摘要:针对目标检测特别是小目标检测问题,首先梳理了目标检测算法的发展与现状,系统性地总结了基于深度学习的目标检测算法研究进展,从精度和速度方面分析了两阶段及单阶段检测算法的优缺点及检测性能;其次作为参考梳理了小目标检测领域的典型数据集,分析在小目标检测难题上的改进算法,提升检测精度和速度,以及获得二者的平衡,该目标也是目前小目标检测改进的方向和面临的挑战;最后对基于深度学习的目标检测应用领域做出展望和预测,为小目标检测问题提供了参考。
关键词:目标检测;深度学习;小目标;机器视觉
近年来,随着人工智能技术的爆炸式发展,机器视觉、深度学习等技术在人脸识别、行人检测、车牌识别、无人驾驶等各个领域得到了广泛的应用。机器视觉的任务是从图像中解析出可供计算机理解的信息,计算机对图像的理解层次主要有三个方面,分类、检测和分割,与图像分类不同,目标检测除了需要实例化类别信息外,还需要获得目标的位置信息,因此更具难度。传统的目标检测算法,多是基于滑动窗口模型,对手工特征进行提取、匹配,存在单一性、计算复杂、适用性不好的缺点,检测精度和速度较差,随着模型的改进和算法的发展,基于深度学习的目标检测技术以网络结构简单高效的特点,超越了传统算法,准确度和效率大幅提升,逐渐成为当前的主流算法。在应用场景方面,无人机、智能化导弹等因任务剖面的特点,获取的图像信息较少,目标特征不明显,小目标检测问题将成为未来民用领域和军事领域亟待解决的难题。本文旨在系统性地总结基于深度学习的目标检测算法研究进展,并分析相关算法的优缺点,结合国内外研究进展,分析在小目标检测难题上的改进算法,并对基于深度学习的目标检测应用领域做出展望和预测。
01 基于深度学习的目标检测算法
1998年Yann Le Cun等提出最早的卷积神经网络结构LeNet5用于手写数字的识别,此后的十几年间神经网络算法一直处于缓慢发展的阶段。2012年Krizhevsky A等提出了网络结构AlexNet,该网络在ImageNet2012挑战赛中一举夺冠,且效果远超传统算法,由此掀起了深度学习算法的热潮 。随着计算机硬件的成熟、计算能力的提高,深度学习框架逐步代替了基于特征的传统检测方法,成为目前目标检测领域的主流算法。根据检测思想的不同,基于深度学习的目标检测算法可分为基于分类的目标检测算法和基于回归的目标检测算法两类。
1.1基于分类的目标检测算法
基于分类的目标检测算法又称两阶段(two-stage)模型,其将检测问题划分为两个阶段,首先选取候选区域(region proposals),然后对候选区域进行分类以及位置调整,从而输出目标检测结果。这类算法的典型代表是基于区域提取的R-CNN系列算法,如R-CNN、SPP-Net 、Fast R-CNN、Faster R-CNN等。
