
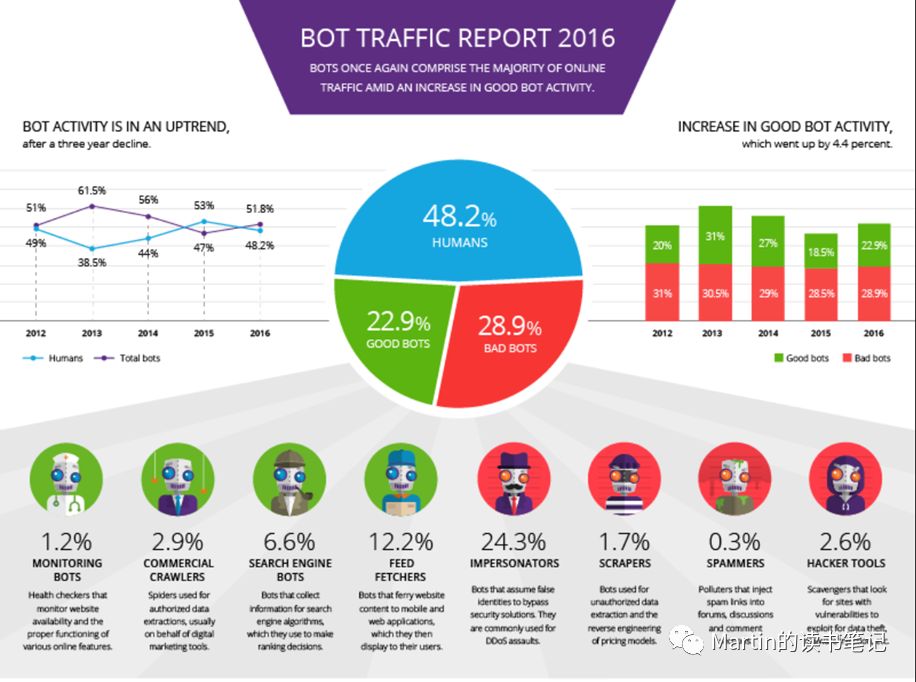
利用现代化技术在网上自动抓取数据,不仅仅是一种新兴的数据收集手段,更是一种生产手段、研究手段,甚至已经成为当前互联网访问的重要组成部分。根据Imperva发布的bot traffic report 2016,超过一半以上的互联网访问是由自动bot产生的,这意味着接近每20次互联网访问中,就有一次是爬虫。
爬虫技术在互联网中广泛应用也引起了诸多问题。例如,竞争对手为了充分了解其他从业者的经营情况,服务于自己的商业决策,会对竞品网站进行爬虫。这类案子在美国已经发生了不少,今天就选择了几个典型的案子,从法官如何解释文本的角度,简单介绍下美国法官是如何处理这类问题的,以及我的一些思考和疑问。
美国法院在应对爬虫相关问题涉及的法律渊源包括:合同法、著作权法、CFAA、侵权法、隐私法。这需要具体看爬取的数据类型和爬取方式予以区分,例如爬取的数据属于有版权的书籍、视频,那么著作权法的权重会大一些,如果爬取的是社交网络的非公开信息,可能隐私法的权重会大一些。
其中CFAA是最重要的法律依据了,其中CFAA的1030(a)(5)(A)(2008)这条,是被援引最多的条款,那我们来看看这一条规定了什么?
•《1986年计算机欺诈与滥用法》ComputerFraud and Abuse Act of 1986(CFAA)
intentionally accessed a computer without authorization or exceeded authorized access,and thereby obtained…information from any protected computer;” or that the defendant “knowingly caused the transmission of aprogram…and…caused damage without authorization to a protected computer. 18U.S.C. §§ 1030(a)(2)(C), 1030(a)(5)(A) (2008).
