
来源:towardsdatascience
作者:Connor Shorten 编辑:肖琴
本文选择的 10 篇 GAN 论文包括:
DCGANs
Improved Techniques for Training GANs
Conditional GANs
Progressively Growing GANs
BigGAN
StyleGAN
CycleGAN
Pix2Pix
StackGAN
Generative Adversarial Networks
DCGANs — Radford et al. (2015)
我建议你以 DCGAN 这篇论文来开启你的 GAN 之旅。这篇论文展示了卷积层如何与GAN 一起使用,并为此提供了一系列架构指南。这篇论文还讨论了 GAN 特征的可视化、潜在空间插值、利用判别器特征来训练分类器、评估结果等问题。所有这些问题都必然会出现在你的 GAN 研究中。
总之,DCGAN 论文是一篇必读的 GAN 论文,因为它以一种非常清晰的方式定义架构,因此很容易从一些代码开始,并开始形成开发 GAN的直觉。
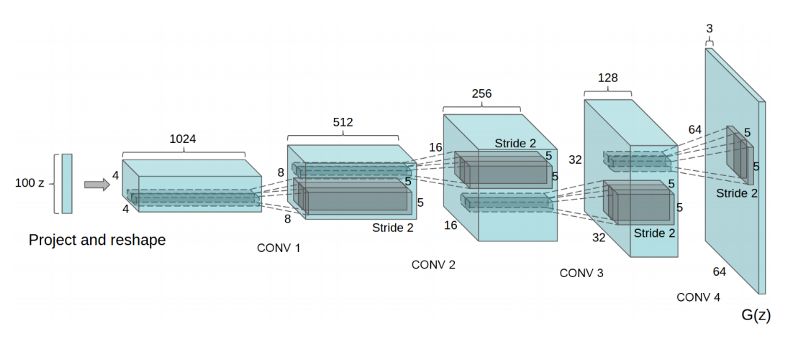
DCGAN 模型:具有上采样卷积层的生成器架构
论文:
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, Soumith Chintala
https://arxiv.org/abs/1511.06434
改进 GAN 训练的技术 —— Salimans et al. (2016)
这篇论文 (作者包括 Ian Goodfellow) 根据上述 DCGAN 论文中列出的架构指南,提供了一系列建议。这篇论文将帮助你了解 GAN 不稳定性的最佳假设。此外,本文还提供了许多用于稳定 DCGAN 训练的其他机器,包括特征匹配、 minibatch 识别、历史平均、单边标签平滑和虚拟批标准化。使用这些技巧来构建一个简单的 DCGAN 实现是一个很好的练习,有助于更深入地了解 GAN。
论文:
Improved Techniques for Training GANs
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen
https://arxiv.org/abs/1606.03498
Conditional GANs — Mirza and Osindero (2014)
这是一篇很好的论文,读起来很顺畅。条件 GAN(Conditional GAN) 是最先进的 GAN之一。论文展示了如何整合数据的类标签,从而使 GAN 训练更加稳定。利用先验信息对 GAN 进行调节这样的概念,在此后的 GAN 研究中是一个反复出现的主题,对于侧重于 image-to-image 或 text-to-image 的论文尤其重要。
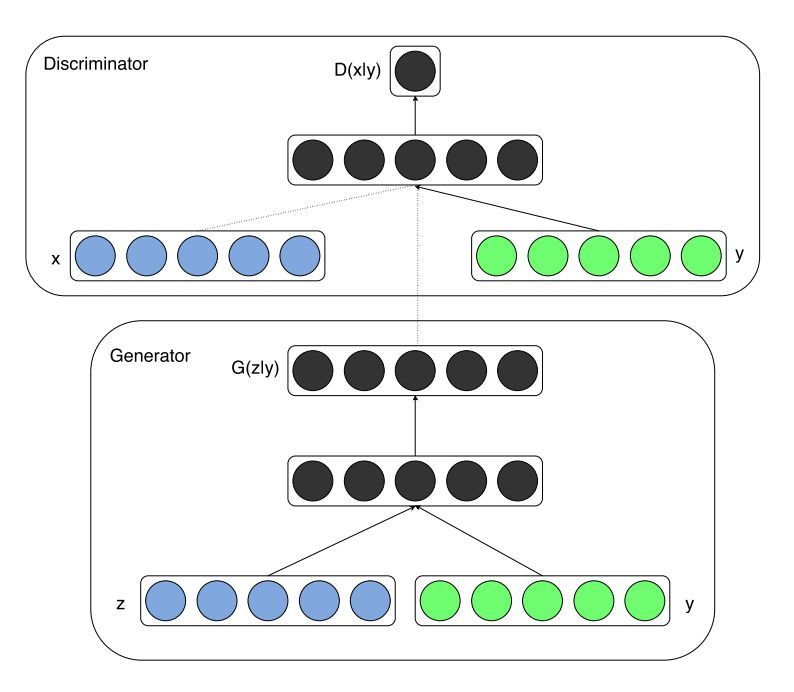
Conditional GAN 架构:除了随机噪声向量 z 之外,类标签 y 被连接在一起作为网络的输入
论文:
Conditional Generative Adversarial Nets
Mehdi Mirza, Simon Osindero
https://arxiv.org/abs/1411.1784
Progressively Growing GANs— Karras et al. (2017)
Progressively Growing GAN (PG-GAN) 有着惊人的结果,以及对 GAN 问题的创造性方法,因此也是一篇必读论文。