1.1.1 R-CNN
2014年Girshick R等[3]提出基于区域提取的R-CNN算法,成为R-CNN系列目标检测算法的奠基之作。R-CNN算法的具体流程如图1所示,首先获取输入图像,然后利用选择性搜索(Selective Search)算法提取大约2000个自下而上的区域,使用大型卷积神经网络(CNN)计算每个提取区域的特征,最后使用特定的类线性SVM对每个区域进行分类。该方法通过候选区域提取将目标检测问题转换为区域上的分类问题,具有简单、可扩展的优点。虽然R-CNN算法相较于传统目标检测算法性能有大幅度提升,但其也存在诸多缺陷,如训练网络的正负样本候选区域由传统算法生成,使得算法速度受到限制;网络提取约2000个候选区域,并需要对每一个生成的候选区域进行一次特征提取,同时分别进行卷积计算,重复运算过多,制约了算法性能。
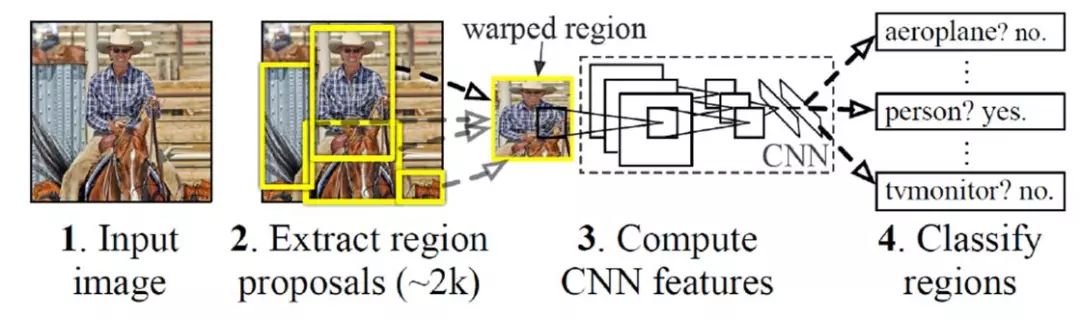
图1 R-CNN算法流程
1.1.2 SPP-Net
针对R-CNN模型对处理候选区域尺寸的限制,2014年He K等人在卷积神经网络中设计了一种空间金字塔池化层(如图2),使卷积神经网络能够处理任意大小的候选区,该层能够从不同大小的特征图中提取相同长度的特征向量,克服了卷积神经网络只能接受固定大小输入的限制,并且改进了卷积神经网络提取图像特征时重复提取的问题,提高了区域提取阶段的运行速度。该网络结合空间金字塔方法实现了CNN网络的多尺度输入,并且只对原图进行一次卷积,节省了大量的计算时间。但是和R-CNN算法一样,训练数据的图像尺寸大小不一致,使候选框的感兴趣区域感受野过大,不可以使用反向传播算法有效地更新权重。
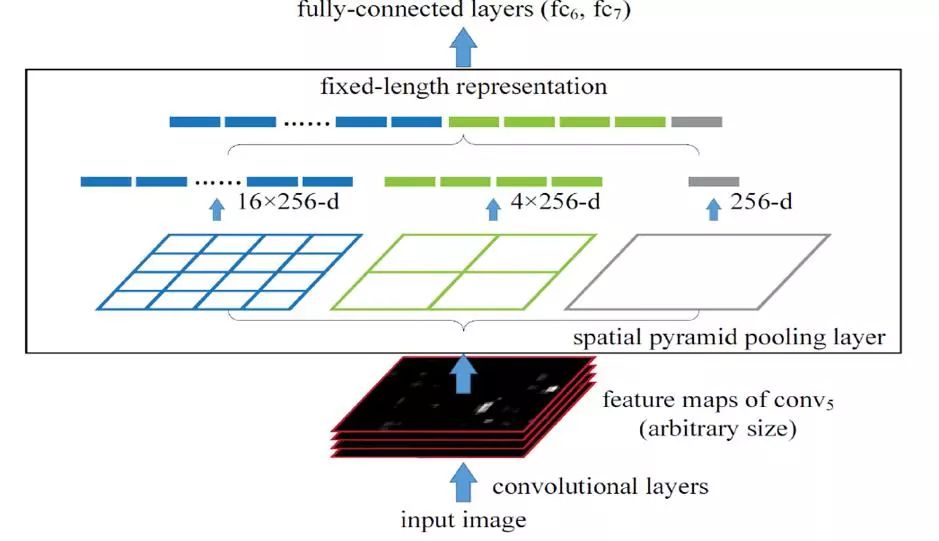
图2 空间金字塔池化层
1.1.3 Fast R-CNN
在SPP-Net算法结构的基础上,2015年Girshick R等又提出一种改进的Fast R-CNN算法,将基础网络在图片整体上运行完毕后,再传入R-CNN子网络,共享卷积运算。Fast R-CNN的主要步骤如图3所示,首先将图像和多个感兴趣区域(RoI)输入到基础卷积网络中,每个感兴趣区域都汇集到一个固定大小的特征映射中,然后通过全连接层(FC)映射到特征向量中。网络每个RoI有两个输出向量:softmax概率和类边界框回归。该方法通过多任务损失对算法进行端到端的训练。但是Fast R-CNN在提取区域候选框时仍使用Selective Search算法,增加了算法耗时,运行速度较慢。