•未经授权故意访问计算机或超过授权访问权限,从而从任何受保护的计算机获取信息;或者被告“故意造成程序传输,并且对未经授权且受保护的计算机造成损害”
怎么理解“未经授权”、“超过授权访问权限”,以及“受保护的计算机”,成为法官是否能通过CFAA对爬虫行为追责的重要依据。by the way,CFAA不仅规定了民事责任,还有刑事责任。
如果从字面上去理解,“未经授权”最plainly的意思就是在访问时候没有获得权限。那么网站就可以通过在事前,发表明确声明来表示禁止爬虫行为。我大致梳理了下(并不代表美国司法界对这种分类方法认同),这类事前声明可以被分为两类:明示的or暗示的
明示的“未经授权”包括与员工签署的保密协议、网页上的告知、警告、弹窗、最终用户协议、产品或服务备注的说明、解释等。
暗示的“未经授权”包括密码认证,例如在登陆某个网站的时候需要输入密码,这就在暗示用户需要得到通过密码来获取访问权限,如果绕开了认证予以暴力访问,那么可以被推定为“未经授权”。

OK,说一千道一万,不如来看案子。
1、EFCultural Travel BV v. ZeferCorp., 318 F.3d 58, 62 (1st Cir. 2003)
EF是一家主打学生旅游市场的公司,几位EF员工签了保密协议后离职,另起炉灶,然后利用之前在公司工作期间知晓的价格代码(These codes were used to direct the scraper tool to the specific pages on EF’s website that contained EF’s pricing information),加之开发的爬虫软件,对EF公司的网站进行爬虫,找到公众访问者无法搜到的低价,然后依据该价格参与竞争。最后EF就告到法院。法院认为If EF wants to ban scrapers, let it say so on the webpage or a link clearly marked as containing restrictions。也就是说所谓的CFAA的“未经授权”,可以通过网站发表“限制访问”的明确声明,予以确立。并且这几位离职员工的离职保密协议中也有相关规定,最后也被法院一并援引用来支撑判决。
2、SouthwestAirlines Co. v. Farechase,Inc., 318 F. Supp.2d 435, 439–440 (N.D. Tex. Mar. 19, 2004)
Farechase公司开发了一个爬虫软件,对西南航空公司的网站进行爬虫。西南航空在其网站的每一页都明确禁止了爬虫("repeated warnings and requests to stop scraping,")。那么该声明被法院确立为“未经授权”的行为,援引了CFAA予以处罚。
3、CollegeSource,Inc. v. AcademyOne,Inc., 597 Fed.Appx.116, 130 (3d Cir. 2015)
CollegeSource是一家专注于做美国大学生转校咨询的公司,同时也提供很多在线大学课程,Acdaemy One经营类似业务。因为竞争,A1公司也想收集并建立自己的学习资源库给用户使用,所以雇佣了一个中国承包商,写了一个爬虫的脚本,对ColledgeSource公司网站的资源进行爬虫,共收集了超过18000份pdf文档。在这些pdf文档的第二页,都有一个明确的条款说明:禁止在任何未经同意的情况下,进行重新分发、修改或商业使用。2007年4月,CollegeSource公司就给A1公司发了一封禁令信,要求其停止爬虫。法院认定“违反任何技术壁垒或合同使用条款”,都可以被解释为“未经授权”。也就是说如果网站页面上没有说明,但是提供的相关产品or服务里有相关明确说明,一样可以被认定。