这篇 GAN 论文来自 NVIDIA Research,提出以一种渐进增大(progressive growing)的方式训练 GAN,通过使用逐渐增大的 GAN 网络(称为 PG-GAN)和精心处理的CelebA-HQ 数据集,实现了效果令人惊叹的生成图像。作者表示,这种方式不仅稳定了训练,GAN 生成的图像也是迄今为止质量最好的。
它的关键想法是渐进地增大生成器和鉴别器:从低分辨率开始,随着训练的进展,添加新的层对越来越精细的细节进行建模。“Progressive Growing” 指的是先训练 4x4 的网络,然后训练 8x8,不断增大,最终达到 1024x1024。这既加快了训练速度,又大大稳定了训练速度,并且生成的图像质量非常高。
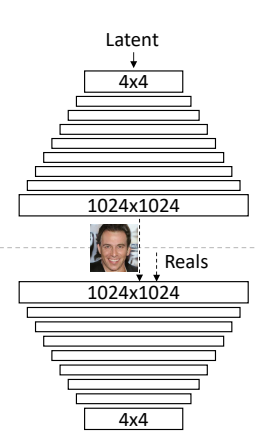
Progressively Growing GAN 的多尺度架构,模型从 4×4 逐步增大到 1024×1024
论文:
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
https://arxiv.org/abs/1710.10196
BigGAN — Brock et al. (2019)
BigGAN 模型是基于 ImageNet 生成图像质量最高的模型之一。该模型很难在本地机器上实现,而且 BigGAN 有许多组件,如 Self-Attention、 Spectral Normalization 和带有投影鉴别器的 cGAN,这些组件在各自的论文中都有更好的解释。不过,这篇论文对构成当前最先进技术水平的基础论文的思想提供了很好的概述,因此非常值得阅读。

BigGAN 生成的图像
论文:
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, Karen Simonyan
https://arxiv.org/abs/1809.11096
StyleGAN — Karras et al. (2019)
StyleGAN 模型可以说是最先进的,特别是利用了潜在空间控制。该模型借鉴了神经风格迁移中一种称为自适应实例标准化 (AdaIN) 的机制来控制潜在空间向量 z。映射网络和 AdaIN 条件在整个生成器模型中的分布的结合使得很难自己实现一个 StyleGAN,但它仍是一篇很好的论文,包含了许多有趣的想法。
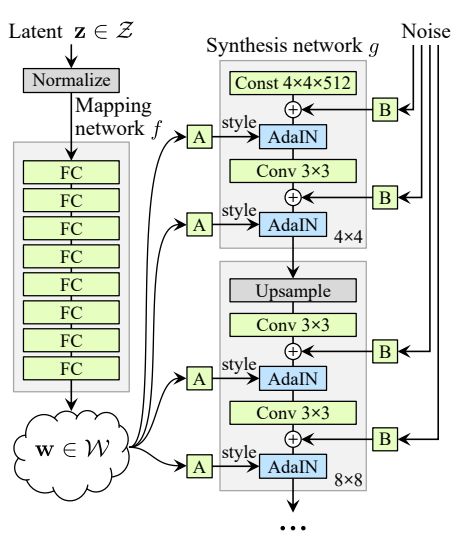
StyleGAN 架构,允许潜在空间控制
论文:
A Style-Based Generator Architecture for Generative Adversarial Networks
Tero Karras, Samuli Laine, Timo Aila
https://arxiv.org/abs/1812.04948
CycleGAN — Zhu et al. (2017)
CycleGAN 的论文不同于前面列举的 6 篇论文,因为它讨论的是 image-to-image 的转换问题,而不是随机向量的图像合成问题。CycleGAN 更具体地处理了没有成对训练样本的 image-to-image 转换的情况。然而,由于 Cycle-Consistency loss 公式的优雅性,以及如何稳定 GAN 训练的启发性,这是一篇很好的论文。CycleGAN 有很多很酷的应用,比如超分辨率,风格转换,例如将马的图像变成斑马。
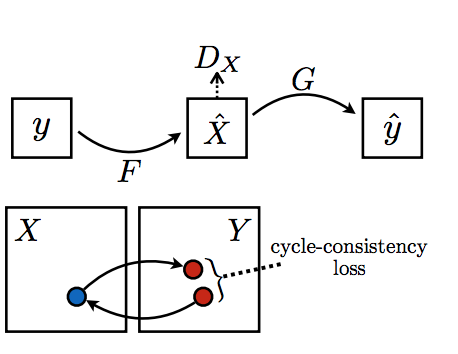