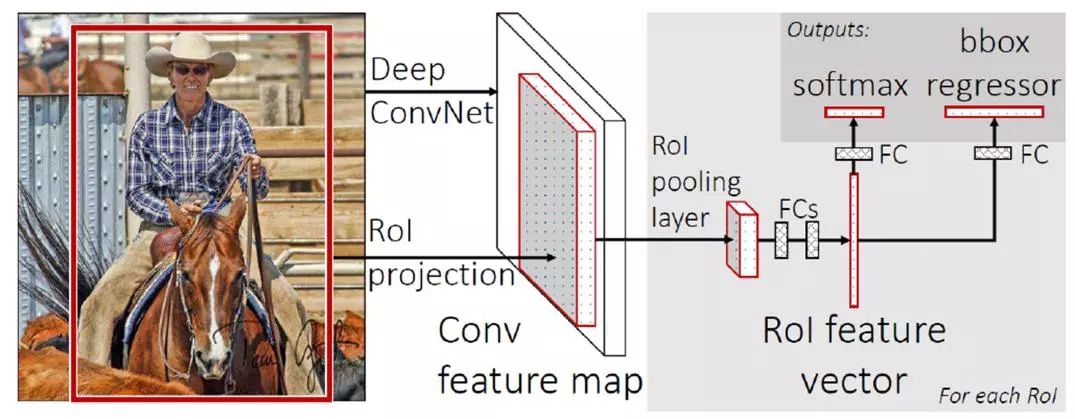
图3 Fast R-CNN算法流程
1.1.4 Faster R-CNN
针对Fast R-CNN算法的缺陷,2015年Ren S等人又提出了Faster R-CNN算法,用候选区域生成网络(Regional Proposal Networks,RPN)代替了选择性搜索Selective Search算法,将目标检测系统分为两个模块,第一个模块是提取候选区域的深度全卷积网络,第二个模块使用基于区域提取的Fast R-CNN检测器,整个系统是一个单个的、统一的目标检测网络。Faster R-CNN算法框架如图4所示,首先将整张图片作为输入,经过卷积计算得到特征层;然后将卷积特征输入到RPN网络,得到候选框的特征信息;接着对候选框中提取出的特征,使用分类器判别是否属于一个特定类;最后对属于某一特征的候选框,用回归器进一步调整其位置。整个网络流程都能共享卷积神经网络提取的特征信息,提高了算法的速度和准确率,从而实现了两阶段模型的深度化。但是在尺寸一定的卷积特征图中,RPN网络能够生成具有多个尺寸的候选框,造成了目标尺寸可变以及固定感受野不一致的问题。
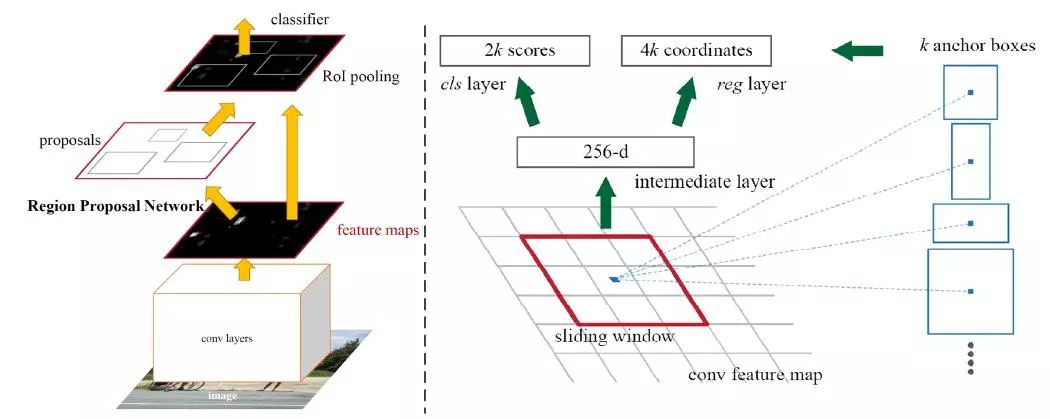
图4 Faster R-CNN目标检测系统框架
1.2基于回归的目标检测算法
以R-CNN算法为代表的两阶段方法经过不断的发展和改善,尤其是加入RPN结构之后,检测精度越来越高,但是基于分类的目标检测算法检测速度较慢,难以满足部分场景对于实时性的需求,因此出现一种基于回归方法的目标检测算法。基于回归的目标检测算法又称单阶段(one-stage)模型,其将目标检测过程简化成一个具有统一性的端到端回归问题,而且只需将图片处理一次,就能同时得到目标的位置和类别信息。与基于区域提取的两阶段(two stage)模型不同,单阶段方法通过完整的单次训练就能实现特征共享,准确率和速度都得到极大提升。这类算法的典型代表有YOLO、SSD等。
1.2.1 YOLO系列算法
(1)YOLO