4、EarthCam,Inc. v. OxBlueCorp., 703 Fed.Appx.803, 808 (11th Cir. 2017)
这个案子有点趣。EC和OxBlue都是经营影像器材和解决方案的公司。EC的一个用户将自己账户密码给了OxBlue公司,希望经营类似业务的OxBlue能帮忙解决一些技术问题。后者登录了该账户密码,并对EC社群论坛上的大量图片等其他信息进行抓去。EC控诉至法院。
法官最后还是支持了EC,但是理由很有意思:虽然CFAA并没有明确规定用户不得与他人共享账户信息,甚至用户都可以把账户密码在网上公开都是ok的,但是EC网站上明确声明如果用户将账户信息给他人使用,违反了其”使用条款“。法官认为,这属于CFAA认定的”超出权限“——网站只授权给当事人使用,其他人用当然超出了权限。也就是说,如果违反了有关涉案计算机的任何政策或使用条款(EULA),可以被认定为“超出了授权访问权限”。
5、Cvent,Inc. v. Eventbrite, Inc., 739 F.Supp.2d 927 (2010) (UnitedStates District Court, E.D. Virginia)
这个案子属于某种例外情形。该公司的使用条款,被放在网页的最下面,并且和一堆其他网站的链接混在一起。很难被用户看到。所以法官要求“使用条款”必须显而易见,否则不对爬虫者有效。
小结一:如果网站有明确的声明、告知、警告、弹窗禁止爬虫、或者违反员工保密协议、合同、产品或服务中的备注说明解释、最终用户协议,都可能被法院认定为CFAA规定的“未经授权”或“超出授权”的行为,依此可以予以确立刑事、民事责任。
那么什么是“事后措施”?让我们看两个案例:
6、CraigslistInc. v. 3Taps Inc., 942 F. Supp. 2d 962 (N.D. Cal. 2013)
Craiglist是一个风格迥异的分类信息网站,类似于国内早期的58同城。3Taps就从CL上进行爬虫,然后再自己网站上做聚合展示。CL就向3taps发了律师禁令信(cease-and-desistletter)并且屏蔽了3taps公司的IP来限制其访问CL,要求停止行为。但是3Taps也采用技术手段绕开了屏蔽继续爬。CL就说,那好吧,法庭见。
虽然CL网站上的使用条款有明确声明禁止爬虫,但法官并不认同该声明可以触发CFAA监管。但法官认可了CL的事后采取的函告声明行为和技术手段,认定为“未经授权”的访问行为,触发CFAA。
7、Facebook,Inc. v. Power Ventures, Inc. et al., 844 F.3d 1058 (9th Cir. 2016).
该案与CL v. 3Taps案类似。第九巡回法院维持原判,在有明确函告和技术手段的情况下,构成“未经授权”。
小结二:部分法院认为,仅凭“使用条款”无法被解释为CFAA规定的“未经授权”或“超出授权”的行为,但事后的函告或技术性手段,依旧可以被认定为“未经授权”或“超出授权”行为的依据。
虽然事前的声明来触发CFAA已经开始被部分法院抛弃,不过事后的声明和技术手段开始被法官予以认可。但是,依靠网站的单方声明来决定是否触发CFAA越来越暴露出它的问题。到了2017年的hiQLabs, Inc. v. LinkedIn Corp案,事情有了彻底转变的可能....