Cycle Consistency Loss 背后的主要想法,一个句子从法语翻译成英语,再翻译回法语,应该跟原来的是同一个句子
论文:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
https://arxiv.org/abs/1703.10593
Pix2Pix — Isola et al. (2016)
Pix2Pix 是另一种图像到图像转换的 GAN 模型。该框架使用成对的训练样本,并在GAN 模型中使用多种不同的配置。读这篇论文时,我觉得最有趣部分是关于 PatchGAN的讨论。PatchGAN 通过观察图像的 70×70 的区域来判断它们是真的还是假的,而不是查看整个图像。该模型还展示了一个有趣的 U-Net 风格的生成器架构,以及在生成器模型中使用 ResNet 风格的 skip connections。 Pix2Pix 有很多很酷的应用,比如将草图转换成逼真的照片。

使用成对的训练样本进行 Image-to-Image 转换
论文:
Image-to-Image Translation with Conditional Adversarial Networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
https://arxiv.org/abs/1611.07004
StackGAN — Zhang et al. (2017)
StackGAN 的论文与本列表中的前几篇论文相比非常不同。它与 Conditional GAN 和Progressively Growing GANs 最为相似。StackGAN 模型的工作原理与 Progressively Growing GANs 相似,因为它可以在多个尺度上工作。StackGAN 首先输出分辨率为64×64 的图像,然后将其作为先验信息生成一个 256×256 分辨率的图像。
StackGAN是从自然语言文本生成图像。这是通过改变文本嵌入来实现的,以便捕获视觉特征。这是一篇非常有趣的文章,如果 StyleGAN 中显示的潜在空间控制与 StackGAN 中定义的自然语言接口相结合,想必会非常令人惊讶。

基于文本嵌入的 StackGAN 多尺度架构背后的想法
论文:
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, Dimitris Metaxas
https://arxiv.org/abs/1612.03242
Generative Adversarial Networks — Goodfellow et al. (2014)
Ian Goodfellow 的原始 GAN 论文对任何研究 GAN 的人来说都是必读的。这篇论文定义了 GAN 框架,并讨论了 “非饱和” 损失函数。论文还给出了最优判别器的推导,这是近年来 GAN 论文中经常出现的一个证明。论文还在 MNIST、TFD 和 CIFAR-10 图像数据集上对 GAN 的有效性进行了实验验证。
论文:
Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
https://arxiv.org/abs/1406.2661
原文链接:
https://towardsdatascience.com/must-read-papers-on-gans-b665bbae3317
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