2016年Redmon J等提出了一种新的目标检测算法YOLO(You Only Look Once)。与基于分类的目标检测算法利用分类器来执行检测不同,YOLO算法将目标检测框架看作空间上的回归问题,单个神经网络可经过一次运算从完整图像上得到边界框和类别概率的预测,有利于对检测性能进行端到端的优化。YOLO算法以图像的全局信息进行预测,整体结构简单,其检测系统如图5所示,首先调整图像大小,然后将图像输入单个卷积网络中,并由模型的置信度对所得到的检测结果进行阈值处理。YOLO算法将检测视为回归问题,不需要复杂的流程,因此检测速度较快,基础网络运行速度可达到每秒45帧;其次,YOLO算法在进行图像检测时,会根据图像语义进行全局预测,背景误检率较低。但是YOLO算法仍存在定位精度、召回率等较低的问题,且对距离很近的物体和很小的物体检测效果不好,泛化能力相对较弱。

图5 YOLO检测系统
(2)YOLO9000
针对YOLO算法召回率和定位精度低的缺点,2016年Redmon J等引入了一个先进的实时目标检测系统YOLO9000,该系统可以检测超过9000个目标类别。该部分工作首先对YOLO检测方法进行改进,改进后的模型YOLOv2在PASCAL VOC和COCO等标准检测数据集上获得了显著的效果。在67FPS时,YOLOv2在VOC 2007上的mAP为76.8,在40FPS时mAP 为78.6,比使用ResNet网络的Faster R-CNN和SSD等方法表现更出色,同时运行速度更快;其次提出了一种目标检测与分类的联合训练方法,使用该方法在COCO检测数据集和ImageNet分类数据集上同时训练YOLO9000,允许YOLO9000预测未经过标注的数据目标类别。YOLO9000在ImageNet检测验证集上获得的mAP 为19.7,在COCO数据集的156个类别上获得的mAP 为16.0。
(3)YOLOv3
YOLOv3对YOLO9000进行了改进,采用的模型比YOLO9000更大,进一步提高了检测准确率,但速度比YOLO9000稍慢。其具体改进有:增加对候选框是否包含物体的判断,降低检测误差;使用二分类器进行分类,每个候选框可以预测多个分类;增加多尺度预测方法,小物体的检测效果比YOLO9000有所提升;提出新的基础网络darknet-53,该网络在ImageNet数据集上对256 256的Top-5分类准确率为93.5,与ResNet-152相同,Top-1准确率为77.2%,只比ResNet-152低0.4%。与此同时,darknet-53的计算复杂度仅为ResNet-152的75%, 实际检测速度(FPS)是ResNet-152的2倍。
1.2.2 SSD
