。从表4中可以看到,GENPass的创造能力同样是最出色的。
4 结语
本文介绍一种基于多数据集的密码生成模型GENPass。GENPass借用PCFG和GAN的思想,通过递归神经网络训练,提高了单数据集的命中率和多数据集的泛化性。GENPass的核心是神经网络,在此之前,大部分密码研究均是基于马尔科夫模型。随着神经网络的兴起,模型有了更好理解字符之间关系的能力,从而能够生成更贴近真实数据的密码。
本文首先提出PL(PCFG+LSTM)模型将密码的训练由字符级提升至单词级。在单数据集的测试中,PL模型取得50%的命中率仅需要生成107个密码,而单纯用LSTM需要生成1012个密码;在跨数据集的测试中,PL同样能够相比LSTM提高16%~30%。更进一步,本文将单数据集的提升拓展到多数据集,提出了GENPass模型,使用Myspace和phpBB作为训练集,RockYou和LinkedIn作为测试集。实验结果表明,使用GENPass可以比简单混合两个训练集提升超过20%的命中率。
密码是身份认证的最主要方式,短期内不会被生物识别完全取代。研究密码不是为了破解而获得私利,更重要的是能够对密码复杂度进行准确判断,从而引导用户设置更安全的密码。然而,数据量是密码研究的最重要问题。由于各家公司不会主动把用户数据公布出来,仅仅凭借目前泄漏出来的数据,不足以训练出一个非常完备的模型。为了解决数据量不足,迁移学习可以在未来进一步研究。
参考文献:
[1] Li Z,Han W,Xu W.A Large-Scale Empirical Analysis of Chinese Web Passwords[C].Usenix Security,2014:559-574.
[2] Ma J,Yang W,Luo M,et al.A Study of Probabilistic Password Models[C]. Security and Privacy IEEE, 2014 :689-704.
[3] Weir M,Aggarwal S,Medeiros B D,et al.Password Cracking Using Probabilistic Context-Free Grammars[C].Security and Privacy,2009:391-405.
[4] Sutskever I,Martens J,Hinton G E.Generating Text with Recurrent Neural Networks[C].Proceedings of the 28th International Conference on Machine Learning(ICML-11),2011:1017-1024.
[5] Melicher W,Ur B,Segreti S M,et al.Fast,Lean and Accurate:Modeling Password Guessability Using Neural Networks[C].Proceedings of USENIX Security,2016.
[6] Hitaj B,Gasti P,Ateniese G,et al.PassGAN:A Deep Learning Approach for Password Guessin[Z].2017.
[7] Bishop M,Klein D V.Improving System Security Via Proactive Password Checking[J].Computers & Security, 1995, 14(03):233-249.
[8] STEUBE J.Hashcat[EB/OL].(2017-11-07)[2018-08-11]. https://hashcat.net/oclhashcat/.
[9] PESLYAK A.John the Ripper[EB/OL].(2013-05-30)[2018-08-11]. http://www. openwall.com/john/.
[10]Narayanan A,Shmatikov V.Fast Dictionary Attacks on Passwords Using Time-Space Tradeoff[C].ACM Conference on Computer and Communications Security, 2005 :364-372.
[11]Weir M,Aggarwal S,Medeiros B D,et al.Password Cracking Using Probabilistic Context-Free Grammars[C].Security and Privacy,2009:391-405.
[12]Wang D,Zhang Z,Wang P,et al.Targeted Online Password Guessing:An Underestimated Threat[C].ACM Sigsac Conference on Computer and Communications Security, 2016 :1242-1254.
[13]Li Y,Wang H,Sun K.A Study of Personal Information in Human-Chosen Passwords and Its Security Implications[C].Computer Communications, IEEE INFOCOM 2016-The 35th Annual IEEE International Conference on, 2016:1-9.
[14]Lipton Z C,Berkowitz J,Elkan C.A Critical Review of Recurrent Neural Networks for Sequence Learning[Z]. 2015.
[15]Hochreiter S,Schmidhuber J.Long Short-Term Memory[J].Neural Computation, 1997, 9(08):1735-1780.
[16]Goodfellow I J,Pouget-Abadie J,Mirza M,et al.Generative Adversarial Nets[C].International Conference on Neural Information Processing Systems, 2014 :2672-2680.
[17]Zhang X,Zhao J,Lecun Y.Character-level Convolutional Networks for Text Classification[C].International Conference on Neural Information Processing Systems, 2015 :649-657.
[18]Hershey J R,Olsen P A.Approximating the Kullback Leibler Divergence between Gaussian Mixture Models[C].IEEE International Conference on Acoustics,Speech and Signal Processing,2007:317-320.
作者简介:
夏之阳,上海交通大学 网络空间安全学院,硕士,主要研究方向为无线网络安全、应用软件安全;
易 平,上海交通大学 网络空间安全学院,博士,副研究员,主要研究方向为无线网络、信息安全、深度学习。
(本文选自《通信技术》2019年第一期)
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