8、hiQLabs, Inc. v. LinkedIn Corp., 273 F. Supp.3d 1099 (N.D. Cal. 2017)
这个案子的事实部分想必大家都烂熟于心了,我就不赘述了。
为什么说hiQ这个案子重要呢?我觉得意义有三:
a.这是加州法院第一次正面回应爬取“公开”信息的法律问题。法院认为爬虫公开信息不构成CFAA意义上的“未经授权”或“超出授权”行为,因为公开信息不同于CFAA法条中阐明的“anyprotected computer”,其缺少相应的保护措施,例如密码。大家来看看法官怎么说的:
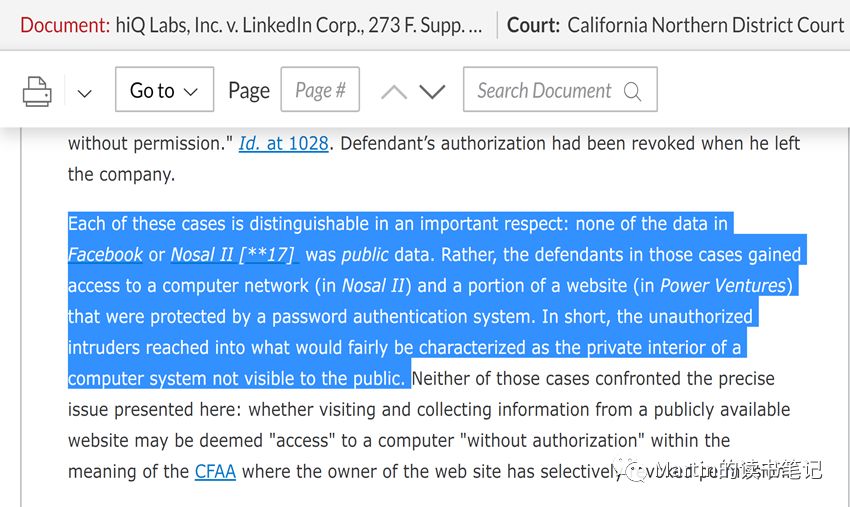
b.第一次援引了反不正当竞争法(California’sUnfair Competition Law,UCL)作为支持爬虫方的判决依据。认定领英公司传导了其在职场社交领域的竞争优势到职场数据分析领域,该侵害不可修复。该理由成为法院发布临时禁令最直接的原由。
c.援引了加州宪法言论自由条款作为依据。认为“使用条款”给予了网站所有者过大的权力。看看法官怎么说:

此外,且仅凭“使用条款”不得触发CFAA。前面已经说过,CFAA最高可以判处刑事责任,想想如果仅凭网站单方的一个声明用来确定刑事责任,会是多么不么不稳定的情形(按照大陆法系的理解,刑法的谦抑性和罪责刑相适应就很难做到)
小结三:近期的判决可能标志着CFAA法案下对网络爬虫行为责任认定的转变。对于网站所有者来说,如果爬取的是公开信息,那么通过事前的“使用条款”,事后的禁令通知、实施IP封锁技术都可能不再有效。此外,对爬虫提起诉讼可能还会让网站所有者面对来自反不正当竞争法规以及宪法第一修正案方面的挑战。有关公开信息爬虫的判决正在慢慢突破合同法思维和CFAA的限制,开始更多的考量公共利益的优先性。
虽然案子已经打到了第九巡回法院待审,最后效力有待进一步观察,但它的影响力已经开始产生。例如2018年的TicketmasterL.L.C. v. Prestige Entertainment, Inc. et al., No. 17-cv-07232, 2018 WL 654410(C.D. Cal. Jan. 31, 2018). 法院否定了在仅有函告的情况下,不够触发CFAA。算是对hiQ案的一个回应。


hiq v. linkedin案被上诉至9th circuit在某404视频网站上有响应的录播,感兴趣的同学可以去观摩下。
不知道大家有没有注意到:这几个案子里,法官和律师们似乎都回避了数据归属问题。这种现象不仅存在于企业间爬虫纠纷的案例中,在行业准入、数据交易等判决中,美国法官似乎也不愿过分纠结数据的归属问题。例如Sorrellv. IMS Health Inc., 564 U.S. 552和FTCv. Toysmart.com案中,数据挖掘、处理、分析过程中的权属问题也并非案件的争议点。这和我国多起企业间数据纠纷中,有部分企业主张:“数据归属于用户”的落脚点非常不一样。
疑问:对数据的法律权属进行界定,是不是解决数据纠纷不可绕过的法律问题?或者说,在什么情况下,对数据的产权予以明确是必要且可行的?
参考文献:
1.https://www.incapsula.com/blog/bot-traffic-report-2016.html2.
2.https://www.businessinsider.com/hedge-funds-watching-linkedin-lawsuit-on-web-scraped-data-2019-3
相关判决书原文:
链接:https://pan.baidu.com/s/1ynyQN_00T5tT-MHMRq8CTw
提取码:xmfo
声明:本文来自Martin的读书笔记,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