为解决YOLO系列算法在定位上精度不足的问题,2016年Liu W等提出SSD(Single Shot MultiBox Detector)算法,将单个深度神经网络应用到图像目标检测中。SSD算法框架如图6所示,其定位边界框定义为一组在空间上离散的默认框,且对应于不同的长宽比与映射位置。在进行预测时,网络会为每个默认框中的目标类别生成对应的概率分数,并调整默认框以实现与目标形状的良好匹配。除此以外,网络还对具有不同分辨率的目标结合其多个特征映射作出完整预测,实现对多尺寸目标的检测任务。SSD算法简单高效,消除了区域提取以及对像素或特征的下采样阶段,并将所有计算封装到单个网络中,容易进行训练以及集成。但是SSD具有以下问题:小目标对应于特征图中很小的区域,无法得到充分训练,因此SSD对于小目标的检测效果依然不理想;无候选区域时,区域回归难度较大,容易出现较难收敛的问题;SSD不同层的特征图都作为分类网络的独立输入,导致同一个物体被不同大小的框同时检测,造成了重复运算。
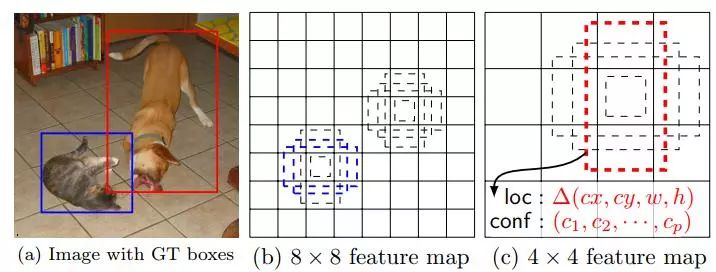
图6 SSD算法
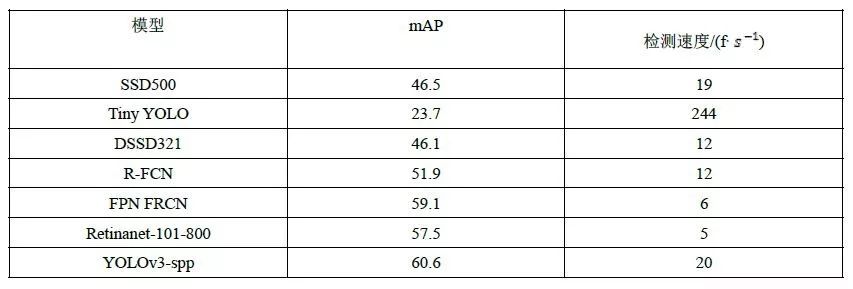
基于深度学习的目标检测算法在VOC2007和COCO数据集上的检测性能如表1、表2所示:
表1 目标检测算法在VOC2007数据集上的检测性能
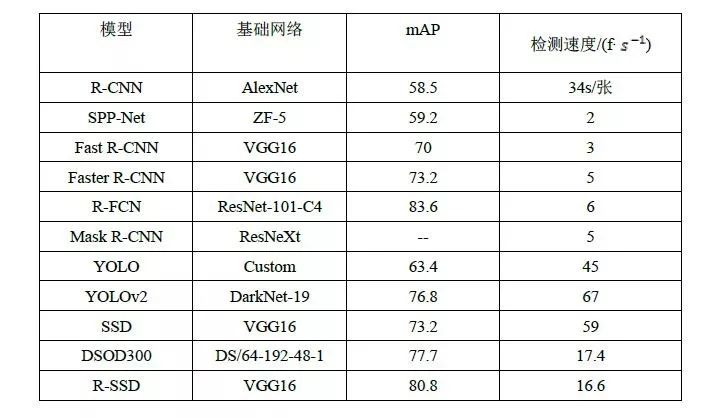
表2 目标检测算法在COCO数据集上的检测性能
02 小目标检测研究进展
小目标检测任务在民用、军事、安防等各个领域具有十分重要的作用,具体应用场景如无人机对地面车辆、行人等目标的检测,智能化导弹对地面目标的检测和追踪,遥感图像地物目标的检测等等。根据应用背景,小目标尺寸的定义略有不同。Bell S等提出一种利用感兴趣区域内外信息进行物体检测的内外网(Inside-Outside Net,ION)结构,并将小目标定义为COCO 数据库中尺寸小于等于32×32像素的目标。Mäenpää T等解释了LBP算子与其他纹理分析方法的关系,并发布了一个小目标检测专用数据库,通过统计得出其小目标的定义为512×512的图像中尺寸大致为20×20像素的目标。小目标尺寸较小、分辨率低、特征不明显,在进行目标检测时需要专门的数据库和精度更高的算法。
2.1小目标检测数据集
一般来说小目标在图像视野中占比较小,边缘特征不明显甚至缺失,由于分辨率和信息有限,使得基于深度学习的小目标检测算法在常规目标检测数据集上的检测效果并不好,需要专门针对小目标特征的数据库,完成训练和检测任务。常用的小目标检测数据集有如下几个:
(1) DOTA
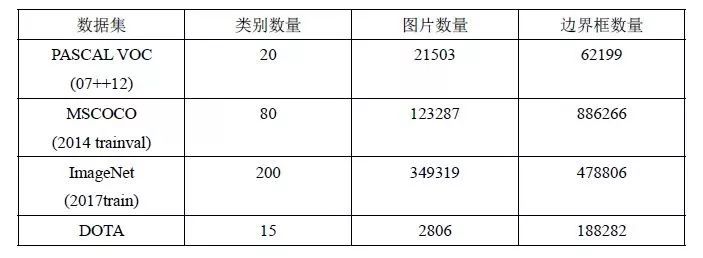
DOTA(A Large-scale Dataset for Object Detection in Aerial Images)是用于航拍图像中物体检测的大型数据集,它可用于训练和评估航拍图像中的小物体检测模型,包含来自不同传感器和平台的2806幅航拍图像,每张图像的尺寸在800×800到4000×4000像素范围内,并且包含各种尺度、方向和形状的目标,这些图像由航空图像解释专家使用15个常见对象类别进行标注,完全标记的DOTA图像包含约188282个实例。相关数据集对比如表3所示:
表3 相关数据集对比
(2) VEDAI
VEDAI(Vehicle Detection in Aerial Imagery)数据集提供了一个新的航空影像数据库,作为在无约束环境中对自动目标识别算法进行基准测试的工具。该数据库中的车辆目标除了尺寸较小外,还表现出不同的变化,例如多重方向,光照变化,镜面反射或遮挡等,此外,每个图像都提供多种光谱带和分辨率,同时还给出了精确的实验方案。其具体目标如表4所示:
表4 VEDAI数据集目标类别
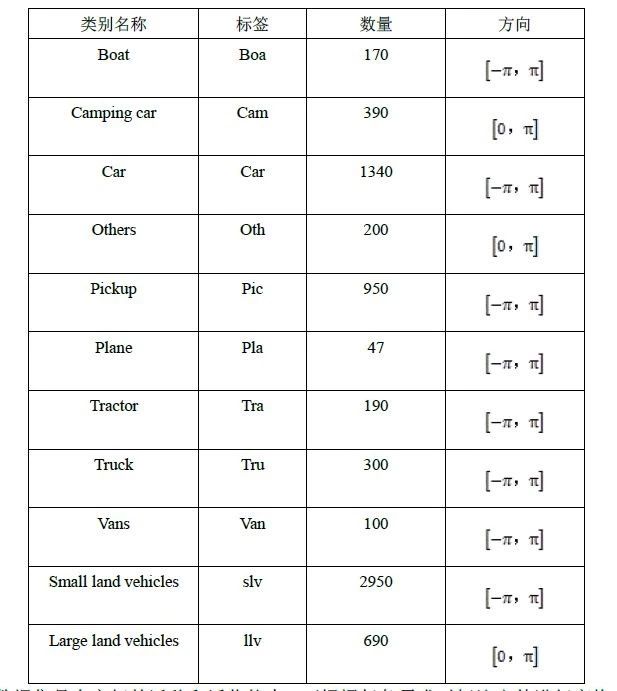
VEDAI数据集具有良好的迁移和泛化能力,可根据任务需求对标注文件进行变换。中国科学院大学李大伟等将标注四边形坐标转换为矩形框的左上坐标以及矩形框的宽度和长度,用于固定翼无人机地面车辆小目标检测算法的验证和横向比较,并取得了良好效果。
(3)其他
RSOD-Dataset数据集是用于遥感图像中物体检测的开放数据集,该数据集包括四个文件,对应于飞机、油箱、游乐场和立交桥四类目标,采用PASCAL VOC的数据集格式。UCAS-AOD数据集由中科大模式识别实验室标注,包含汽车、飞机,以及背景负样本,其样本数量如表5所示:
表5 UCAS-AOD数据集目标类别

2.2小目标检测算法
多尺度目标检测,特别是小目标检测在计算机视觉中是一项具有挑战性的任务。当前旨在处理这个问题的方法大致有两个分支,一个典型的分支是设计多尺度神经网络提取不同水平的特征,以适应不同大小的物体检测任务,另一种流行的方法是使用反卷积扩大深度特征图。这些方法消除了物体尺度变化的问题,但仍然不能很好地检测小物体。针对小目标检测问题,近几年国内外开展了许多研究,提出了一些效果显著的改进算法。
2015年Razakarivony S等提出了VEDAI航拍车辆小目标数据库,比较了几种目标检测算法,发现大多数算法对小目标检测的效果都不尽如人意,小目标检测仍然是计算机视觉亟待克服的难题之一。2016年Takeki A等针对大背景区域下小目标检测问题提出一种基于深度卷积神经网络在大范围视场区域内检测鸟类小型目标的模型,该方法将基于深度学习的目标检测算法与语义分割方法相结合,训练一个深度全卷积神经网络(FCN)和FCN的变体,并通过支持向量机将它们的结果集成到一起,从而实现高检测性能。Kampffmeyer M等提出一种基于像素级、块区域及两者相结合的深度卷积神经网络架构来实现航拍图像中单像素的分类,建立土地覆盖图以实现小目标检测。Mundhenk T N等提出一种基于逐像素提取区域特征的方法,将区域特征通过卷积神经网络进行分类检测,然而这种逐像素搜索的方法效率太低,而且对目标没有尺度适应能力。
2017年Lin T Y等在Faster R-CNN网络基础上提出一种具有横向连接的特征金字塔网络(Feature Pyramid Networks,FPN),利用多尺度特征和自上而下的结构实现目标检测目的。FPN算法解决了只用网络顶层特征进行检测,虽然语义信息比较丰富,但是经过层层池化等操作,特征细节信息丢失太多的问题,而对于小目标检测来说这些信息往往是比较重要的。FPN算法提出将语义信息充分的顶层特征映射到分辨率较大、细节信息较多的底层特征中,将二者以合适的方式进行融合来提升小目标的检测效果。Fu C Y等针对SSD算法在小目标检测上存在的问题提出一种改进的DSSD(Deconvolutional Single Shot Detector)算法,将SSD算法基础网络从VGG-16更改为ResNet-101,增强网络特征提取能力,其次参考FPN算法思路,利用去卷积结构将图像深层特征从高维空间传递出来,与底层信息融合,同时联系不同层级之间的图像语义关系,设计预测模块结构,通过融合不同层级之间的特征输出,预测物体类别信息。该算法在VOC2007数据集上达到了81.5%mAP的测试结果。Ren J等提出RRC(Recurrent Rolling Convolution)结构,改进了SSD算法对被遮挡物体或小物体的检测效果。
2018年Ren Y等修正了Faster R-CNN算法来完成光学遥感图像中小物体检测的任务。首先通过设置适当的锚窗改进了RPN算法,同时采用了一种横向连接、自上而下的结构获得具有较高分辨率的特征层;其次结合上下文语义进一步提高小型遥感对象检测性能,同时应用简单的采样策略来解决不同类别之间图像数量不平衡的问题;最后在训练过程中引入了一种简单而有效的数据增强方法,称为“随机旋转”。改进后的Faster R-CNN算法在检测小型遥感物体时平均精度明显提高。Yi K等提出一个名为KB-RANN的大脑启发网络用于准确的交通标志检测(TSD)任务。TSD作为援助系统和自动驾驶领域顶层驱动程序的基础,是一个典型的小目标检测任务。该方法使用了循环神经网络以提高检测精度,结合领域特定知识和直觉知识来提高效率,并且已经成功应用到自动驾驶汽车的嵌入式系统上。Redmon J等提出的YOLOv3对YOLO9000进行了改进,增加多尺度预测方法,小物体的检测效果比YOLO9000有所提升。
检测任务的多样化以及检测背景的复杂化使得小目标检测算法在语义分析、样本挖掘等方面面临诸多问题,提升检测精度和速度,以及获得二者的平衡,成为小目标检测改进的方向和面临的挑战。
03 总结与展望
自2012年以来,卷积神经网络算法在计算机视觉领域的突出表现带动了深度学习研究的热潮,基于深度学习的目标检测算法代替了基于特征的传统检测方法,并呈现出迅猛的发展态势。数十年间,经过不断地算法改进和网络结构完善,检测精度和速度大幅提升,并逐步应用到民用、军用等各个领域。
以卷积神经网络为基础的目标检测经典算法经过不断地算法改进和网络结构完善,检测精度和速度大幅提升,其中基于分类的两阶段目标检测算法在分类准确度及定位精度方面优于基于回归的单阶段目标检测算法,成为目标检测领域研究和改进的重点,但两阶段算法在计算速度上的限制使其无法满足实时性的场景需求,单阶段检测模型则将整张图片作为输入,同时进行分类和回归,实现了端到端的检测过程,计算速度明显提高。随着未来应用场景的广泛化、复杂化,目标检测对象也将不断扩展,小目标作为应用场景中的一个重要对象,由于分辨率较低、信息有限,始终是目标检测领域富有挑战性的难题,现阶段针对小目标的检测算法大都在目标检测经典算法框架上进行优化和改进,提升检测精度和速度,以及获得二者的平衡,成为小目标检测改进的方向和研究的重点。
04 结束语
本文系统性地总结了深度学习算法在目标检测领域的研究进展,并分析了各种算法存在的问题和做出的改进,重点关注了近几年国内外在小目标检测问题上的改进算法,就目前来说,小目标检测问题仍不存在最好的算法,未来多尺度目标检测、复杂场景下的目标检测、特定任务剖面下的目标检测、小物体数据集标注以及数据量不足等问题都将是目标检测领域需要深人研究的课题。
引用格式:刘晓楠,王正平,贺云涛,等. 基于深度学习的小目标检测研究综述[J]. 战术导弹技术, 2019,(1): 100-107.
本文选自《战术导弹技术》2019年第1期
作者:刘晓楠,王正平,贺云涛,刘倩
声明:本文来自战术导弹技术,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
